 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
HiPhO: How Far Are (M)LLMs from Humans in the Latest High School Physics Olympiad Benchmark?
Sep 10, 2025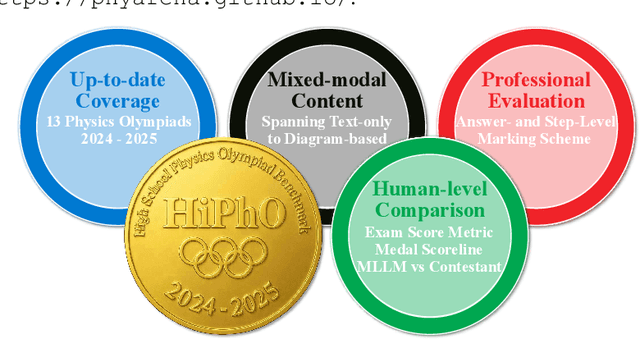

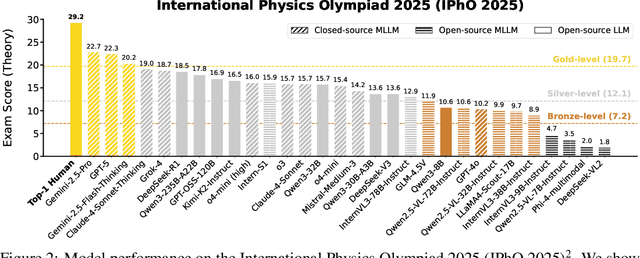

Recently, the physical capabilities of (M)LLMs have garnered increasing attention. However, existing benchmarks for physics suffer from two major gaps: they neither provide systematic and up-to-date coverage of real-world physics competitions such as physics Olympiads, nor enable direct performance comparison with humans. To bridge these gaps, we present HiPhO, the first benchmark dedicated to high school physics Olympiads with human-aligned evaluation. Specifically, HiPhO highlights three key innovations. (1) Comprehensive Data: It compiles 13 latest Olympiad exams from 2024-2025, spanning both international and regional competitions, and covering mixed modalities that encompass problems spanning text-only to diagram-based. (2) Professional Evaluation: We adopt official marking schemes to perform fine-grained grading at both the answer and step level, fully aligned with human examiners to ensure high-quality and domain-specific evaluation. (3) Comparison with Human Contestants: We assign gold, silver, and bronze medals to models based on official medal thresholds, thereby enabling direct comparison between (M)LLMs and human contestants. Our large-scale evaluation of 30 state-of-the-art (M)LLMs shows that: across 13 exams, open-source MLLMs mostly remain at or below the bronze level; open-source LLMs show promising progress with occasional golds; closed-source reasoning MLLMs can achieve 6 to 12 gold medals; and most models still have a significant gap from full marks. These results highlight a substantial performance gap between open-source models and top students, the strong physical reasoning capabilities of closed-source reasoning models, and the fact that there is still significant room for improvement. HiPhO, as a rigorous, human-aligned, and Olympiad-focused benchmark for advancing multimodal physical reasoning, is open-source and available at https://github.com/SciYu/HiPhO.
Mitigating Behavioral Hallucination in Multimodal Large Language Models for Sequential Images
Jun 08, 2025
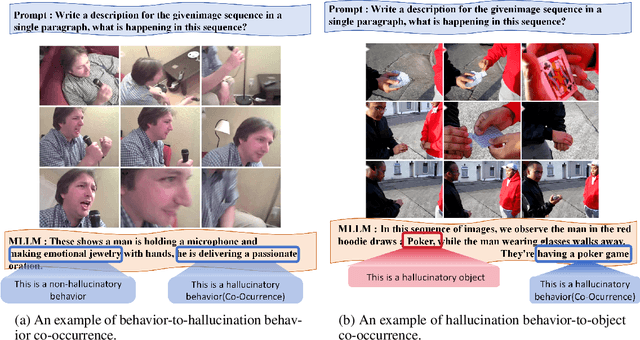
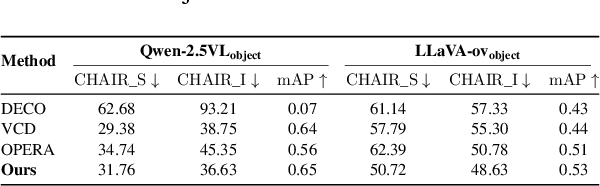
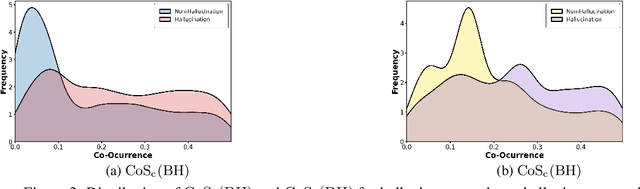
While multimodal large language models excel at various tasks, they still suffer from hallucinations, which limit their reliability and scalability for broader domain applications. To address this issue, recent research mainly focuses on objective hallucination. However, for sequential images, besides objective hallucination, there is also behavioral hallucination, which is less studied. This work aims to fill in the gap. We first reveal that behavioral hallucinations mainly arise from two key factors: prior-driven bias and the snowball effect. Based on these observations, we introduce SHE (Sequence Hallucination Eradication), a lightweight, two-stage framework that (1) detects hallucinations via visual-textual alignment check using our proposed adaptive temporal window and (2) mitigates them via orthogonal projection onto the joint embedding space. We also propose a new metric (BEACH) to quantify behavioral hallucination severity. Empirical results on standard benchmarks demonstrate that SHE reduces behavioral hallucination by over 10% on BEACH while maintaining descriptive accuracy.
Understanding the Repeat Curse in Large Language Models from a Feature Perspective
Apr 19, 2025Large language models (LLMs) have made remarkable progress in various domains, yet they often suffer from repetitive text generation, a phenomenon we refer to as the "Repeat Curse". While previous studies have proposed decoding strategies to mitigate repetition, the underlying mechanism behind this issue remains insufficiently explored. In this work, we investigate the root causes of repetition in LLMs through the lens of mechanistic interpretability. Inspired by recent advances in Sparse Autoencoders (SAEs), which enable monosemantic feature extraction, we propose a novel approach, "Duplicatus Charm", to induce and analyze the Repeat Curse. Our method systematically identifies "Repetition Features" -the key model activations responsible for generating repetitive outputs. First, we locate the layers most involved in repetition through logit analysis. Next, we extract and stimulate relevant features using SAE-based activation manipulation. To validate our approach, we construct a repetition dataset covering token and paragraph level repetitions and introduce an evaluation pipeline to quantify the influence of identified repetition features. Furthermore, by deactivating these features, we have effectively mitigated the Repeat Curse.
Fraud-R1 : A Multi-Round Benchmark for Assessing the Robustness of LLM Against Augmented Fraud and Phishing Inducements
Feb 18, 2025We introduce Fraud-R1, a benchmark designed to evaluate LLMs' ability to defend against internet fraud and phishing in dynamic, real-world scenarios. Fraud-R1 comprises 8,564 fraud cases sourced from phishing scams, fake job postings, social media, and news, categorized into 5 major fraud types. Unlike previous benchmarks, Fraud-R1 introduces a multi-round evaluation pipeline to assess LLMs' resistance to fraud at different stages, including credibility building, urgency creation, and emotional manipulation. Furthermore, we evaluate 15 LLMs under two settings: 1. Helpful-Assistant, where the LLM provides general decision-making assistance, and 2. Role-play, where the model assumes a specific persona, widely used in real-world agent-based interactions. Our evaluation reveals the significant challenges in defending against fraud and phishing inducement, especially in role-play settings and fake job postings. Additionally, we observe a substantial performance gap between Chinese and English, underscoring the need for improved multilingual fraud detection capabilities.