 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating CoT Monitorability in Large Reasoning Models
Nov 13, 2025



Large Reasoning Models (LRMs) have demonstrated remarkable performance on complex tasks by engaging in extended reasoning before producing final answers. Beyond improving abilities, these detailed reasoning traces also create a new opportunity for AI safety, CoT Monitorability: monitoring potential model misbehavior, such as the use of shortcuts or sycophancy, through their chain-of-thought (CoT) during decision-making. However, two key fundamental challenges arise when attempting to build more effective monitors through CoT analysis. First, as prior research on CoT faithfulness has pointed out, models do not always truthfully represent their internal decision-making in the generated reasoning. Second, monitors themselves may be either overly sensitive or insufficiently sensitive, and can potentially be deceived by models' long, elaborate reasoning traces. In this paper, we present the first systematic investigation of the challenges and potential of CoT monitorability. Motivated by two fundamental challenges we mentioned before, we structure our study around two central perspectives: (i) verbalization: to what extent do LRMs faithfully verbalize the true factors guiding their decisions in the CoT, and (ii) monitor reliability: to what extent can misbehavior be reliably detected by a CoT-based monitor? Specifically, we provide empirical evidence and correlation analyses between verbalization quality, monitor reliability, and LLM performance across mathematical, scientific, and ethical domains. Then we further investigate how different CoT intervention methods, designed to improve reasoning efficiency or performance, will affect monitoring effectiveness. Finally, we propose MoME, a new paradigm in which LLMs monitor other models' misbehavior through their CoT and provide structured judgments along with supporting evidence.
Is Long-to-Short a Free Lunch? Investigating Inconsistency and Reasoning Efficiency in LRMs
Jun 24, 2025Large Reasoning Models (LRMs) have achieved remarkable performance on complex tasks by engaging in extended reasoning before producing final answers, yet this strength introduces the risk of overthinking, where excessive token generation occurs even for simple tasks. While recent work in efficient reasoning seeks to reduce reasoning length while preserving accuracy, it remains unclear whether such optimization is truly a free lunch. Drawing on the intuition that compressing reasoning may reduce the robustness of model responses and lead models to omit key reasoning steps, we investigate whether efficient reasoning strategies introduce behavioral inconsistencies. To systematically assess this, we introduce $ICBENCH$, a benchmark designed to measure inconsistency in LRMs across three dimensions: inconsistency across task settings (ITS), inconsistency between training objectives and learned behavior (TR-LB), and inconsistency between internal reasoning and self-explanations (IR-SE). Applying $ICBENCH$ to a range of open-source LRMs, we find that while larger models generally exhibit greater consistency than smaller ones, they all display widespread "scheming" behaviors, including self-disagreement, post-hoc rationalization, and the withholding of reasoning cues. Crucially, our results demonstrate that efficient reasoning strategies such as No-Thinking and Simple Token-Budget consistently increase all three defined types of inconsistency. These findings suggest that although efficient reasoning enhances token-level efficiency, further investigation is imperative to ascertain whether it concurrently introduces the risk of models evading effective supervision.
Guiding Variational Response Generator to Exploit Persona
Nov 06, 2019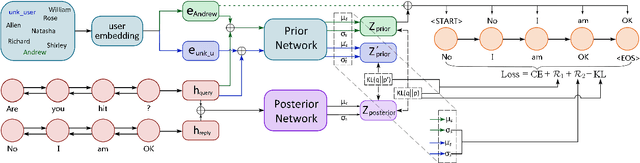
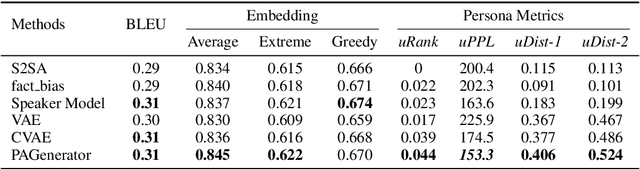
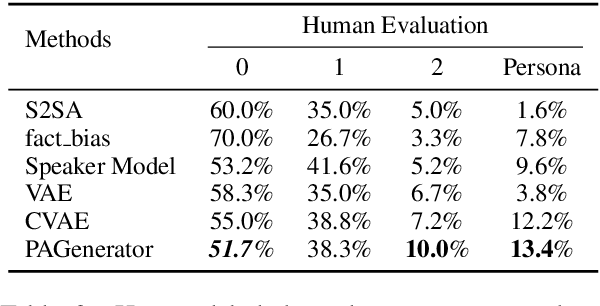

Leveraging persona information of users in Neural Response Generators (NRG) to perform personalized conversations has been considered as an attractive and important topic in the research of conversational agents over the past few years. Despite of the promising progresses achieved by recent studies in this field, persona information tends to be incorporated into neural networks in the form of user embeddings, with the expectation that the persona can be involved via the End-to-End learning. This paper proposes to adopt the personality-related characteristics of human conversations into variational response generators, by designing a specific conditional variational autoencoder based deep model with two new regularization terms employed to the loss function, so as to guide the optimization towards the direction of generating both persona-aware and relevant responses. Besides, to reasonably evaluate the performances of various persona modeling approaches, this paper further presents three direct persona-oriented metrics from different perspectives. The experimental results have shown that our proposed methodology can notably improve the performance of persona-aware response generation, and the metrics are reasonable to evaluate the results.
Convolutional Self-Attention Networks
Apr 05, 2019

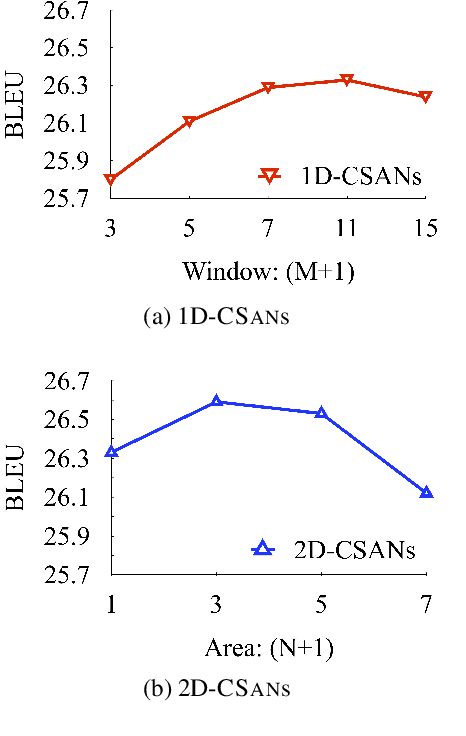
Self-attention networks (SANs) have drawn increasing interest due to their high parallelization in computation and flexibility in modeling dependencies. SANs can be further enhanced with multi-head attention by allowing the model to attend to information from different representation subspaces. In this work, we propose novel convolutional self-attention networks, which offer SANs the abilities to 1) strengthen dependencies among neighboring elements, and 2) model the interaction between features extracted by multiple attention heads. Experimental results of machine translation on different language pairs and model settings show that our approach outperforms both the strong Transformer baseline and other existing models on enhancing the locality of SANs. Comparing with prior studies, the proposed model is parameter free in terms of introducing no more parameters.
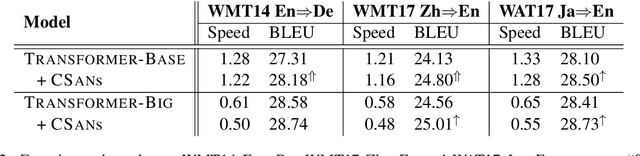
Context-Aware Self-Attention Networks
Feb 15, 2019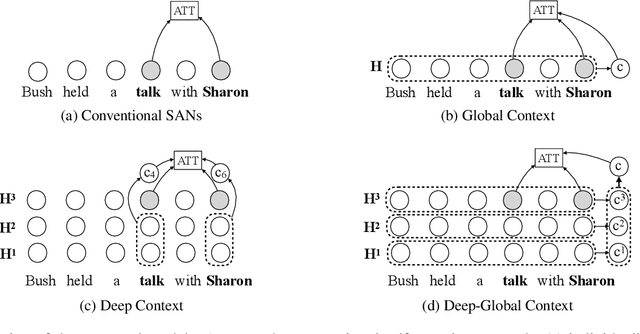

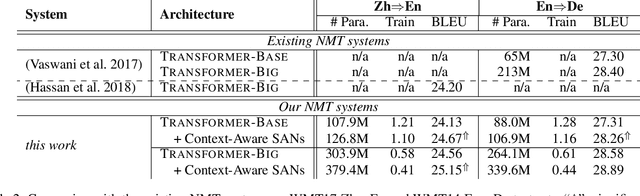
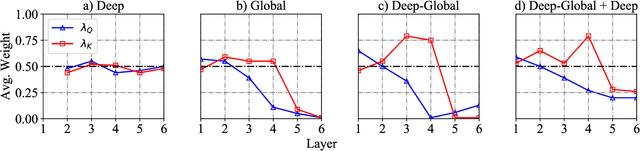
Self-attention model have shown its flexibility in parallel computation and the effectiveness on modeling both long- and short-term dependencies. However, it calculates the dependencies between representations without considering the contextual information, which have proven useful for modeling dependencies among neural representations in various natural language tasks. In this work, we focus on improving self-attention networks through capturing the richness of context. To maintain the simplicity and flexibility of the self-attention networks, we propose to contextualize the transformations of the query and key layers, which are used to calculates the relevance between elements. Specifically, we leverage the internal representations that embed both global and deep contexts, thus avoid relying on external resources. Experimental results on WMT14 English-German and WMT17 Chinese-English translation tasks demonstrate the effectiveness and universality of the proposed methods. Furthermore, we conducted extensive analyses to quantity how the context vectors participate in the self-attention model.