 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Self-Attention Networks
Paper and Code
Apr 05, 2019

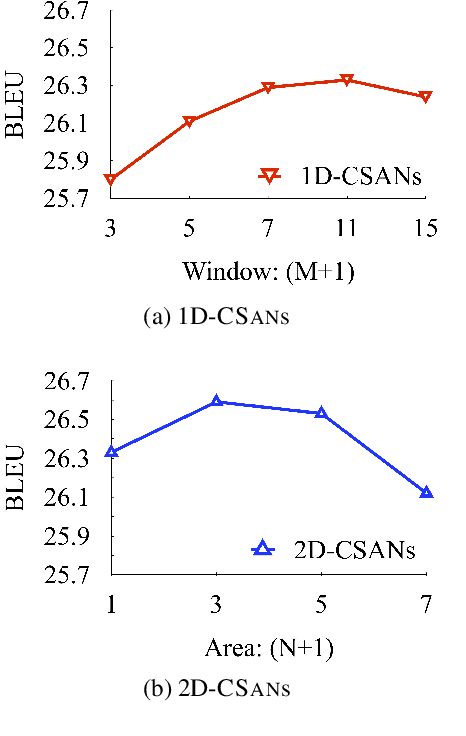
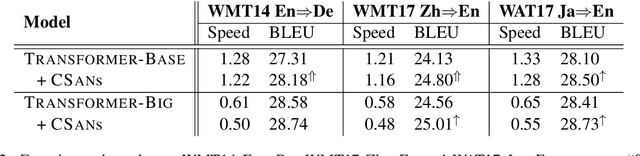
Self-attention networks (SANs) have drawn increasing interest due to their high parallelization in computation and flexibility in modeling dependencies. SANs can be further enhanced with multi-head attention by allowing the model to attend to information from different representation subspaces. In this work, we propose novel convolutional self-attention networks, which offer SANs the abilities to 1) strengthen dependencies among neighboring elements, and 2) model the interaction between features extracted by multiple attention heads. Experimental results of machine translation on different language pairs and model settings show that our approach outperforms both the strong Transformer baseline and other existing models on enhancing the locality of SANs. Comparing with prior studies, the proposed model is parameter free in terms of introducing no more parameters.