 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Self-Attention Networks
Paper and Code
Feb 15, 2019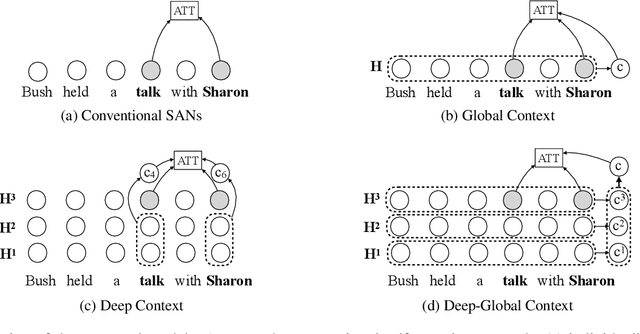

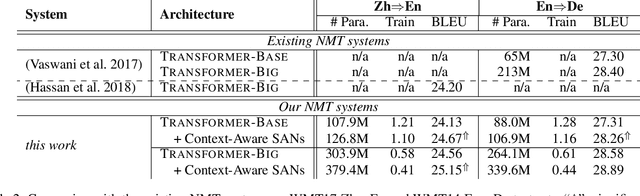
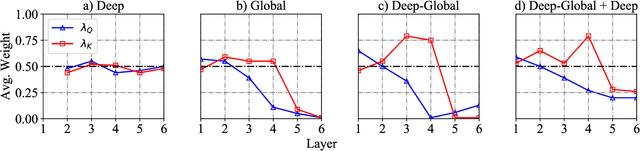
Self-attention model have shown its flexibility in parallel computation and the effectiveness on modeling both long- and short-term dependencies. However, it calculates the dependencies between representations without considering the contextual information, which have proven useful for modeling dependencies among neural representations in various natural language tasks. In this work, we focus on improving self-attention networks through capturing the richness of context. To maintain the simplicity and flexibility of the self-attention networks, we propose to contextualize the transformations of the query and key layers, which are used to calculates the relevance between elements. Specifically, we leverage the internal representations that embed both global and deep contexts, thus avoid relying on external resources. Experimental results on WMT14 English-German and WMT17 Chinese-English translation tasks demonstrate the effectiveness and universality of the proposed methods. Furthermore, we conducted extensive analyses to quantity how the context vectors participate in the self-attention model.