 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing a Model-based Policy Stationary Distribution to Stabilize Offline Reinforcement Learning
Paper and Code

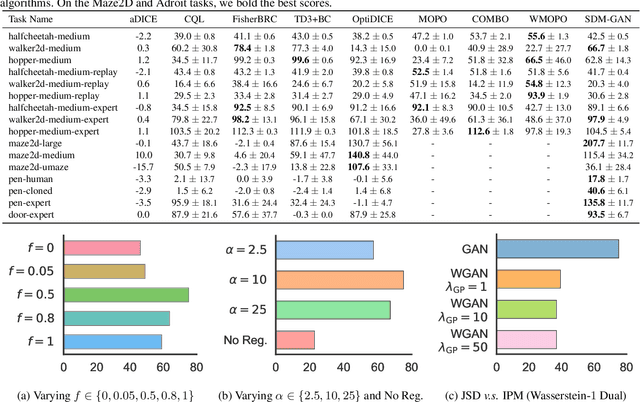
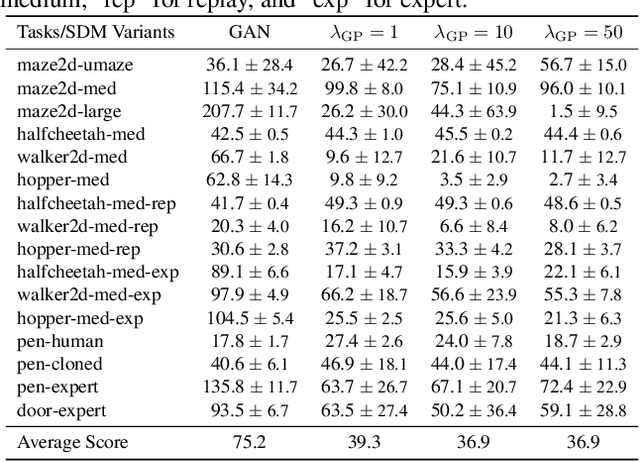
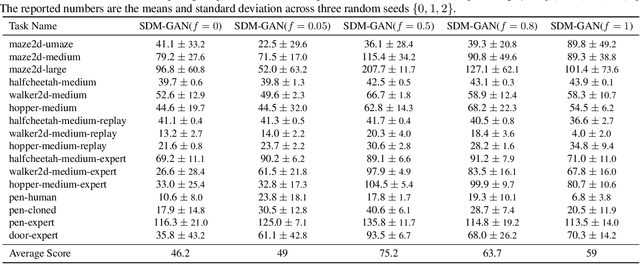
Offline reinforcement learning (RL) extends the paradigm of classical RL algorithms to purely learning from static datasets, without interacting with the underlying environment during the learning process. A key challenge of offline RL is the instability of policy training, caused by the mismatch between the distribution of the offline data and the undiscounted stationary state-action distribution of the learned policy. To avoid the detrimental impact of distribution mismatch, we regularize the undiscounted stationary distribution of the current policy towards the offline data during the policy optimization process. Further, we train a dynamics model to both implement this regularization and better estimate the stationary distribution of the current policy, reducing the error induced by distribution mismatch. On a wide range of continuous-control offline RL datasets, our method indicates competitive performance, which validates our algorithm. The code is publicly available.