 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Flawed Fictions: Evaluating Complex Reasoning in Language Models via Plot Hole Detection
Paper and Code

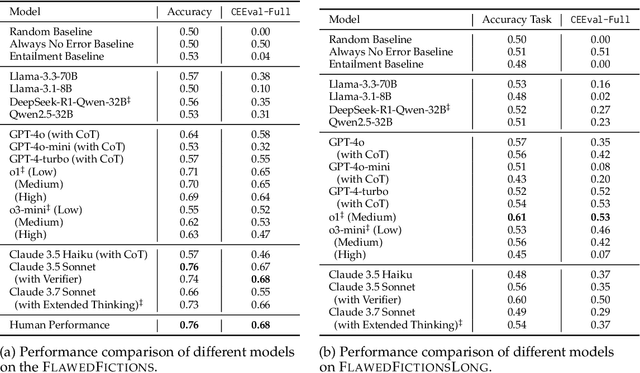

Stories are a fundamental aspect of human experience. Engaging deeply with stories and spotting plot holes -- inconsistencies in a storyline that break the internal logic or rules of a story's world -- requires nuanced reasoning skills, including tracking entities and events and their interplay, abstract thinking, pragmatic narrative understanding, commonsense and social reasoning, and theory of mind. As Large Language Models (LLMs) increasingly generate, interpret, and modify text, rigorously assessing their narrative consistency and deeper language understanding becomes critical. However, existing benchmarks focus mainly on surface-level comprehension. In this work, we propose plot hole detection in stories as a proxy to evaluate language understanding and reasoning in LLMs. We introduce FlawedFictionsMaker, a novel algorithm to controllably and carefully synthesize plot holes in human-written stories. Using this algorithm, we construct a benchmark to evaluate LLMs' plot hole detection abilities in stories -- FlawedFictions -- , which is robust to contamination, with human filtering ensuring high quality. We find that state-of-the-art LLMs struggle in accurately solving FlawedFictions regardless of the reasoning effort allowed, with performance significantly degrading as story length increases. Finally, we show that LLM-based story summarization and story generation are prone to introducing plot holes, with more than 50% and 100% increases in plot hole detection rates with respect to human-written originals.