 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Optimized to Fool Detectors Still Have a Distinct Style (And How to Change It)
May 20, 2025Despite considerable progress in the development of machine-text detectors, it has been suggested that the problem is inherently hard, and therefore, that stakeholders should proceed under the assumption that machine-generated text cannot be reliably detected as such. We examine a recent such claim by Nicks et al. (2024) regarding the ease with which language models can be optimized to degrade the performance of machine-text detectors, including detectors not specifically optimized against. We identify a feature space$\unicode{x2013}$the stylistic feature space$\unicode{x2013}$that is robust to such optimization, and show that it may be used to reliably detect samples from language models optimized to prevent detection. Furthermore, we show that even when models are explicitly optimized against stylistic detectors, detection performance remains surprisingly unaffected. We then seek to understand if stylistic detectors are inherently more robust. To study this question, we explore a new paraphrasing approach that simultaneously aims to close the gap between human writing and machine writing in stylistic feature space while avoiding detection using traditional features. We show that when only a single sample is available for detection, this attack is universally effective across all detectors considered, including those that use writing style. However, as the number of samples available for detection grows, the human and machine distributions become distinguishable. This observation encourages us to introduce AURA, a metric that estimates the overlap between human and machine-generated distributions by analyzing how detector performance improves as more samples become available. Overall, our findings underscore previous recommendations to avoid reliance on machine-text detection.
Are Paraphrases Generated by Large Language Models Invertible?
Oct 29, 2024Large language models can produce highly fluent paraphrases while retaining much of the original meaning. While this capability has a variety of helpful applications, it may also be abused by bad actors, for example to plagiarize content or to conceal their identity. This motivates us to consider the problem of paraphrase inversion: given a paraphrased document, attempt to recover the original text. To explore the feasibility of this task, we fine-tune paraphrase inversion models, both with and without additional author-specific context to help guide the inversion process. We explore two approaches to author-specific inversion: one using in-context examples of the target author's writing, and another using learned style representations that capture distinctive features of the author's style. We show that, when starting from paraphrased machine-generated text, we can recover significant portions of the document using a learned inversion model. When starting from human-written text, the variety of source writing styles poses a greater challenge for invertability. However, even when the original tokens can't be recovered, we find the inverted text is stylistically similar to the original, which significantly improves the performance of plagiarism detectors and authorship identification systems that rely on stylistic markers.
Few-Shot Detection of Machine-Generated Text using Style Representations
Jan 12, 2024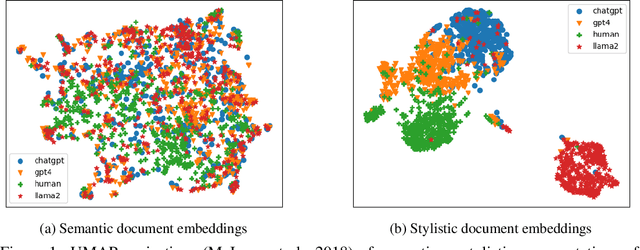
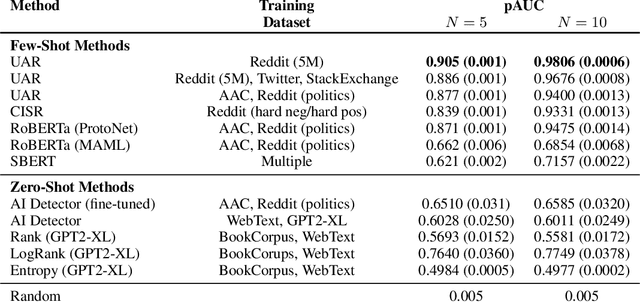
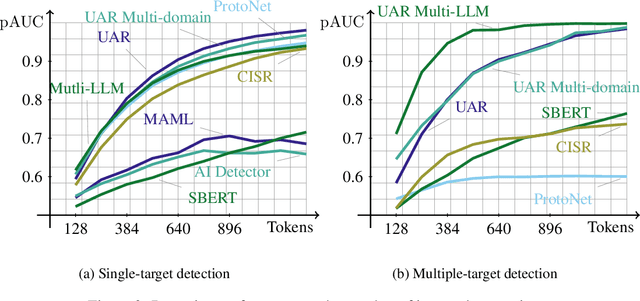
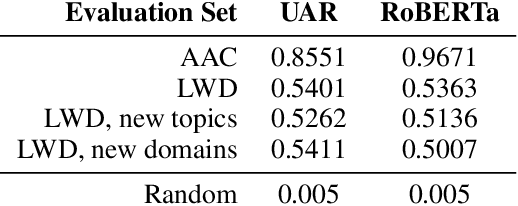
The advent of instruction-tuned language models that convincingly mimic human writing poses a significant risk of abuse. For example, such models could be used for plagiarism, disinformation, spam, or phishing. However, such abuse may be counteracted with the ability to detect whether a piece of text was composed by a language model rather than a human. Some previous approaches to this problem have relied on supervised methods trained on corpora of confirmed human and machine-written documents. Unfortunately, model under-specification poses an unavoidable challenge for neural network-based detectors, making them brittle in the face of data shifts, such as the release of further language models producing still more fluent text than the models used to train the detectors. Other previous approaches require access to the models that may have generated a document in question at inference or detection time, which is often impractical. In light of these challenges, we pursue a fundamentally different approach not relying on samples from language models of concern at training time. Instead, we propose to leverage representations of writing style estimated from human-authored text. Indeed, we find that features effective at distinguishing among human authors are also effective at distinguishing human from machine authors, including state of the art large language models like Llama 2, ChatGPT, and GPT-4. Furthermore, given a handful of examples composed by each of several specific language models of interest, our approach affords the ability to predict which model generated a given document.
Can Authorship Representation Learning Capture Stylistic Features?
Aug 24, 2023Automatically disentangling an author's style from the content of their writing is a longstanding and possibly insurmountable problem in computational linguistics. At the same time, the availability of large text corpora furnished with author labels has recently enabled learning authorship representations in a purely data-driven manner for authorship attribution, a task that ostensibly depends to a greater extent on encoding writing style than encoding content. However, success on this surrogate task does not ensure that such representations capture writing style since authorship could also be correlated with other latent variables, such as topic. In an effort to better understand the nature of the information these representations convey, and specifically to validate the hypothesis that they chiefly encode writing style, we systematically probe these representations through a series of targeted experiments. The results of these experiments suggest that representations learned for the surrogate authorship prediction task are indeed sensitive to writing style. As a consequence, authorship representations may be expected to be robust to certain kinds of data shift, such as topic drift over time. Additionally, our findings may open the door to downstream applications that require stylistic representations, such as style transfer.