 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Detection of Machine-Generated Text using Style Representations
Jan 12, 2024
The advent of instruction-tuned language models that convincingly mimic human writing poses a significant risk of abuse. For example, such models could be used for plagiarism, disinformation, spam, or phishing. However, such abuse may be counteracted with the ability to detect whether a piece of text was composed by a language model rather than a human. Some previous approaches to this problem have relied on supervised methods trained on corpora of confirmed human and machine-written documents. Unfortunately, model under-specification poses an unavoidable challenge for neural network-based detectors, making them brittle in the face of data shifts, such as the release of further language models producing still more fluent text than the models used to train the detectors. Other previous approaches require access to the models that may have generated a document in question at inference or detection time, which is often impractical. In light of these challenges, we pursue a fundamentally different approach not relying on samples from language models of concern at training time. Instead, we propose to leverage representations of writing style estimated from human-authored text. Indeed, we find that features effective at distinguishing among human authors are also effective at distinguishing human from machine authors, including state of the art large language models like Llama 2, ChatGPT, and GPT-4. Furthermore, given a handful of examples composed by each of several specific language models of interest, our approach affords the ability to predict which model generated a given document.
Can Authorship Representation Learning Capture Stylistic Features?
Aug 24, 2023Automatically disentangling an author's style from the content of their writing is a longstanding and possibly insurmountable problem in computational linguistics. At the same time, the availability of large text corpora furnished with author labels has recently enabled learning authorship representations in a purely data-driven manner for authorship attribution, a task that ostensibly depends to a greater extent on encoding writing style than encoding content. However, success on this surrogate task does not ensure that such representations capture writing style since authorship could also be correlated with other latent variables, such as topic. In an effort to better understand the nature of the information these representations convey, and specifically to validate the hypothesis that they chiefly encode writing style, we systematically probe these representations through a series of targeted experiments. The results of these experiments suggest that representations learned for the surrogate authorship prediction task are indeed sensitive to writing style. As a consequence, authorship representations may be expected to be robust to certain kinds of data shift, such as topic drift over time. Additionally, our findings may open the door to downstream applications that require stylistic representations, such as style transfer.
A Deep Metric Learning Approach to Account Linking
May 15, 2021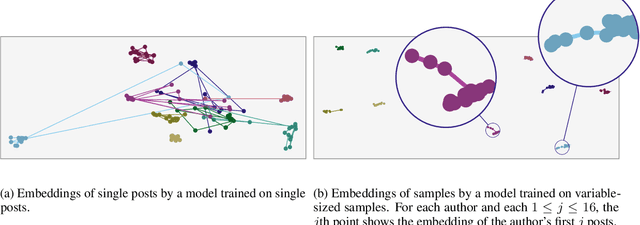
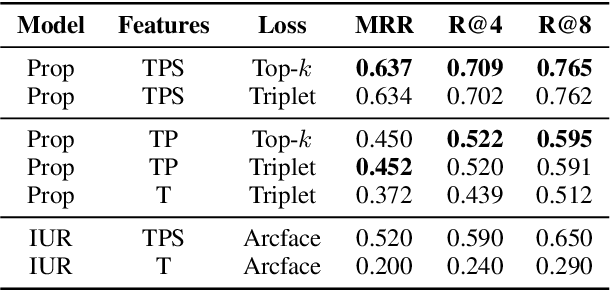
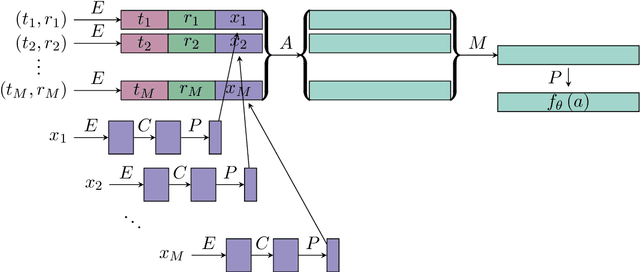
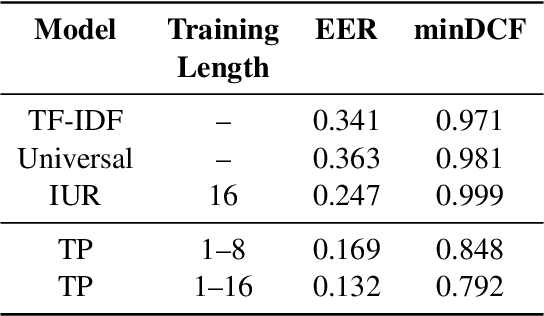
We consider the task of linking social media accounts that belong to the same author in an automated fashion on the basis of the content and metadata of their corresponding document streams. We focus on learning an embedding that maps variable-sized samples of user activity -- ranging from single posts to entire months of activity -- to a vector space, where samples by the same author map to nearby points. The approach does not require human-annotated data for training purposes, which allows us to leverage large amounts of social media content. The proposed model outperforms several competitive baselines under a novel evaluation framework modeled after established recognition benchmarks in other domains. Our method achieves high linking accuracy, even with small samples from accounts not seen at training time, a prerequisite for practical applications of the proposed linking framework.
Learning Invariant Representations of Social Media Users
Oct 11, 2019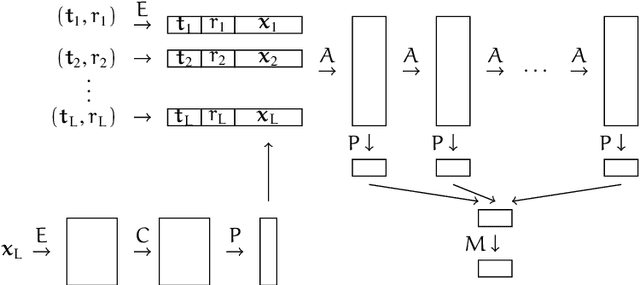
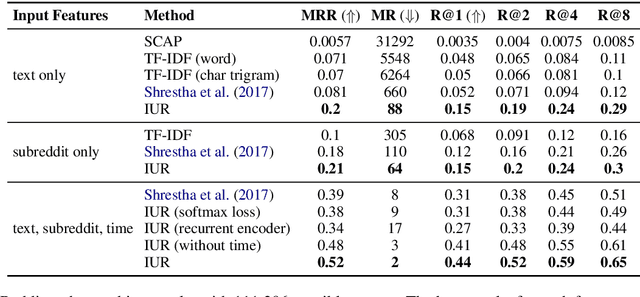
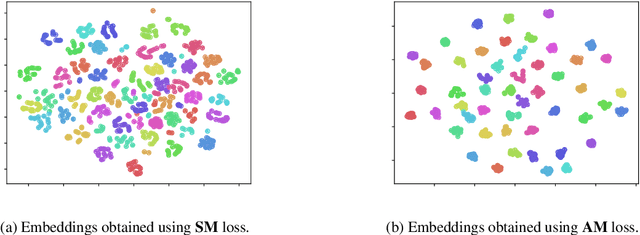
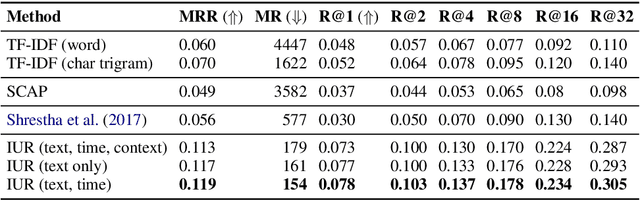
The evolution of social media users' behavior over time complicates user-level comparison tasks such as verification, classification, clustering, and ranking. As a result, na\"ive approaches may fail to generalize to new users or even to future observations of previously known users. In this paper, we propose a novel procedure to learn a mapping from short episodes of user activity on social media to a vector space in which the distance between points captures the similarity of the corresponding users' invariant features. We fit the model by optimizing a surrogate metric learning objective over a large corpus of unlabeled social media content. Once learned, the mapping may be applied to users not seen at training time and enables efficient comparisons of users in the resulting vector space. We present a comprehensive evaluation to validate the benefits of the proposed approach using data from Reddit, Twitter, and Wikipedia.