 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Model for Supervised Clustering with the Dirichlet Process Prior
Paper and Code
Jul 04, 2009
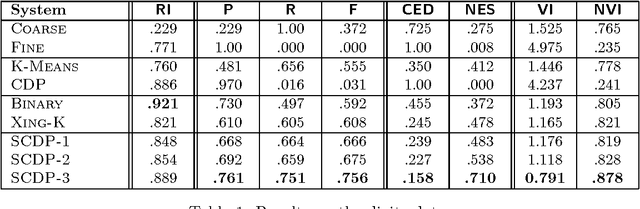

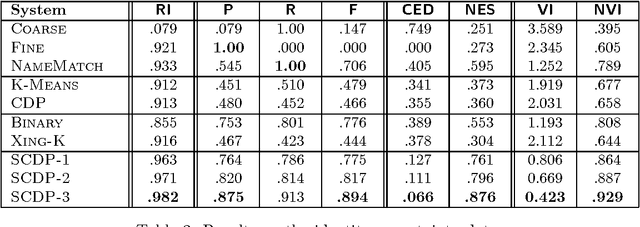
We develop a Bayesian framework for tackling the supervised clustering problem, the generic problem encountered in tasks such as reference matching, coreference resolution, identity uncertainty and record linkage. Our clustering model is based on the Dirichlet process prior, which enables us to define distributions over the countably infinite sets that naturally arise in this problem. We add supervision to our model by positing the existence of a set of unobserved random variables (we call these "reference types") that are generic across all clusters. Inference in our framework, which requires integrating over infinitely many parameters, is solved using Markov chain Monte Carlo techniques. We present algorithms for both conjugate and non-conjugate priors. We present a simple--but general--parameterization of our model based on a Gaussian assumption. We evaluate this model on one artificial task and three real-world tasks, comparing it against both unsupervised and state-of-the-art supervised algorithms. Our results show that our model is able to outperform other models across a variety of tasks and performance metrics.