 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom English To Foreign Languages: Transferring Pre-trained Language Models
Paper and Code
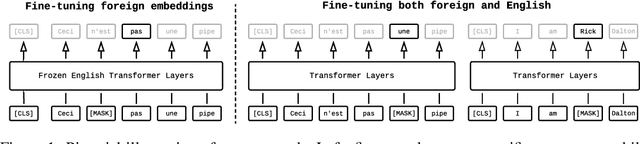

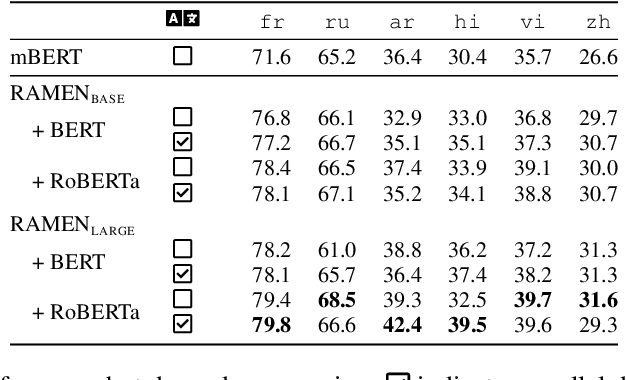
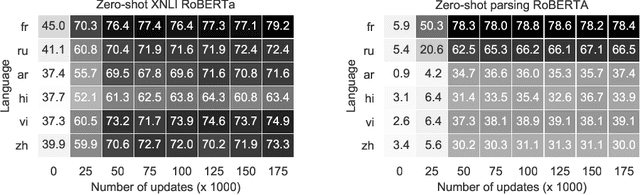
Pre-trained models have demonstrated their effectiveness in many downstream natural language processing (NLP) tasks. The availability of multilingual pre-trained models enables zero-shot transfer of NLP tasks from high resource languages to low resource ones. However, recent research in improving pre-trained models focuses heavily on English. While it is possible to train the latest neural architectures for other languages from scratch, it is undesirable due to the required amount of compute. In this work, we tackle the problem of transferring an existing pre-trained model from English to other languages under a limited computational budget. With a single GPU, our approach can obtain a foreign BERT base model within a day and a foreign BERT large within two days. Furthermore, evaluating our models on six languages, we demonstrate that our models are better than multilingual BERT on two zero-shot tasks: natural language inference and dependency parsing.