 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Dependency Parsing with Pre-trained Multilingual Sentence Representations
Paper and Code
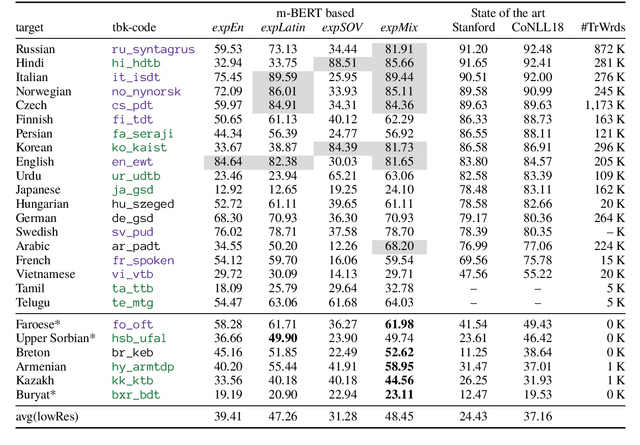
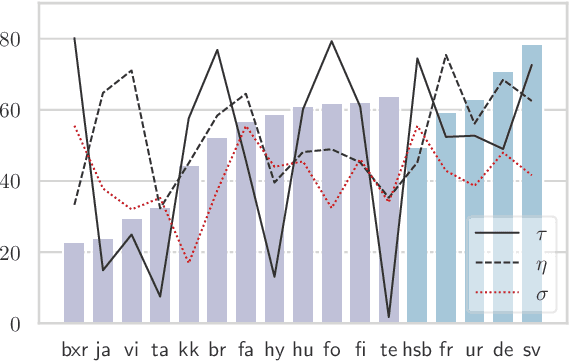
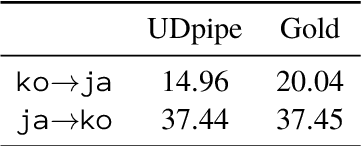
We investigate whether off-the-shelf deep bidirectional sentence representations trained on a massively multilingual corpus (multilingual BERT) enable the development of an unsupervised universal dependency parser. This approach only leverages a mix of monolingual corpora in many languages and does not require any translation data making it applicable to low-resource languages. In our experiments we outperform the best CoNLL 2018 language-specific systems in all of the shared task's six truly low-resource languages while using a single system. However, we also find that (i) parsing accuracy still varies dramatically when changing the training languages and (ii) in some target languages zero-shot transfer fails under all tested conditions, raising concerns on the 'universality' of the whole approach.