 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\forall$uto$\exists$$\lor\!\land$L: Autonomous Evaluation of LLMs for Truth Maintenance and Reasoning Tasks
Oct 11, 2024



This paper presents $\forall$uto$\exists$$\lor\!\land$L, a novel benchmark for scaling Large Language Model (LLM) assessment in formal tasks with clear notions of correctness, such as truth maintenance in translation and logical reasoning. $\forall$uto$\exists$$\lor\!\land$L is the first benchmarking paradigm that offers several key advantages necessary for scaling objective evaluation of LLMs without human labeling: (a) ability to evaluate LLMs of increasing sophistication by auto-generating tasks at different levels of difficulty; (b) auto-generation of ground truth that eliminates dependence on expensive and time-consuming human annotation; (c) the use of automatically generated, randomized datasets that mitigate the ability of successive LLMs to overfit to static datasets used in many contemporary benchmarks. Empirical analysis shows that an LLM's performance on $\forall$uto$\exists$$\lor\!\land$L is highly indicative of its performance on a diverse array of other benchmarks focusing on translation and reasoning tasks, making it a valuable autonomous evaluation paradigm in settings where hand-curated datasets can be hard to obtain and/or update.
Using Explainable AI and Hierarchical Planning for Outreach with Robots
Mar 31, 2024

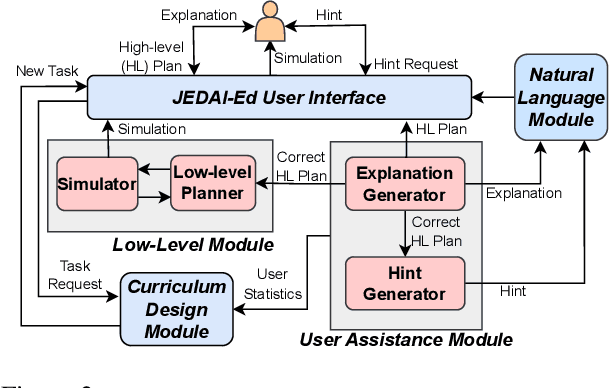

Understanding how robots plan and execute tasks is crucial in today's world, where they are becoming more prevalent in our daily lives. However, teaching non-experts the complexities of robot planning can be challenging. This work presents an open-source platform that simplifies the process using a visual interface that completely abstracts the complex internals of hierarchical planning that robots use for performing task and motion planning. Using the principles developed in the field of explainable AI, this intuitive platform enables users to create plans for robots to complete tasks, and provides helpful hints and natural language explanations for errors. The platform also has a built-in simulator to demonstrate how robots execute submitted plans. This platform's efficacy was tested in a user study on university students with little to no computer science background. Our results show that this platform is highly effective in teaching novice users the intuitions of robot task planning.
Can LLMs Converse Formally? Automatically Assessing LLMs in Translating and Interpreting Formal Specifications
Mar 27, 2024

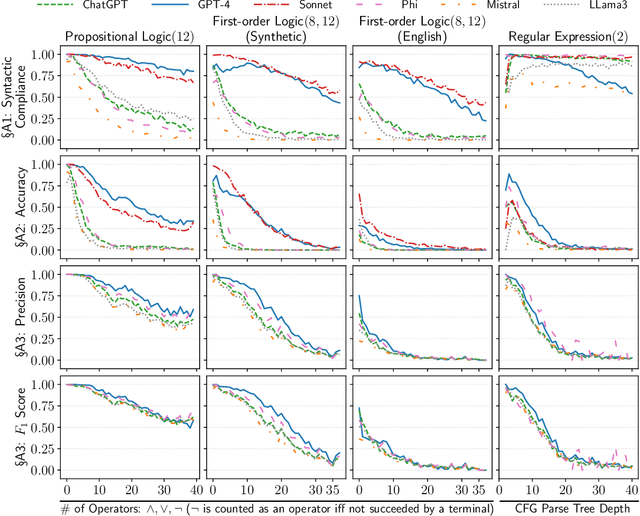
Stakeholders often describe system requirements using natural language which are then converted to formal syntax by a domain-expert leading to increased design costs. This paper assesses the capabilities of Large Language Models (LLMs) in converting between natural language descriptions and formal specifications. Existing work has evaluated the capabilities of LLMs in generating formal syntax such as source code but such experiments are typically hand-crafted and use problems that are likely to be in the training set of LLMs, and often require human-annotated datasets. We propose an approach that can use two copies of an LLM in conjunction with an off-the-shelf verifier to automatically evaluate its translation abilities without any additional human input. Our approach generates formal syntax using language grammars to automatically generate a dataset. We conduct an empirical evaluation to measure the accuracy of this translation task and show that SOTA LLMs cannot adequately solve this task, limiting their current utility in the design of complex systems.