 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPVO: Motion-Prior based Visual Odometry for PointGoal Navigation
Paper and Code
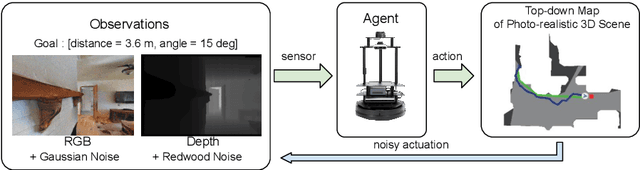
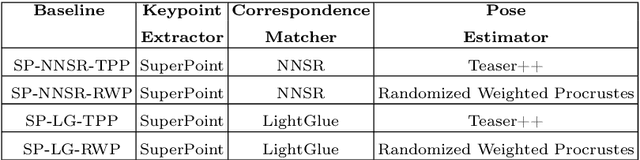
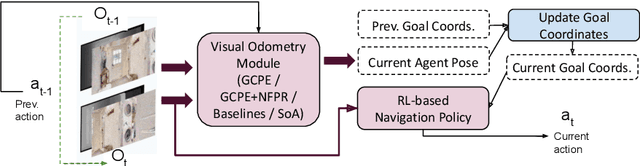
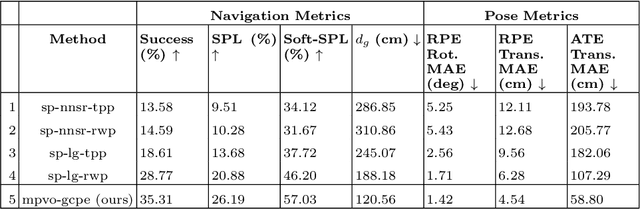
Visual odometry (VO) is essential for enabling accurate point-goal navigation of embodied agents in indoor environments where GPS and compass sensors are unreliable and inaccurate. However, traditional VO methods face challenges in wide-baseline scenarios, where fast robot motions and low frames per second (FPS) during inference hinder their performance, leading to drift and catastrophic failures in point-goal navigation. Recent deep-learned VO methods show robust performance but suffer from sample inefficiency during training; hence, they require huge datasets and compute resources. So, we propose a robust and sample-efficient VO pipeline based on motion priors available while an agent is navigating an environment. It consists of a training-free action-prior based geometric VO module that estimates a coarse relative pose which is further consumed as a motion prior by a deep-learned VO model, which finally produces a fine relative pose to be used by the navigation policy. This strategy helps our pipeline achieve up to 2x sample efficiency during training and demonstrates superior accuracy and robustness in point-goal navigation tasks compared to state-of-the-art VO method(s). Realistic indoor environments of the Gibson dataset is used in the AI-Habitat simulator to evaluate the proposed approach using navigation metrics (like success/SPL) and pose metrics (like RPE/ATE). We hope this method further opens a direction of work where motion priors from various sources can be utilized to improve VO estimates and achieve better results in embodied navigation tasks.