 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Cognition: Human Gesture and Natural Language Grounding Based Planning and Navigation for Indoor Robots
Paper and Code
Aug 14, 2021
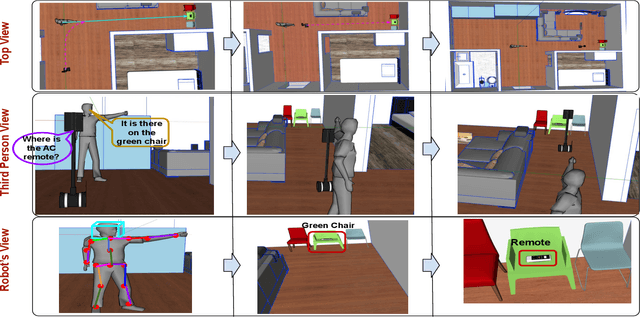
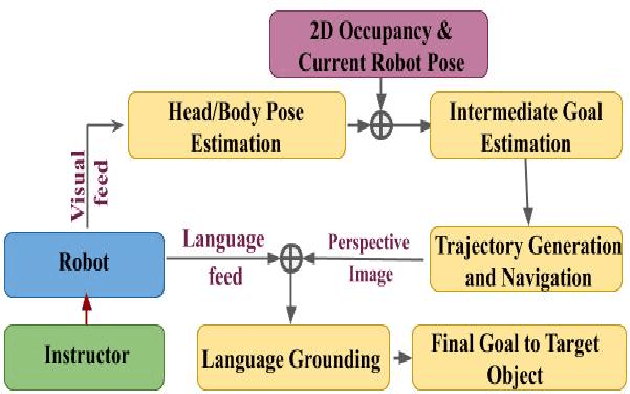
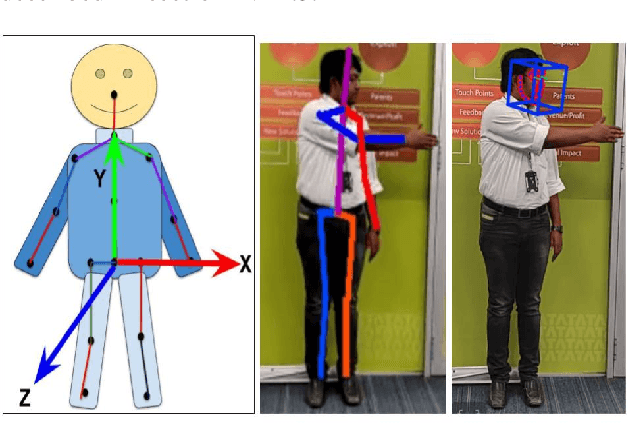
Cooperation among humans makes it easy to execute tasks and navigate seamlessly even in unknown scenarios. With our individual knowledge and collective cognition skills, we can reason about and perform well in unforeseen situations and environments. To achieve a similar potential for a robot navigating among humans and interacting with them, it is crucial for it to acquire the ability for easy, efficient and natural ways of communication and cognition sharing with humans. In this work, we aim to exploit human gestures which is known to be the most prominent modality of communication after the speech. We demonstrate how the incorporation of gestures for communicating spatial understanding can be achieved in a very simple yet effective way using a robot having the vision and listening capability. This shows a big advantage over using only Vision and Language-based Navigation, Language Grounding or Human-Robot Interaction in a task requiring the development of cognition and indoor navigation. We adapt the state-of-the-art modules of Language Grounding and Human-Robot Interaction to demonstrate a novel system pipeline in real-world environments on a Telepresence robot for performing a set of challenging tasks. To the best of our knowledge, this is the first pipeline to couple the fields of HRI and language grounding in an indoor environment to demonstrate autonomous navigation.