 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Cognition: Human Gesture and Natural Language Grounding Based Planning and Navigation for Indoor Robots
Aug 14, 2021
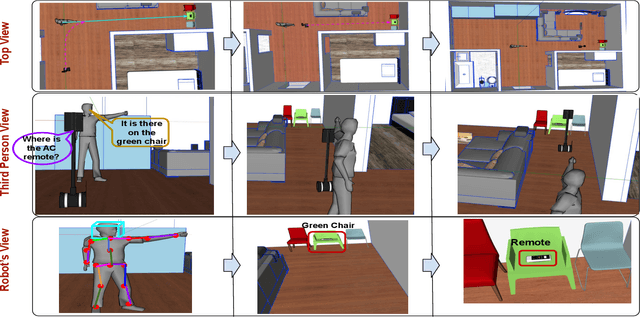
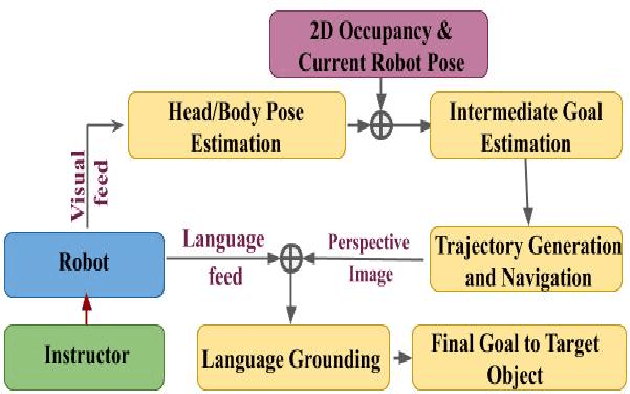
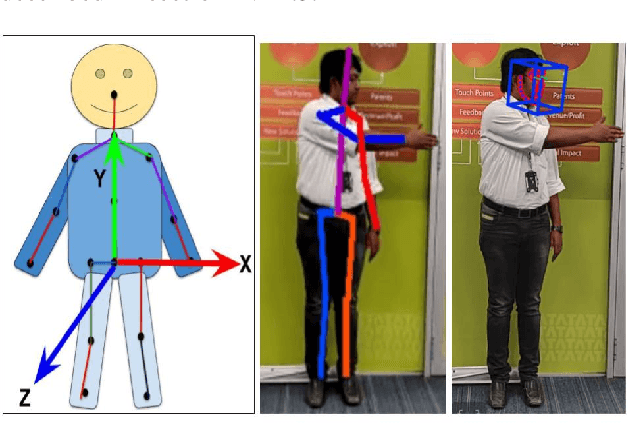
Cooperation among humans makes it easy to execute tasks and navigate seamlessly even in unknown scenarios. With our individual knowledge and collective cognition skills, we can reason about and perform well in unforeseen situations and environments. To achieve a similar potential for a robot navigating among humans and interacting with them, it is crucial for it to acquire the ability for easy, efficient and natural ways of communication and cognition sharing with humans. In this work, we aim to exploit human gestures which is known to be the most prominent modality of communication after the speech. We demonstrate how the incorporation of gestures for communicating spatial understanding can be achieved in a very simple yet effective way using a robot having the vision and listening capability. This shows a big advantage over using only Vision and Language-based Navigation, Language Grounding or Human-Robot Interaction in a task requiring the development of cognition and indoor navigation. We adapt the state-of-the-art modules of Language Grounding and Human-Robot Interaction to demonstrate a novel system pipeline in real-world environments on a Telepresence robot for performing a set of challenging tasks. To the best of our knowledge, this is the first pipeline to couple the fields of HRI and language grounding in an indoor environment to demonstrate autonomous navigation.
Indoor dense depth map at drone hovering
Apr 25, 2019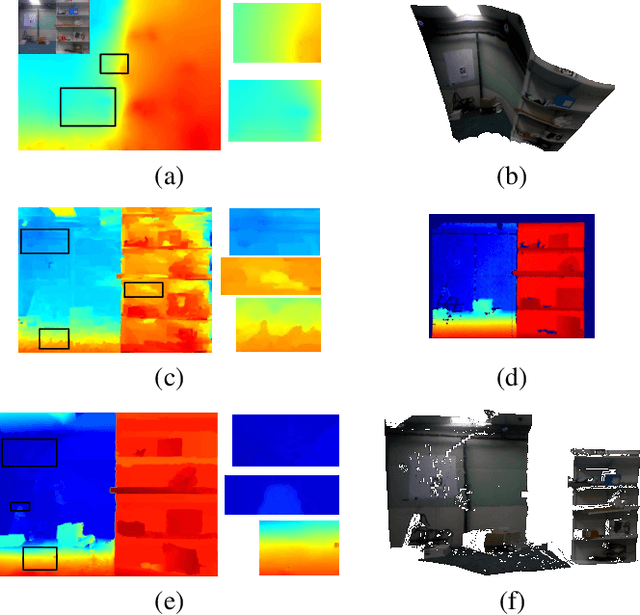
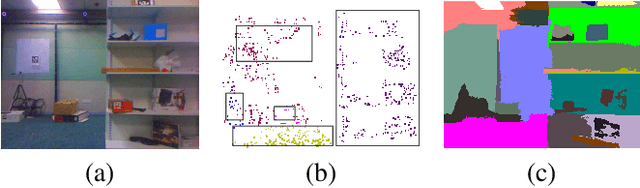
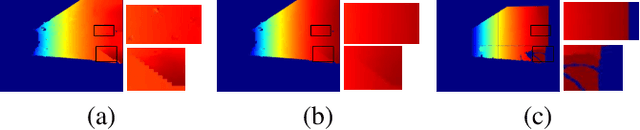

Autonomous Micro Aerial Vehicles (MAVs) gained tremendous attention in recent years. Autonomous flight in indoor requires a dense depth map for navigable space detection which is the fundamental component for autonomous navigation. In this paper, we address the problem of reconstructing dense depth while a drone is hovering (small camera motion) in indoor scenes using already estimated cameras and sparse point cloud obtained from a vSLAM. We start by segmenting the scene based on sudden depth variation using sparse 3D points and introduce a patch-based local plane fitting via energy minimization which combines photometric consistency and co-planarity with neighbouring patches. The method also combines a plane sweep technique for image segments having almost no sparse point for initialization. Experiments show, the proposed method produces better depth for indoor in artificial lighting condition, low-textured environment compared to earlier literature in small motion.
Edge SLAM: Edge Points Based Monocular Visual SLAM
Jan 14, 2019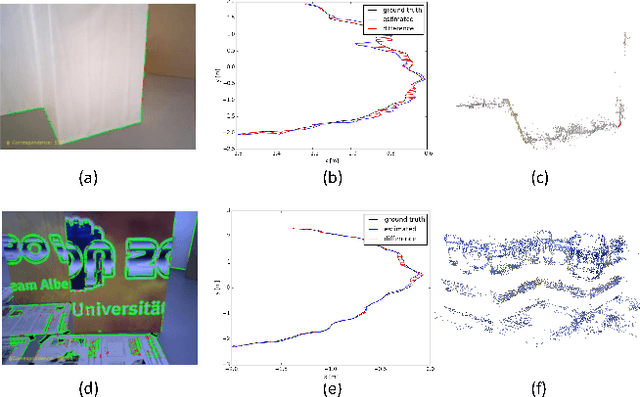
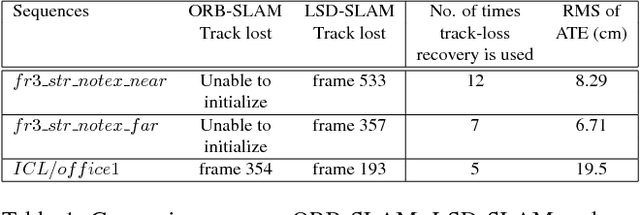
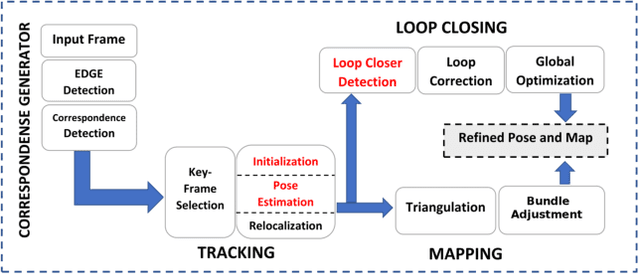
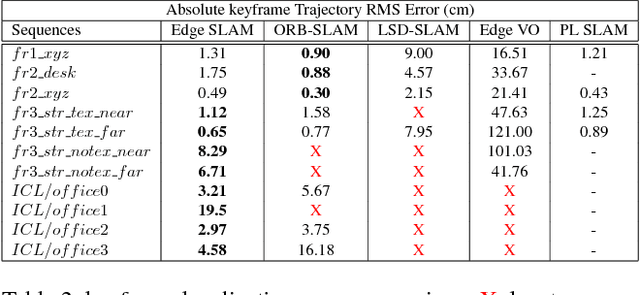
Visual SLAM shows significant progress in recent years due to high attention from vision community but still, challenges remain for low-textured environments. Feature based visual SLAMs do not produce reliable camera and structure estimates due to insufficient features in a low-textured environment. Moreover, existing visual SLAMs produce partial reconstruction when the number of 3D-2D correspondences is insufficient for incremental camera estimation using bundle adjustment. This paper presents Edge SLAM, a feature based monocular visual SLAM which mitigates the above mentioned problems. Our proposed Edge SLAM pipeline detects edge points from images and tracks those using optical flow for point correspondence. We further refine these point correspondences using geometrical relationship among three views. Owing to our edge-point tracking, we use a robust method for two-view initialization for bundle adjustment. Our proposed SLAM also identifies the potential situations where estimating a new camera into the existing reconstruction is becoming unreliable and we adopt a novel method to estimate the new camera reliably using a local optimization technique. We present an extensive evaluation of our proposed SLAM pipeline with most popular open datasets and compare with the state-of-the art. Experimental result indicates that our Edge SLAM is robust and works reliably well for both textured and less-textured environment in comparison to existing state-of-the-art SLAMs.
* ICCV Workshops 2017, Venice, Italy, October 22-29, 2017