 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Single-View View Synthesis with Self-Rectified Pseudo-Stereo
Apr 20, 2023Synthesizing novel views from a single view image is a highly ill-posed problem. We discover an effective solution to reduce the learning ambiguity by expanding the single-view view synthesis problem to a multi-view setting. Specifically, we leverage the reliable and explicit stereo prior to generate a pseudo-stereo viewpoint, which serves as an auxiliary input to construct the 3D space. In this way, the challenging novel view synthesis process is decoupled into two simpler problems of stereo synthesis and 3D reconstruction. In order to synthesize a structurally correct and detail-preserved stereo image, we propose a self-rectified stereo synthesis to amend erroneous regions in an identify-rectify manner. Hard-to-train and incorrect warping samples are first discovered by two strategies, 1) pruning the network to reveal low-confident predictions; and 2) bidirectionally matching between stereo images to allow the discovery of improper mapping. These regions are then inpainted to form the final pseudo-stereo. With the aid of this extra input, a preferable 3D reconstruction can be easily obtained, and our method can work with arbitrary 3D representations. Extensive experiments show that our method outperforms state-of-the-art single-view view synthesis methods and stereo synthesis methods.
Fine-grained Domain Adaptive Crowd Counting via Point-derived Segmentation
Aug 06, 2021
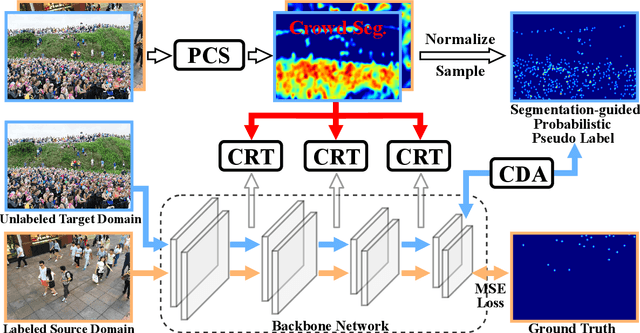
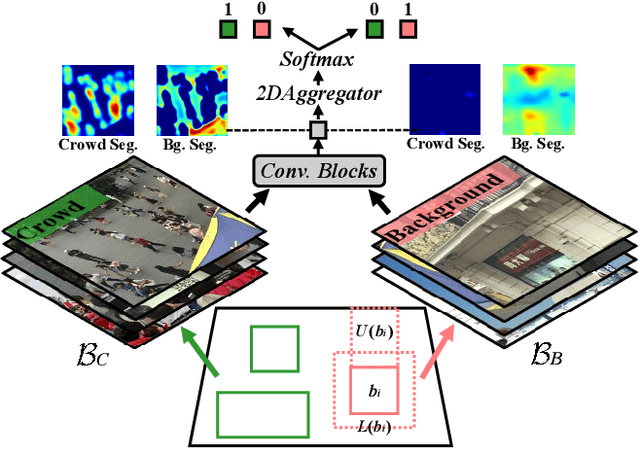
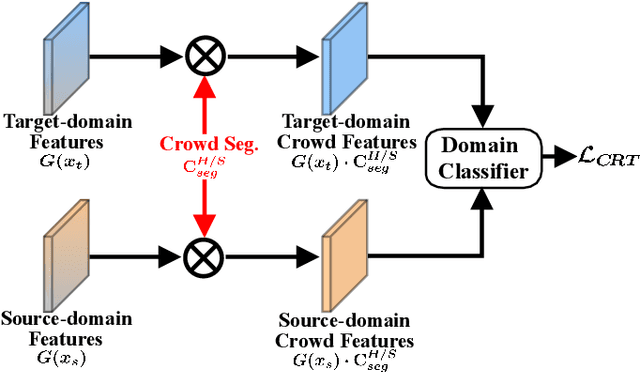
Existing domain adaptation methods for crowd counting view each crowd image as a whole and reduce domain discrepancies on crowds and backgrounds simultaneously. However, we argue that these methods are suboptimal, as crowds and backgrounds have quite different characteristics and backgrounds may vary dramatically in different crowd scenes (see Fig.~\ref{teaser}). This makes crowds not well aligned across domains together with backgrounds in a holistic manner. To this end, we propose to untangle crowds and backgrounds from crowd images and design fine-grained domain adaption methods for crowd counting. Different from other tasks which possess region-based fine-grained annotations (e.g., segments or bounding boxes), crowd counting only annotates one point on each human head, which impedes the implementation of fine-grained adaptation methods. To tackle this issue, we propose a novel and effective schema to learn crowd segmentation from point-level crowd counting annotations in the context of Multiple Instance Learning. We further leverage the derived segments to propose a crowd-aware fine-grained domain adaptation framework for crowd counting, which consists of two novel adaptation modules, i.e., Crowd Region Transfer (CRT) and Crowd Density Alignment (CDA). Specifically, the CRT module is designed to guide crowd features transfer across domains beyond background distractions, and the CDA module dedicates to constraining the target-domain crowd density distributions. Extensive experiments on multiple cross-domain settings (i.e., Synthetic $\rightarrow$ Real, Fixed $\rightarrow$ Fickle, Normal $\rightarrow$ BadWeather) demonstrate the superiority of the proposed method compared with state-of-the-art methods.
Reducing Spatial Labeling Redundancy for Semi-supervised Crowd Counting
Aug 06, 2021

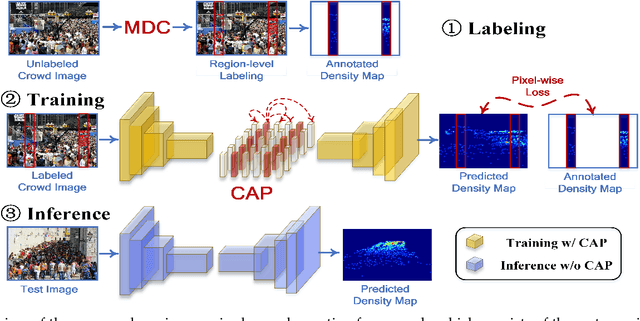
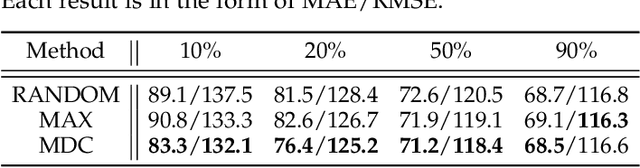
Labeling is onerous for crowd counting as it should annotate each individual in crowd images. Recently, several methods have been proposed for semi-supervised crowd counting to reduce the labeling efforts. Given a limited labeling budget, they typically select a few crowd images and densely label all individuals in each of them. Despite the promising results, we argue the None-or-All labeling strategy is suboptimal as the densely labeled individuals in each crowd image usually appear similar while the massive unlabeled crowd images may contain entirely diverse individuals. To this end, we propose to break the labeling chain of previous methods and make the first attempt to reduce spatial labeling redundancy for semi-supervised crowd counting. First, instead of annotating all the regions in each crowd image, we propose to annotate the representative ones only. We analyze the region representativeness from both vertical and horizontal directions, and formulate them as cluster centers of Gaussian Mixture Models. Additionally, to leverage the rich unlabeled regions, we exploit the similarities among individuals in each crowd image to directly supervise the unlabeled regions via feature propagation instead of the error-prone label propagation employed in the previous methods. In this way, we can transfer the original spatial labeling redundancy caused by individual similarities to effective supervision signals on the unlabeled regions. Extensive experiments on the widely-used benchmarks demonstrate that our method can outperform previous best approaches by a large margin.