 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Domain Adaptive Crowd Counting via Point-derived Segmentation
Paper and Code
Aug 06, 2021
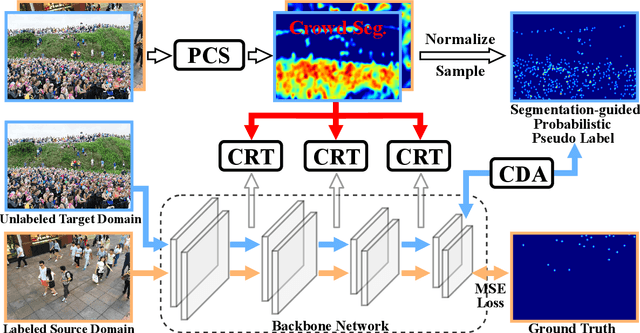
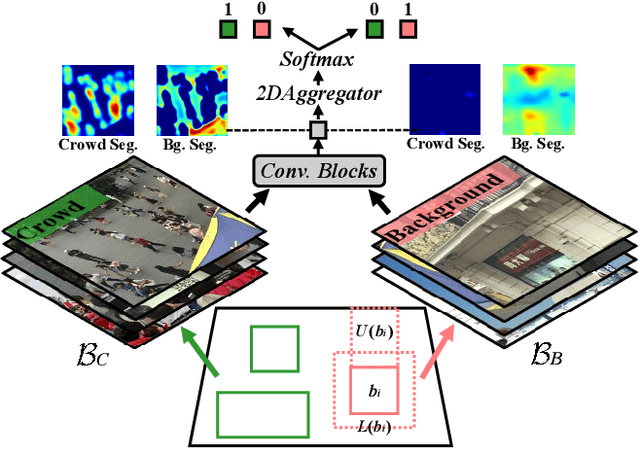
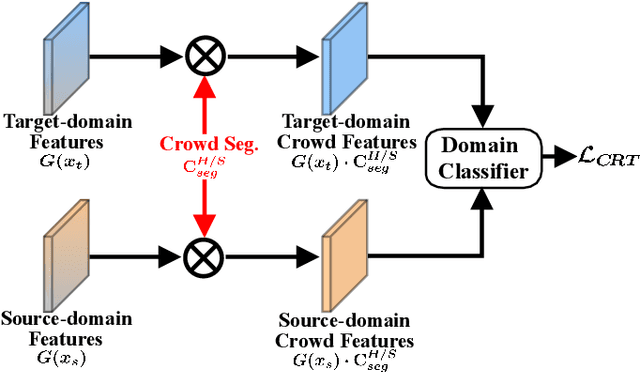
Existing domain adaptation methods for crowd counting view each crowd image as a whole and reduce domain discrepancies on crowds and backgrounds simultaneously. However, we argue that these methods are suboptimal, as crowds and backgrounds have quite different characteristics and backgrounds may vary dramatically in different crowd scenes (see Fig.~\ref{teaser}). This makes crowds not well aligned across domains together with backgrounds in a holistic manner. To this end, we propose to untangle crowds and backgrounds from crowd images and design fine-grained domain adaption methods for crowd counting. Different from other tasks which possess region-based fine-grained annotations (e.g., segments or bounding boxes), crowd counting only annotates one point on each human head, which impedes the implementation of fine-grained adaptation methods. To tackle this issue, we propose a novel and effective schema to learn crowd segmentation from point-level crowd counting annotations in the context of Multiple Instance Learning. We further leverage the derived segments to propose a crowd-aware fine-grained domain adaptation framework for crowd counting, which consists of two novel adaptation modules, i.e., Crowd Region Transfer (CRT) and Crowd Density Alignment (CDA). Specifically, the CRT module is designed to guide crowd features transfer across domains beyond background distractions, and the CDA module dedicates to constraining the target-domain crowd density distributions. Extensive experiments on multiple cross-domain settings (i.e., Synthetic $\rightarrow$ Real, Fixed $\rightarrow$ Fickle, Normal $\rightarrow$ BadWeather) demonstrate the superiority of the proposed method compared with state-of-the-art methods.