 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Equation Discovery in Hybrid Dynamical Systems
Jun 06, 2024



Hybrid dynamical systems are prevalent in science and engineering to express complex systems with continuous and discrete states. To learn the laws of systems, all previous methods for equation discovery in hybrid systems follow a two-stage paradigm, i.e. they first group time series into small cluster fragments and then discover equations in each fragment separately through methods in non-hybrid systems. Although effective, these methods do not fully take advantage of the commonalities in the shared dynamics of multiple fragments that are driven by the same equations. Besides, the two-stage paradigm breaks the interdependence between categorizing and representing dynamics that jointly form hybrid systems. In this paper, we reformulate the problem and propose an end-to-end learning framework, i.e. Amortized Equation Discovery (AMORE), to jointly categorize modes and discover equations characterizing the dynamics of each mode by all segments of the mode. Experiments on four hybrid and six non-hybrid systems show that our method outperforms previous methods on equation discovery, segmentation, and forecasting.
Graph Switching Dynamical Systems
Jun 01, 2023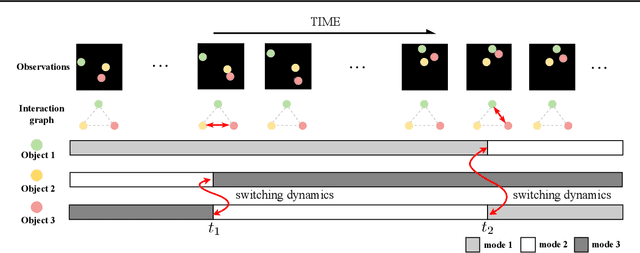
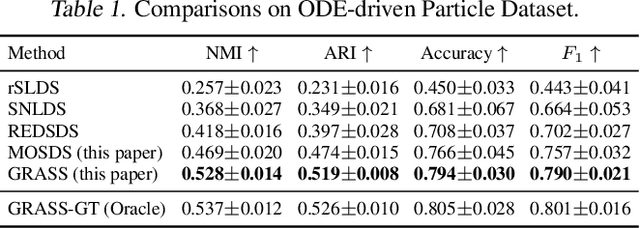
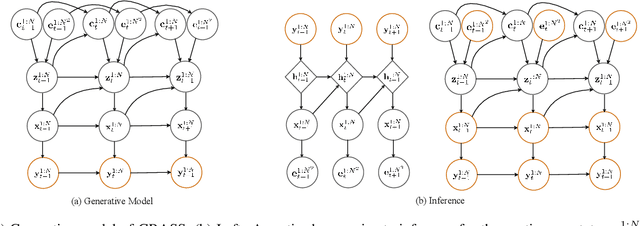
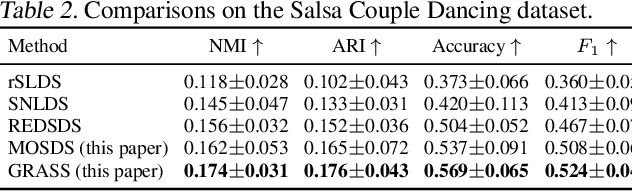
Dynamical systems with complex behaviours, e.g. immune system cells interacting with a pathogen, are commonly modelled by splitting the behaviour into different regimes, or modes, each with simpler dynamics, and then learning the switching behaviour from one mode to another. Switching Dynamical Systems (SDS) are a powerful tool that automatically discovers these modes and mode-switching behaviour from time series data. While effective, these methods focus on independent objects, where the modes of one object are independent of the modes of the other objects. In this paper, we focus on the more general interacting object setting for switching dynamical systems, where the per-object dynamics also depends on an unknown and dynamically changing subset of other objects and their modes. To this end, we propose a novel graph-based approach for switching dynamical systems, GRAph Switching dynamical Systems (GRASS), in which we use a dynamic graph to characterize interactions between objects and learn both intra-object and inter-object mode-switching behaviour. We introduce two new datasets for this setting, a synthesized ODE-driven particles dataset and a real-world Salsa Couple Dancing dataset. Experiments show that GRASS can consistently outperforms previous state-of-the-art methods.
Glance to Count: Learning to Rank with Anchors for Weakly-supervised Crowd Counting
May 29, 2022
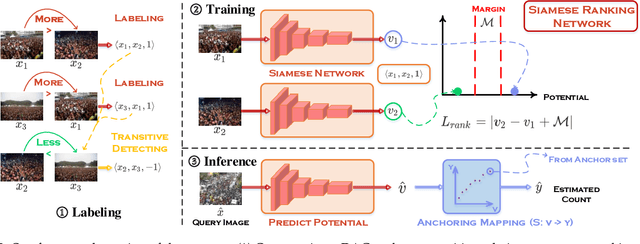


Crowd image is arguably one of the most laborious data to annotate. In this paper, we devote to reduce the massive demand of densely labeled crowd data, and propose a novel weakly-supervised setting, in which we leverage the binary ranking of two images with high-contrast crowd counts as training guidance. To enable training under this new setting, we convert the crowd count regression problem to a ranking potential prediction problem. In particular, we tailor a Siamese Ranking Network that predicts the potential scores of two images indicating the ordering of the counts. Hence, the ultimate goal is to assign appropriate potentials for all the crowd images to ensure their orderings obey the ranking labels. On the other hand, potentials reveal the relative crowd sizes but cannot yield an exact crowd count. We resolve this problem by introducing "anchors" during the inference stage. Concretely, anchors are a few images with count labels used for referencing the corresponding counts from potential scores by a simple linear mapping function. We conduct extensive experiments to study various combinations of supervision, and we show that the proposed method outperforms existing weakly-supervised methods without additional labeling effort by a large margin.
NFormer: Robust Person Re-identification with Neighbor Transformer
Apr 20, 2022



Person re-identification aims to retrieve persons in highly varying settings across different cameras and scenarios, in which robust and discriminative representation learning is crucial. Most research considers learning representations from single images, ignoring any potential interactions between them. However, due to the high intra-identity variations, ignoring such interactions typically leads to outlier features. To tackle this issue, we propose a Neighbor Transformer Network, or NFormer, which explicitly models interactions across all input images, thus suppressing outlier features and leading to more robust representations overall. As modelling interactions between enormous amount of images is a massive task with lots of distractors, NFormer introduces two novel modules, the Landmark Agent Attention, and the Reciprocal Neighbor Softmax. Specifically, the Landmark Agent Attention efficiently models the relation map between images by a low-rank factorization with a few landmarks in feature space. Moreover, the Reciprocal Neighbor Softmax achieves sparse attention to relevant -- rather than all -- neighbors only, which alleviates interference of irrelevant representations and further relieves the computational burden. In experiments on four large-scale datasets, NFormer achieves a new state-of-the-art. The code is released at \url{https://github.com/haochenheheda/NFormer}.
Fine-grained Domain Adaptive Crowd Counting via Point-derived Segmentation
Aug 06, 2021
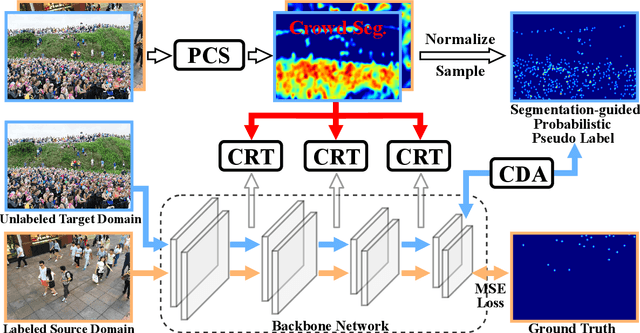
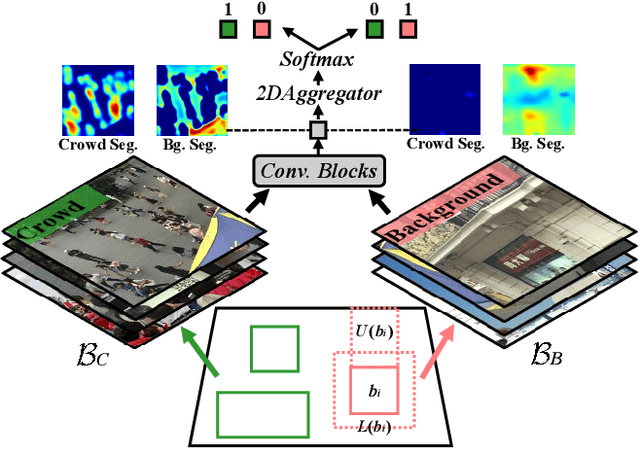
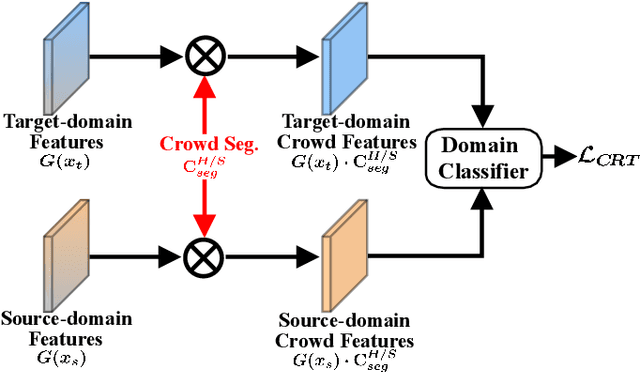
Existing domain adaptation methods for crowd counting view each crowd image as a whole and reduce domain discrepancies on crowds and backgrounds simultaneously. However, we argue that these methods are suboptimal, as crowds and backgrounds have quite different characteristics and backgrounds may vary dramatically in different crowd scenes (see Fig.~\ref{teaser}). This makes crowds not well aligned across domains together with backgrounds in a holistic manner. To this end, we propose to untangle crowds and backgrounds from crowd images and design fine-grained domain adaption methods for crowd counting. Different from other tasks which possess region-based fine-grained annotations (e.g., segments or bounding boxes), crowd counting only annotates one point on each human head, which impedes the implementation of fine-grained adaptation methods. To tackle this issue, we propose a novel and effective schema to learn crowd segmentation from point-level crowd counting annotations in the context of Multiple Instance Learning. We further leverage the derived segments to propose a crowd-aware fine-grained domain adaptation framework for crowd counting, which consists of two novel adaptation modules, i.e., Crowd Region Transfer (CRT) and Crowd Density Alignment (CDA). Specifically, the CRT module is designed to guide crowd features transfer across domains beyond background distractions, and the CDA module dedicates to constraining the target-domain crowd density distributions. Extensive experiments on multiple cross-domain settings (i.e., Synthetic $\rightarrow$ Real, Fixed $\rightarrow$ Fickle, Normal $\rightarrow$ BadWeather) demonstrate the superiority of the proposed method compared with state-of-the-art methods.
Reducing Spatial Labeling Redundancy for Semi-supervised Crowd Counting
Aug 06, 2021

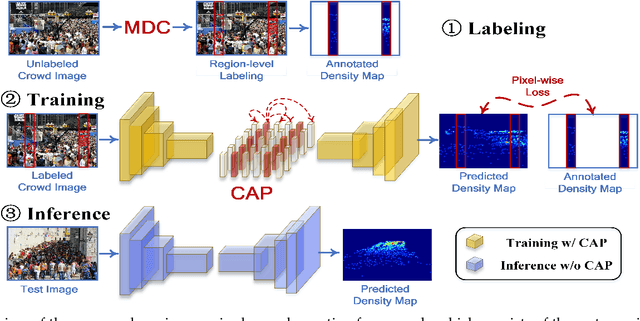
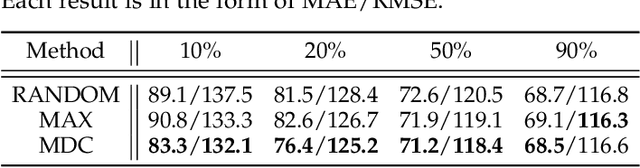
Labeling is onerous for crowd counting as it should annotate each individual in crowd images. Recently, several methods have been proposed for semi-supervised crowd counting to reduce the labeling efforts. Given a limited labeling budget, they typically select a few crowd images and densely label all individuals in each of them. Despite the promising results, we argue the None-or-All labeling strategy is suboptimal as the densely labeled individuals in each crowd image usually appear similar while the massive unlabeled crowd images may contain entirely diverse individuals. To this end, we propose to break the labeling chain of previous methods and make the first attempt to reduce spatial labeling redundancy for semi-supervised crowd counting. First, instead of annotating all the regions in each crowd image, we propose to annotate the representative ones only. We analyze the region representativeness from both vertical and horizontal directions, and formulate them as cluster centers of Gaussian Mixture Models. Additionally, to leverage the rich unlabeled regions, we exploit the similarities among individuals in each crowd image to directly supervise the unlabeled regions via feature propagation instead of the error-prone label propagation employed in the previous methods. In this way, we can transfer the original spatial labeling redundancy caused by individual similarities to effective supervision signals on the unlabeled regions. Extensive experiments on the widely-used benchmarks demonstrate that our method can outperform previous best approaches by a large margin.