 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Does the Server See? Understanding Privacy Leakage from Large Language Models in Split Inference
May 22, 2026The deployment of large language models (LLMs) on resource-constrained devices remains challenging, spurring interest in split inference, where models are partitioned between client and server to reduce computational burden and enhance privacy by transmitting only intermediate activations. However, the privacy-preserving capabilities of split inference, particularly in the context of LLMs, have not been exhaustively investigated. To fill this gap, we introduce ActInv, which solves an intermediate activation matching problem to reconstruct the client's input. Extensive evaluations demonstrate that ActInv achieves high-fidelity reconstructions, even in the presence of common perturbation-based defenses such as Gaussian noise injection and activation sparsification. To systematically understand this vulnerability, we develop Perturbation Amplification Factor (PAF), a metric for quantifying a layer's inherent resistance to reconstruction. Our analysis reveals that privacy vulnerability is not uniform across layers, with some layers being highly susceptible to leakage while others offer natural resistance. Furthermore, we demonstrate that defense effectiveness can be significantly improved by calibrating perturbation directions to maximize reconstruction error during backpropagation. Building on these insights, we design PriPert and conduct comprehensive evaluations, covering privacy, utility, and computational overhead, to demonstrate its effectiveness.
Boosting Gradient Leakage Attacks: Data Reconstruction in Realistic FL Settings
Jun 10, 2025Federated learning (FL) enables collaborative model training among multiple clients without the need to expose raw data. Its ability to safeguard privacy, at the heart of FL, has recently been a hot-button debate topic. To elaborate, several studies have introduced a type of attacks known as gradient leakage attacks (GLAs), which exploit the gradients shared during training to reconstruct clients' raw data. On the flip side, some literature, however, contends no substantial privacy risk in practical FL environments due to the effectiveness of such GLAs being limited to overly relaxed conditions, such as small batch sizes and knowledge of clients' data distributions. This paper bridges this critical gap by empirically demonstrating that clients' data can still be effectively reconstructed, even within realistic FL environments. Upon revisiting GLAs, we recognize that their performance failures stem from their inability to handle the gradient matching problem. To alleviate the performance bottlenecks identified above, we develop FedLeak, which introduces two novel techniques, partial gradient matching and gradient regularization. Moreover, to evaluate the performance of FedLeak in real-world FL environments, we formulate a practical evaluation protocol grounded in a thorough review of extensive FL literature and industry practices. Under this protocol, FedLeak can still achieve high-fidelity data reconstruction, thereby underscoring the significant vulnerability in FL systems and the urgent need for more effective defense methods.
Fedward: Flexible Federated Backdoor Defense Framework with Non-IID Data
Jul 01, 2023
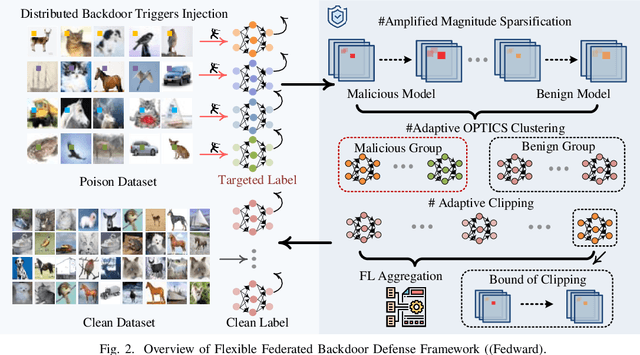


Federated learning (FL) enables multiple clients to collaboratively train deep learning models while considering sensitive local datasets' privacy. However, adversaries can manipulate datasets and upload models by injecting triggers for federated backdoor attacks (FBA). Existing defense strategies against FBA consider specific and limited attacker models, and a sufficient amount of noise to be injected only mitigates rather than eliminates FBA. To address these deficiencies, we introduce a Flexible Federated Backdoor Defense Framework (Fedward) to ensure the elimination of adversarial backdoors. We decompose FBA into various attacks, and design amplified magnitude sparsification (AmGrad) and adaptive OPTICS clustering (AutoOPTICS) to address each attack. Meanwhile, Fedward uses the adaptive clipping method by regarding the number of samples in the benign group as constraints on the boundary. This ensures that Fedward can maintain the performance for the Non-IID scenario. We conduct experimental evaluations over three benchmark datasets and thoroughly compare them to state-of-the-art studies. The results demonstrate the promising defense performance from Fedward, moderately improved by 33% $\sim$ 75 in clustering defense methods, and 96.98%, 90.74%, and 89.8% for Non-IID to the utmost extent for the average FBA success rate over MNIST, FMNIST, and CIFAR10, respectively.
Towards Privacy-Preserving Neural Architecture Search
Apr 22, 2022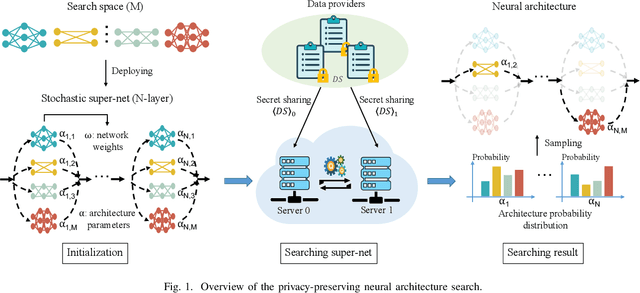
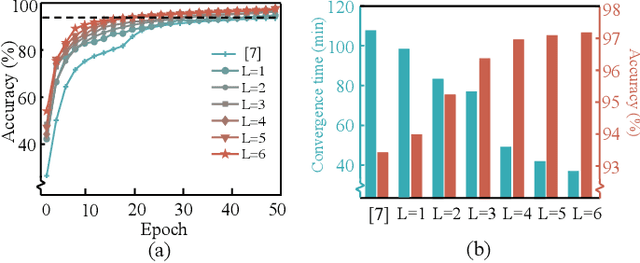
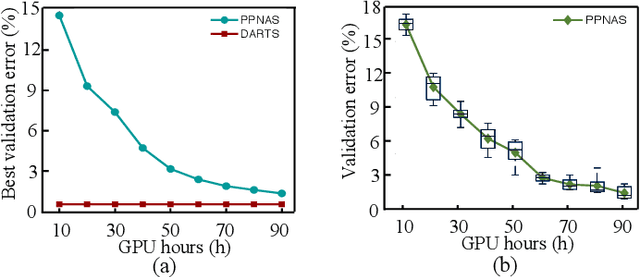
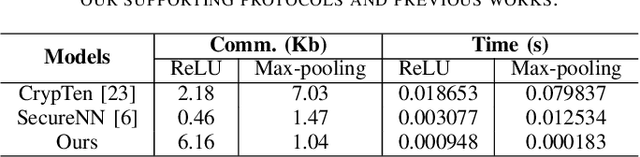
Machine learning promotes the continuous development of signal processing in various fields, including network traffic monitoring, EEG classification, face identification, and many more. However, massive user data collected for training deep learning models raises privacy concerns and increases the difficulty of manually adjusting the network structure. To address these issues, we propose a privacy-preserving neural architecture search (PP-NAS) framework based on secure multi-party computation to protect users' data and the model's parameters/hyper-parameters. PP-NAS outsources the NAS task to two non-colluding cloud servers for making full advantage of mixed protocols design. Complement to the existing PP machine learning frameworks, we redesign the secure ReLU and Max-pooling garbled circuits for significantly better efficiency ($3 \sim 436$ times speed-up). We develop a new alternative to approximate the Softmax function over secret shares, which bypasses the limitation of approximating exponential operations in Softmax while improving accuracy. Extensive analyses and experiments demonstrate PP-NAS's superiority in security, efficiency, and accuracy.