 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEducator Attention: How computational tools can systematically identify the distribution of a key resource for students
Feb 27, 2025
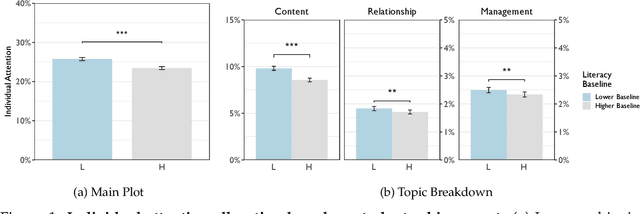
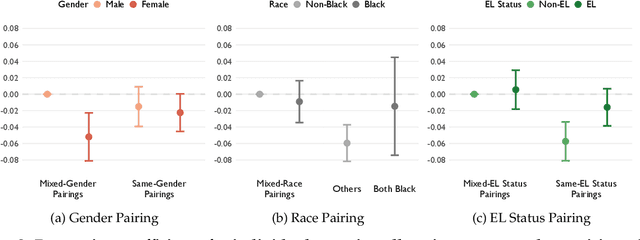
Educator attention is critical for student success, yet how educators distribute their attention across students remains poorly understood due to data and methodological constraints. This study presents the first large-scale computational analysis of educator attention patterns, leveraging over 1 million educator utterances from virtual group tutoring sessions linked to detailed student demographic and academic achievement data. Using natural language processing techniques, we systematically examine the recipient and nature of educator attention. Our findings reveal that educators often provide more attention to lower-achieving students. However, disparities emerge across demographic lines, particularly by gender. Girls tend to receive less attention when paired with boys, even when they are the lower achieving student in the group. Lower-achieving female students in mixed-gender pairs receive significantly less attention than their higher-achieving male peers, while lower-achieving male students receive significantly and substantially more attention than their higher-achieving female peers. We also find some differences by race and English learner (EL) status, with low-achieving Black students receiving additional attention only when paired with another Black student but not when paired with a non-Black peer. In contrast, higher-achieving EL students receive disproportionately more attention than their lower-achieving EL peers. This work highlights how large-scale interaction data and computational methods can uncover subtle but meaningful disparities in teaching practices, providing empirical insights to inform more equitable and effective educational strategies.
Tutor CoPilot: A Human-AI Approach for Scaling Real-Time Expertise
Oct 03, 2024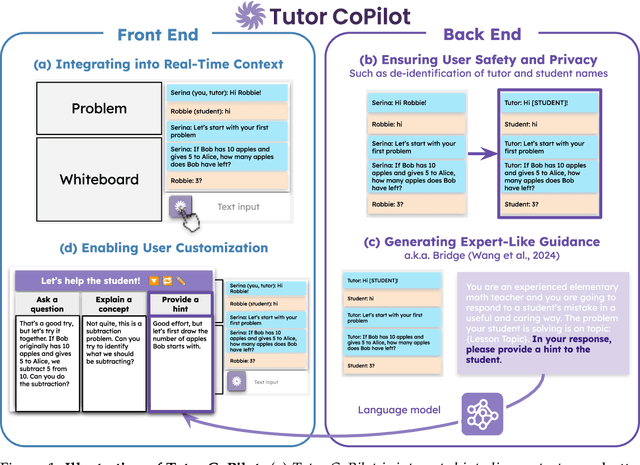
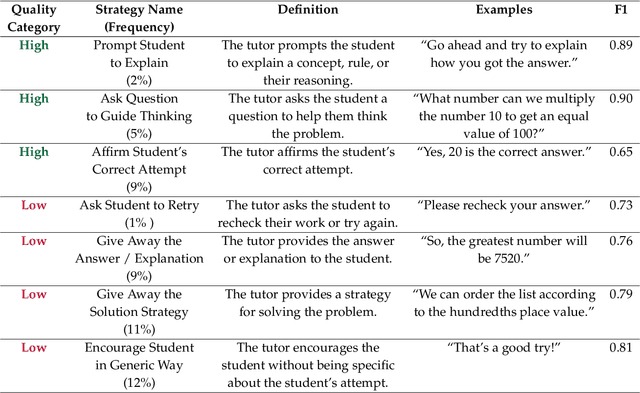
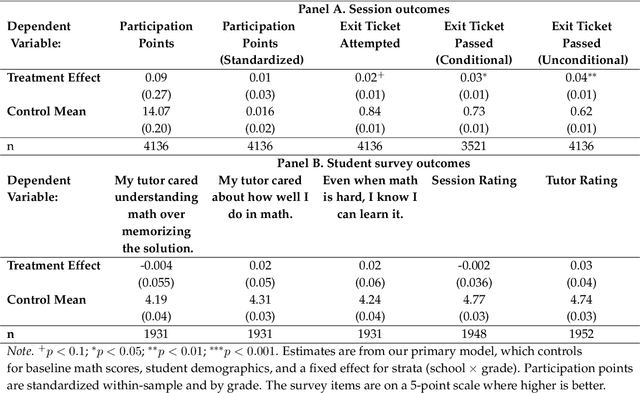
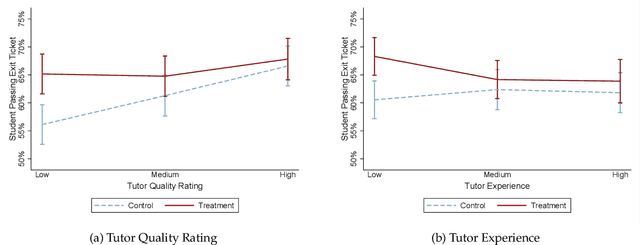
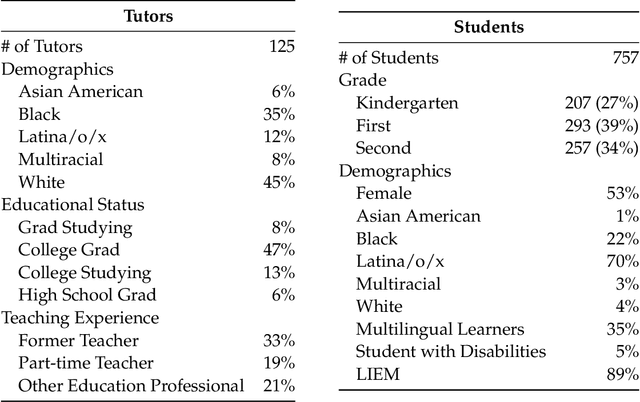
Generative AI, particularly Language Models (LMs), has the potential to transform real-world domains with societal impact, particularly where access to experts is limited. For example, in education, training novice educators with expert guidance is important for effectiveness but expensive, creating significant barriers to improving education quality at scale. This challenge disproportionately harms students from under-served communities, who stand to gain the most from high-quality education. We introduce Tutor CoPilot, a novel Human-AI approach that leverages a model of expert thinking to provide expert-like guidance to tutors as they tutor. This study is the first randomized controlled trial of a Human-AI system in live tutoring, involving 900 tutors and 1,800 K-12 students from historically under-served communities. Following a preregistered analysis plan, we find that students working with tutors that have access to Tutor CoPilot are 4 percentage points (p.p.) more likely to master topics (p<0.01). Notably, students of lower-rated tutors experienced the greatest benefit, improving mastery by 9 p.p. We find that Tutor CoPilot costs only $20 per-tutor annually. We analyze 550,000+ messages using classifiers to identify pedagogical strategies, and find that tutors with access to Tutor CoPilot are more likely to use high-quality strategies to foster student understanding (e.g., asking guiding questions) and less likely to give away the answer to the student. Tutor interviews highlight how Tutor CoPilot's guidance helps tutors to respond to student needs, though they flag issues in Tutor CoPilot, such as generating suggestions that are not grade-level appropriate. Altogether, our study of Tutor CoPilot demonstrates how Human-AI systems can scale expertise in real-world domains, bridge gaps in skills and create a future where high-quality education is accessible to all students.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.