 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAVAE: Augmentation-Augmented Variational Autoencoders
Jul 26, 2021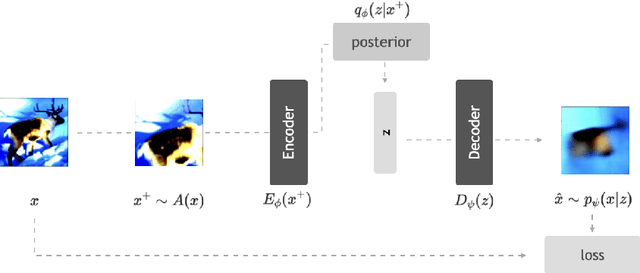
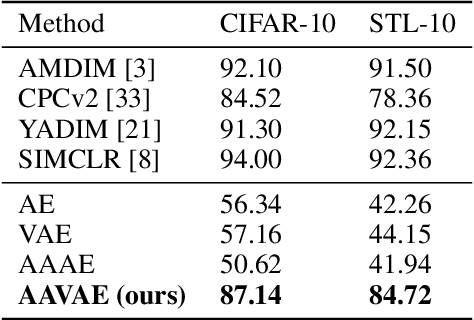
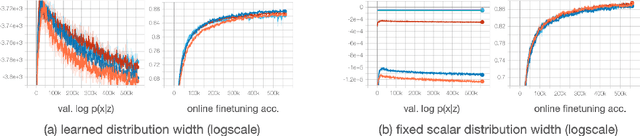
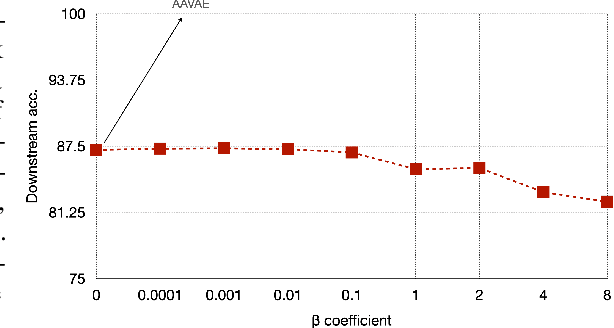
Recent methods for self-supervised learning can be grouped into two paradigms: contrastive and non-contrastive approaches. Their success can largely be attributed to data augmentation pipelines which generate multiple views of a single input that preserve the underlying semantics. In this work, we introduce augmentation-augmented variational autoencoders (AAVAE), a third approach to self-supervised learning based on autoencoding. We derive AAVAE starting from the conventional variational autoencoder (VAE), by replacing the KL divergence regularization, which is agnostic to the input domain, with data augmentations that explicitly encourage the internal representations to encode domain-specific invariances and equivariances. We empirically evaluate the proposed AAVAE on image classification, similar to how recent contrastive and non-contrastive learning algorithms have been evaluated. Our experiments confirm the effectiveness of data augmentation as a replacement for KL divergence regularization. The AAVAE outperforms the VAE by 30% on CIFAR-10 and 40% on STL-10. The results for AAVAE are largely comparable to the state-of-the-art for self-supervised learning.
A Framework For Contrastive Self-Supervised Learning And Designing A New Approach
Aug 31, 2020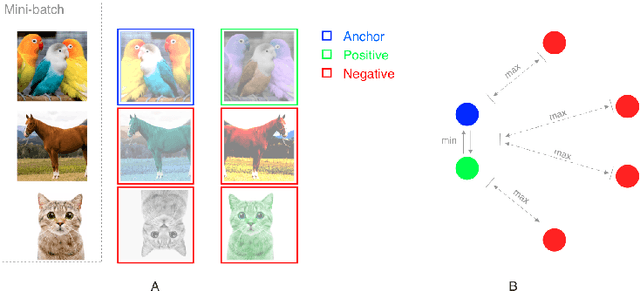
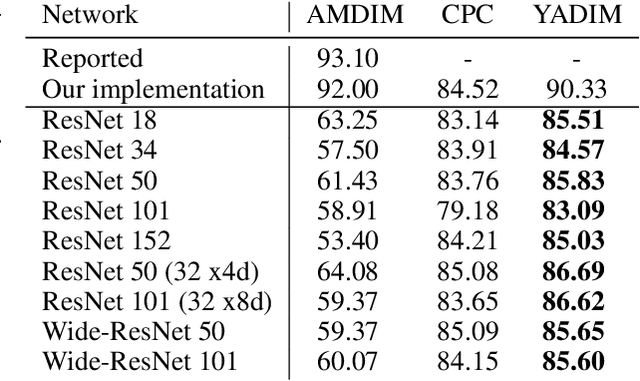
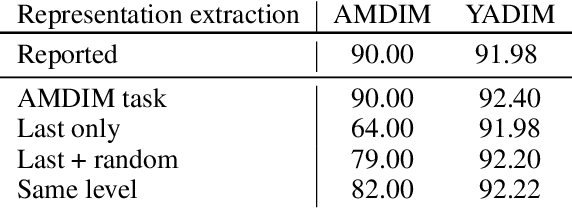
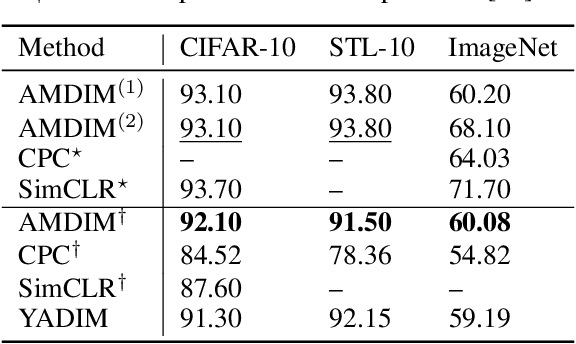
Contrastive self-supervised learning (CSL) is an approach to learn useful representations by solving a pretext task that selects and compares anchor, negative and positive (APN) features from an unlabeled dataset. We present a conceptual framework that characterizes CSL approaches in five aspects (1) data augmentation pipeline, (2) encoder selection, (3) representation extraction, (4) similarity measure, and (5) loss function. We analyze three leading CSL approaches--AMDIM, CPC, and SimCLR--, and show that despite different motivations, they are special cases under this framework. We show the utility of our framework by designing Yet Another DIM (YADIM) which achieves competitive results on CIFAR-10, STL-10 and ImageNet, and is more robust to the choice of encoder and the representation extraction strategy. To support ongoing CSL research, we release the PyTorch implementation of this conceptual framework along with standardized implementations of AMDIM, CPC (V2), SimCLR, BYOL, Moco (V2) and YADIM.
Predicting Floor-Level for 911 Calls with Neural Networks and Smartphone Sensor Data
Sep 15, 2018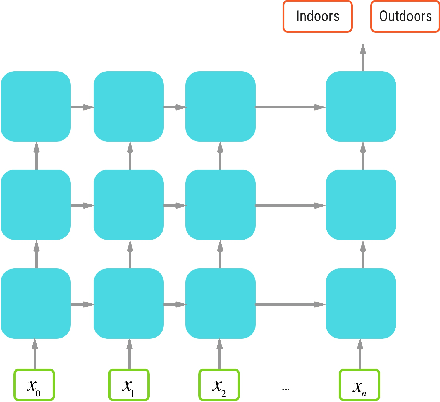
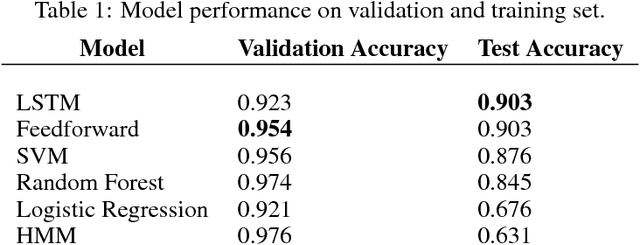

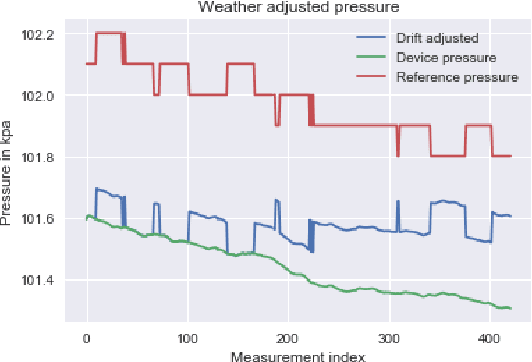
In cities with tall buildings, emergency responders need an accurate floor level location to find 911 callers quickly. We introduce a system to estimate a victim's floor level via their mobile device's sensor data in a two-step process. First, we train a neural network to determine when a smartphone enters or exits a building via GPS signal changes. Second, we use a barometer equipped smartphone to measure the change in barometric pressure from the entrance of the building to the victim's indoor location. Unlike impractical previous approaches, our system is the first that does not require the use of beacons, prior knowledge of the building infrastructure, or knowledge of user behavior. We demonstrate real-world feasibility through 63 experiments across five different tall buildings throughout New York City where our system predicted the correct floor level with 100% accuracy.