 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework For Contrastive Self-Supervised Learning And Designing A New Approach
Paper and Code
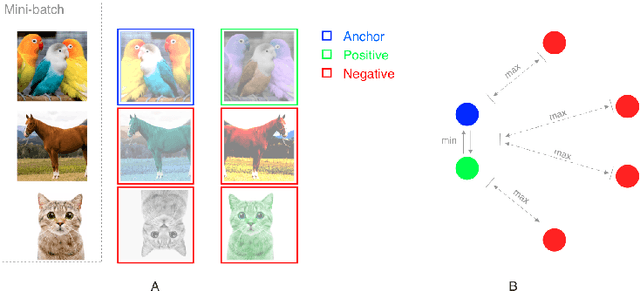
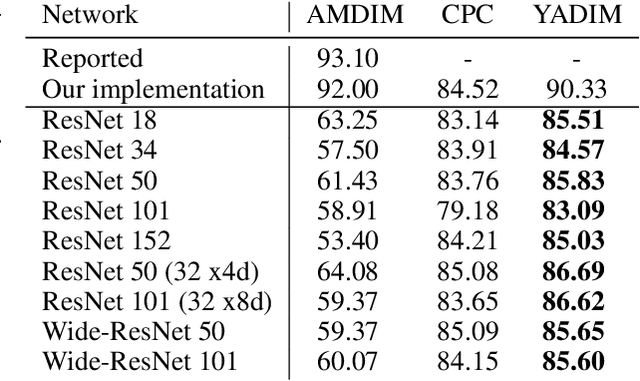
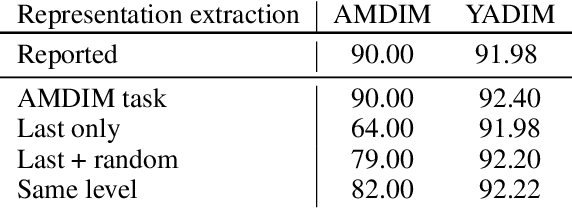
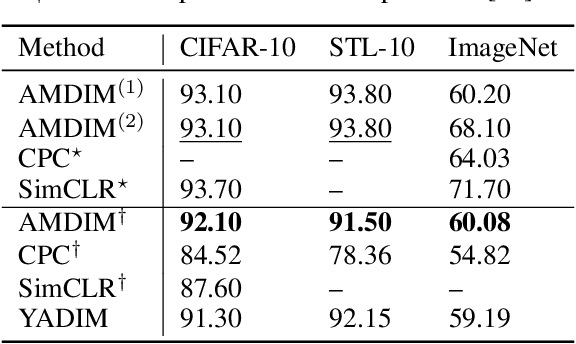
Contrastive self-supervised learning (CSL) is an approach to learn useful representations by solving a pretext task that selects and compares anchor, negative and positive (APN) features from an unlabeled dataset. We present a conceptual framework that characterizes CSL approaches in five aspects (1) data augmentation pipeline, (2) encoder selection, (3) representation extraction, (4) similarity measure, and (5) loss function. We analyze three leading CSL approaches--AMDIM, CPC, and SimCLR--, and show that despite different motivations, they are special cases under this framework. We show the utility of our framework by designing Yet Another DIM (YADIM) which achieves competitive results on CIFAR-10, STL-10 and ImageNet, and is more robust to the choice of encoder and the representation extraction strategy. To support ongoing CSL research, we release the PyTorch implementation of this conceptual framework along with standardized implementations of AMDIM, CPC (V2), SimCLR, BYOL, Moco (V2) and YADIM.