 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultural Analytics for Good: Building Inclusive Evaluation Frameworks for Historical IR
Jan 17, 2026This work bridges the fields of information retrieval and cultural analytics to support equitable access to historical knowledge. Using the British Library BL19 digital collection (more than 35,000 works from 1700-1899), we construct a benchmark for studying changes in language, terminology and retrieval in the 19th-century fiction and non-fiction. Our approach combines expert-driven query design, paragraph-level relevance annotation, and Large Language Model (LLM) assistance to create a scalable evaluation framework grounded in human expertise. We focus on knowledge transfer from fiction to non-fiction, investigating how narrative understanding and semantic richness in fiction can improve retrieval for scholarly and factual materials. This interdisciplinary framework not only improves retrieval accuracy but also fosters interpretability, transparency, and cultural inclusivity in digital archives. Our work provides both practical evaluation resources and a methodological paradigm for developing retrieval systems that support richer, historically aware engagement with digital archives, ultimately working towards more emancipatory knowledge infrastructures.
Unveiling Temporal Trends in 19th Century Literature: An Information Retrieval Approach
Jan 12, 2025



In English literature, the 19th century witnessed a significant transition in styles, themes, and genres. Consequently, the novels from this period display remarkable diversity. This paper explores these variations by examining the evolution of term usage in 19th century English novels through the lens of information retrieval. By applying a query expansion-based approach to a decade-segmented collection of fiction from the British Library, we examine how related terms vary over time. Our analysis employs multiple standard metrics including Kendall's tau, Jaccard similarity, and Jensen-Shannon divergence to assess overlaps and shifts in expanded query term sets. Our results indicate a significant degree of divergence in the related terms across decades as selected by the query expansion technique, suggesting substantial linguistic and conceptual changes throughout the 19th century novels.
Curatr: A Platform for Semantic Analysis and Curation of Historical Literary Texts
Jun 13, 2023The increasing availability of digital collections of historical and contemporary literature presents a wealth of possibilities for new research in the humanities. The scale and diversity of such collections however, presents particular challenges in identifying and extracting relevant content. This paper presents Curatr, an online platform for the exploration and curation of literature with machine learning-supported semantic search, designed within the context of digital humanities scholarship. The platform provides a text mining workflow that combines neural word embeddings with expert domain knowledge to enable the generation of thematic lexicons, allowing researches to curate relevant sub-corpora from a large corpus of 18th and 19th century digitised texts.
* 12 pages
Mitigating Gender Bias in Machine Learning Data Sets
May 18, 2020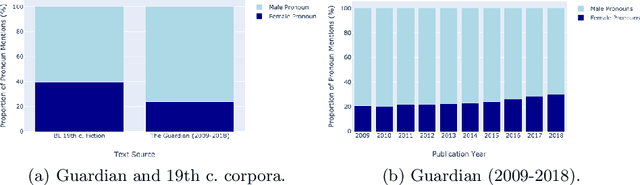

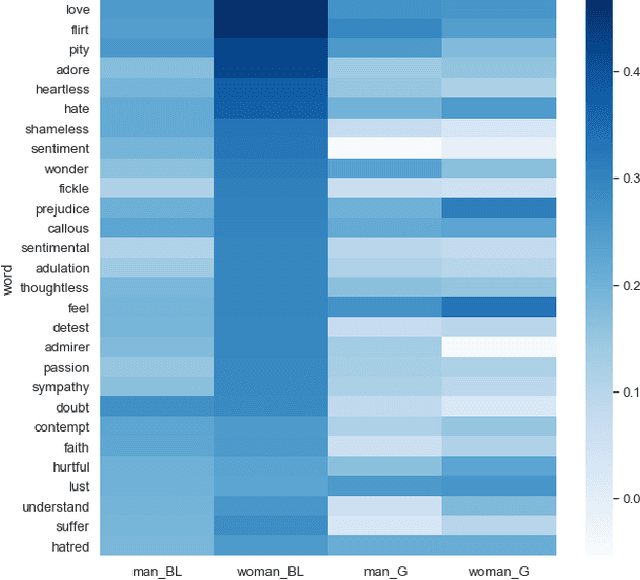
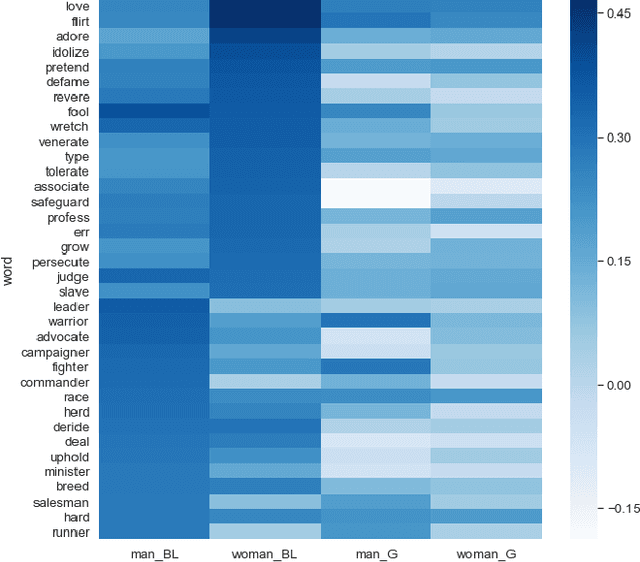
Artificial Intelligence has the capacity to amplify and perpetuate societal biases and presents profound ethical implications for society. Gender bias has been identified in the context of employment advertising and recruitment tools, due to their reliance on underlying language processing and recommendation algorithms. Attempts to address such issues have involved testing learned associations, integrating concepts of fairness to machine learning and performing more rigorous analysis of training data. Mitigating bias when algorithms are trained on textual data is particularly challenging given the complex way gender ideology is embedded in language. This paper proposes a framework for the identification of gender bias in training data for machine learning.The work draws upon gender theory and sociolinguistics to systematically indicate levels of bias in textual training data and associated neural word embedding models, thus highlighting pathways for both removing bias from training data and critically assessing its impact.