 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerated Bias: Auditing Internal Bias Dynamics of Text-To-Image Generative Models
Oct 10, 2024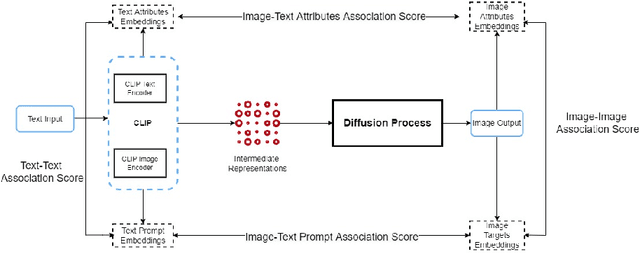


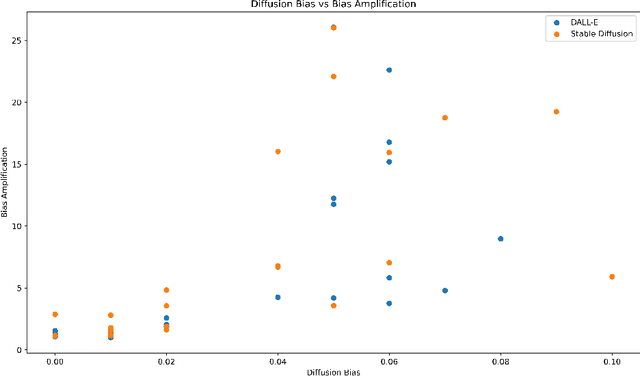
Text-To-Image (TTI) Diffusion Models such as DALL-E and Stable Diffusion are capable of generating images from text prompts. However, they have been shown to perpetuate gender stereotypes. These models process data internally in multiple stages and employ several constituent models, often trained separately. In this paper, we propose two novel metrics to measure bias internally in these multistage multimodal models. Diffusion Bias was developed to detect and measures bias introduced by the diffusion stage of the models. Bias Amplification measures amplification of bias during the text-to-image conversion process. Our experiments reveal that TTI models amplify gender bias, the diffusion process itself contributes to bias and that Stable Diffusion v2 is more prone to gender bias than DALL-E 2.
Biased Attention: Do Vision Transformers Amplify Gender Bias More than Convolutional Neural Networks?
Sep 15, 2023


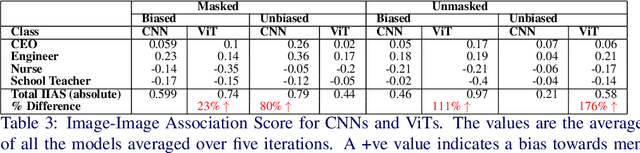
Deep neural networks used in computer vision have been shown to exhibit many social biases such as gender bias. Vision Transformers (ViTs) have become increasingly popular in computer vision applications, outperforming Convolutional Neural Networks (CNNs) in many tasks such as image classification. However, given that research on mitigating bias in computer vision has primarily focused on CNNs, it is important to evaluate the effect of a different network architecture on the potential for bias amplification. In this paper we therefore introduce a novel metric to measure bias in architectures, Accuracy Difference. We examine bias amplification when models belonging to these two architectures are used as a part of large multimodal models, evaluating the different image encoders of Contrastive Language Image Pretraining which is an important model used in many generative models such as DALL-E and Stable Diffusion. Our experiments demonstrate that architecture can play a role in amplifying social biases due to the different techniques employed by the models for feature extraction and embedding as well as their different learning properties. This research found that ViTs amplified gender bias to a greater extent than CNNs
Multimodal Composite Association Score: Measuring Gender Bias in Generative Multimodal Models
Apr 26, 2023
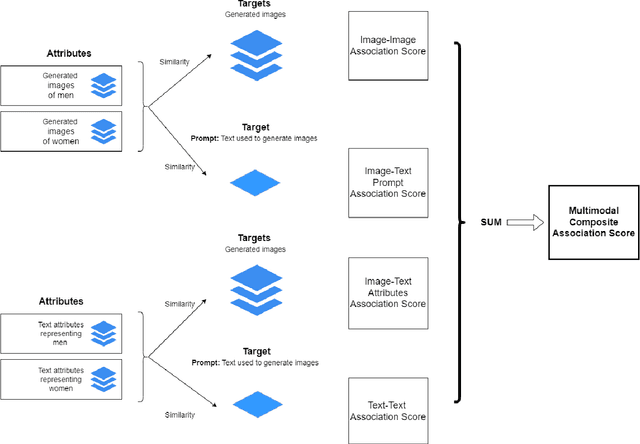

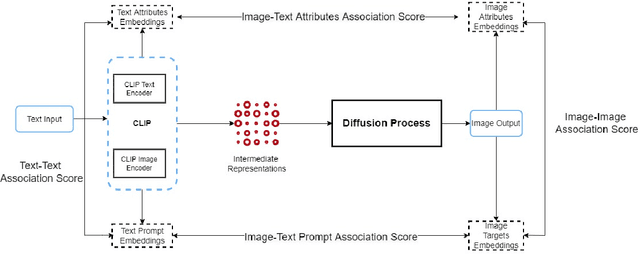
Generative multimodal models based on diffusion models have seen tremendous growth and advances in recent years. Models such as DALL-E and Stable Diffusion have become increasingly popular and successful at creating images from texts, often combining abstract ideas. However, like other deep learning models, they also reflect social biases they inherit from their training data, which is often crawled from the internet. Manually auditing models for biases can be very time and resource consuming and is further complicated by the unbounded and unconstrained nature of inputs these models can take. Research into bias measurement and quantification has generally focused on small single-stage models working on a single modality. Thus the emergence of multistage multimodal models requires a different approach. In this paper, we propose Multimodal Composite Association Score (MCAS) as a new method of measuring gender bias in multimodal generative models. Evaluating both DALL-E 2 and Stable Diffusion using this approach uncovered the presence of gendered associations of concepts embedded within the models. We propose MCAS as an accessible and scalable method of quantifying potential bias for models with different modalities and a range of potential biases.