 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased Attention: Do Vision Transformers Amplify Gender Bias More than Convolutional Neural Networks?
Paper and Code



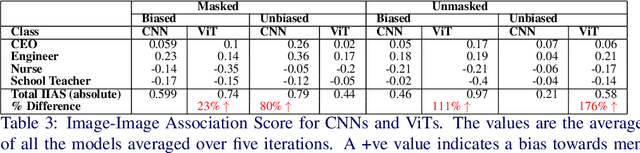
Deep neural networks used in computer vision have been shown to exhibit many social biases such as gender bias. Vision Transformers (ViTs) have become increasingly popular in computer vision applications, outperforming Convolutional Neural Networks (CNNs) in many tasks such as image classification. However, given that research on mitigating bias in computer vision has primarily focused on CNNs, it is important to evaluate the effect of a different network architecture on the potential for bias amplification. In this paper we therefore introduce a novel metric to measure bias in architectures, Accuracy Difference. We examine bias amplification when models belonging to these two architectures are used as a part of large multimodal models, evaluating the different image encoders of Contrastive Language Image Pretraining which is an important model used in many generative models such as DALL-E and Stable Diffusion. Our experiments demonstrate that architecture can play a role in amplifying social biases due to the different techniques employed by the models for feature extraction and embedding as well as their different learning properties. This research found that ViTs amplified gender bias to a greater extent than CNNs