 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs for Drug-Drug Interaction Prediction: A Comprehensive Comparison
Feb 09, 2025



The increasing volume of drug combinations in modern therapeutic regimens needs reliable methods for predicting drug-drug interactions (DDIs). While Large Language Models (LLMs) have revolutionized various domains, their potential in pharmaceutical research, particularly in DDI prediction, remains largely unexplored. This study thoroughly investigates LLMs' capabilities in predicting DDIs by uniquely processing molecular structures (SMILES), target organisms, and gene interaction data as raw text input from the latest DrugBank dataset. We evaluated 18 different LLMs, including proprietary models (GPT-4, Claude, Gemini) and open-source variants (from 1.5B to 72B parameters), first assessing their zero-shot capabilities in DDI prediction. We then fine-tuned selected models (GPT-4, Phi-3.5 2.7B, Qwen-2.5 3B, Gemma-2 9B, and Deepseek R1 distilled Qwen 1.5B) to optimize their performance. Our comprehensive evaluation framework included validation across 13 external DDI datasets, comparing against traditional approaches such as l2-regularized logistic regression. Fine-tuned LLMs demonstrated superior performance, with Phi-3.5 2.7B achieving a sensitivity of 0.978 in DDI prediction, with an accuracy of 0.919 on balanced datasets (50% positive, 50% negative cases). This result represents an improvement over both zero-shot predictions and state-of-the-art machine-learning methods used for DDI prediction. Our analysis reveals that LLMs can effectively capture complex molecular interaction patterns and cases where drug pairs target common genes, making them valuable tools for practical applications in pharmaceutical research and clinical settings.
Design and Evaluation of a CDSS for Drug Allergy Management Using LLMs and Pharmaceutical Data Integration
Sep 24, 2024



Medication errors significantly threaten patient safety, leading to adverse drug events and substantial economic burdens on healthcare systems. Clinical Decision Support Systems (CDSSs) aimed at mitigating these errors often face limitations, including reliance on static databases and rule-based algorithms, which can result in high false alert rates and alert fatigue among clinicians. This paper introduces HELIOT, an innovative CDSS for drug allergy management, integrating Large Language Models (LLMs) with a comprehensive pharmaceutical data repository. HELIOT leverages advanced natural language processing capabilities to interpret complex medical texts and synthesize unstructured data, overcoming the limitations of traditional CDSSs. An empirical evaluation using a synthetic patient dataset and expert-verified ground truth demonstrates HELIOT's high accuracy, precision, recall, and F1 score, uniformly reaching 100\% across multiple experimental runs. The results underscore HELIOT's potential to enhance decision support in clinical settings, offering a scalable, efficient, and reliable solution for managing drug allergies.
A Catalog of Fairness-Aware Practices in Machine Learning Engineering
Aug 29, 2024



Machine learning's widespread adoption in decision-making processes raises concerns about fairness, particularly regarding the treatment of sensitive features and potential discrimination against minorities. The software engineering community has responded by developing fairness-oriented metrics, empirical studies, and approaches. However, there remains a gap in understanding and categorizing practices for engineering fairness throughout the machine learning lifecycle. This paper presents a novel catalog of practices for addressing fairness in machine learning derived from a systematic mapping study. The study identifies and categorizes 28 practices from existing literature, mapping them onto different stages of the machine learning lifecycle. From this catalog, the authors extract actionable items and implications for both researchers and practitioners in software engineering. This work aims to provide a comprehensive resource for integrating fairness considerations into the development and deployment of machine learning systems, enhancing their reliability, accountability, and credibility.
Machine Learning-Based Test Smell Detection
Aug 16, 2022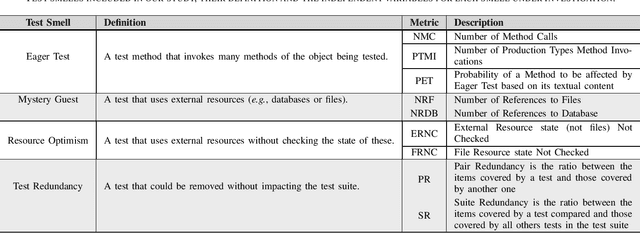
Context: Test smells are symptoms of sub-optimal design choices adopted when developing test cases. Previous studies have proved their harmfulness for test code maintainability and effectiveness. Therefore, researchers have been proposing automated, heuristic-based techniques to detect them. However, the performance of such detectors is still limited and dependent on thresholds to be tuned. Objective: We propose the design and experimentation of a novel test smell detection approach based on machine learning to detect four test smells. Method: We plan to develop the largest dataset of manually-validated test smells. This dataset will be leveraged to train six machine learners and assess their capabilities in within- and cross-project scenarios. Finally, we plan to compare our approach with state-of-the-art heuristic-based techniques.
An Approach for Parallel Genetic Algorithms in the Cloud using Software Containers
Jun 22, 2016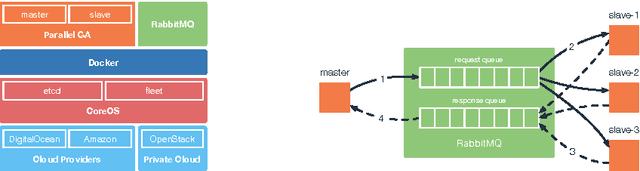
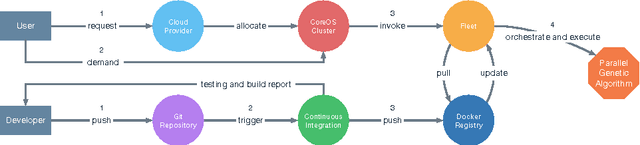
Genetic Algorithms (GAs) are a powerful technique to address hard optimisation problems. However, scalability issues might prevent them from being applied to real-world problems. Exploiting parallel GAs in the cloud might be an affordable approach to get time efficient solutions that benefit of the appealing features of the cloud, such as scalability, reliability, fault-tolerance and cost-effectiveness. Nevertheless, distributed computation is very prone to cause considerable overhead for communication and making GAs distributed in an on-demand fashion is not trivial. Aiming to keep under control the communication overhead and support GAs developers in the construction and deployment of parallel GAs in the cloud, in this paper we propose an approach to distribute GAs using the global parallelisation model, exploiting software containers and their cloud orchestration. We also devised a conceptual workflow covering each cloud GAs distribution phase, from resources allocation to actual deployment and execution, in a DevOps fashion.
A Framework for Genetic Algorithms Based on Hadoop
Dec 15, 2013
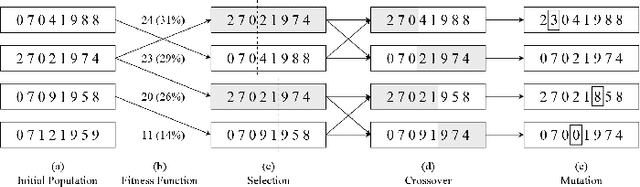
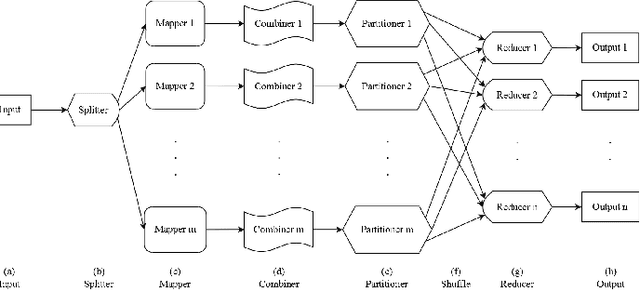
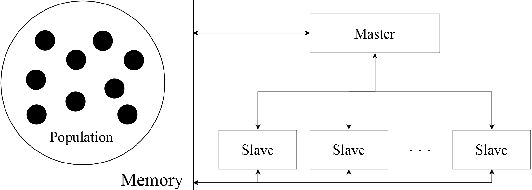
Genetic Algorithms (GAs) are powerful metaheuristic techniques mostly used in many real-world applications. The sequential execution of GAs requires considerable computational power both in time and resources. Nevertheless, GAs are naturally parallel and accessing a parallel platform such as Cloud is easy and cheap. Apache Hadoop is one of the common services that can be used for parallel applications. However, using Hadoop to develop a parallel version of GAs is not simple without facing its inner workings. Even though some sequential frameworks for GAs already exist, there is no framework supporting the development of GA applications that can be executed in parallel. In this paper is described a framework for parallel GAs on the Hadoop platform, following the paradigm of MapReduce. The main purpose of this framework is to allow the user to focus on the aspects of GA that are specific to the problem to be addressed, being sure that this task is going to be correctly executed on the Cloud with a good performance. The framework has been also exploited to develop an application for Feature Subset Selection problem. A preliminary analysis of the performance of the developed GA application has been performed using three datasets and shown very promising performance.