 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgehZACH-ViT: Curved Latent Geometry for Compact Vision Transformers in Low-Data Medical Imaging
May 30, 2026Compact Vision Transformers are attractive for medical imaging in low-data and resource-constrained settings, but most existing variants assume that Euclidean latent geometry is sufficient for organizing image representations. We introduce hZACH-ViT, a family of curved-geometry extensions of ZACH-ViT, a compact zero-token Vision Transformer that removes positional embeddings and the class token and relies on global average pooling over patch representations. To isolate the role of geometry, we preserve the verified ZACH-ViT backbone and modify only the final representation space and prototype-based classifier head, enabling a controlled comparison between Euclidean, hyperbolic, and spherical latent geometries. We evaluate Poincaré, Klein, and spherical hZACH-ViT heads on seven MedMNIST datasets under an identical few-shot protocol with 50 samples per class and five random seeds. The completed benchmark contains 770 training runs spanning seven datasets, three non-Euclidean geometries, seven curvature magnitudes, and a Euclidean baseline. Across all seven datasets, the best non-Euclidean hZACH-ViT configuration improves over Euclidean ZACH-ViT, with an average gain of +0.021 in the dataset-specific primary metric and the largest improvement on OCTMNIST (+0.055 MacroF1). Fixed low-curvature configurations retain positive gains on the majority of datasets, and low curvature values (c = 0.1 or 0.2) account for six of the seven dataset-level winners. Rather than identifying a universally optimal manifold, our results establish geometry and curvature as dataset-dependent model-selection variables, with fixed low-curvature analyses confirming that gains persist beyond exhaustive per-dataset tuning.
Machine-Learning-Enhanced Non-Invasive Testing for MASLD Fibrosis: Shallow-Deep Neural Networks Versus FIB-4, Tabular Foundation Models, and Large Language Models
May 19, 2026Advanced fibrosis is a major determinant of liver-related morbidity in metabolic dysfunction-associated steatotic liver disease (MASLD). FIB-4 is widely used as a first-line non-invasive test, but its fixed formula may underuse diagnostic information contained in age, aspartate aminotransferase, alanine aminotransferase, and platelet count. We evaluated whether machine-learning-enhanced non-invasive testing (MLE-NIT) can improve advanced fibrosis detection while preserving this FIB-4 variable space. We used three biopsy-confirmed MASLD cohorts from China, Malaysia, and India (n=784). The Chinese cohort was split into 486 training and 54 internal validation/tuning patients; final performance was reported only on the Malaysian and Indian external cohorts. Models used five variables: age, FIB-4, aspartate aminotransferase, platelet count, and alanine aminotransferase. We compared FIB-4 with a shallow-deep neural network (s-DNN), TabPFN, and gpt-4o-2024-08-06. FIB-4 achieved external ROC-AUCs of 0.75 and 0.60 in Malaysia and India, respectively. TabPFN achieved 0.69 and 0.66, fine-tuned GPT-4o achieved 0.75 and 0.63, and the s-DNN achieved 0.77 and 0.67, respectively. The s-DNN contained only 354 trainable parameters, compared with 7,244,554 for TabPFN, yet provided a more balanced external operating profile. Calibration showed s-DNN Brier scores of 0.18 and 0.22, and permutation importance identified AST and FIB-4 as dominant variables. Compact non-linear MLE-NITs may enhance FIB-4-based fibrosis assessment without increasing clinical data requirements.
Extending ZACH-ViT to Robust Medical Imaging: Corruption and Adversarial Stress Testing in Low-Data Regimes
Apr 07, 2026The recently introduced ZACH-ViT (Zero-token Adaptive Compact Hierarchical Vision Transformer) formalized a compact permutation-invariant Vision Transformer for medical imaging and argued that architectural alignment with spatial structure can matter more than universal benchmark dominance. Its design was motivated by the observation that positional embeddings and a dedicated class token encode fixed spatial assumptions that may be suboptimal when spatial organization is weakly informative, locally distributed, or variable across biomedical images. The foundational study established a regime-dependent clean performance profile across MedMNIST, but did not examine robustness in detail. In this work, we present the first robustness-focused extension of ZACH-ViT by evaluating its behavior under common image corruptions and adversarial perturbations in the same low-data setting. We compare ZACH-ViT with three scratch-trained compact baselines, ABMIL, Minimal-ViT, and TransMIL, on seven MedMNIST datasets using 50 samples per class, fixed hyperparameters, and five random seeds. Across the benchmark, ZACH-ViT achieves the best overall mean rank on clean data (1.57) and under common corruptions (1.57), indicating a favorable balance between baseline predictive performance and robustness to realistic image degradation. Under adversarial stress, all models deteriorate substantially; nevertheless, ZACH-ViT remains competitive, ranking first under FGSM (2.00) and second under PGD (2.29), where ABMIL performs best overall. These results extend the original ZACH-ViT narrative: the advantages of compact permutation-invariant transformers are not limited to clean evaluation, but can persist under realistic perturbation stress in low-data medical imaging, while adversarial robustness remains an open challenge for all evaluated models.
LLMs for Drug-Drug Interaction Prediction: A Comprehensive Comparison
Feb 09, 2025



The increasing volume of drug combinations in modern therapeutic regimens needs reliable methods for predicting drug-drug interactions (DDIs). While Large Language Models (LLMs) have revolutionized various domains, their potential in pharmaceutical research, particularly in DDI prediction, remains largely unexplored. This study thoroughly investigates LLMs' capabilities in predicting DDIs by uniquely processing molecular structures (SMILES), target organisms, and gene interaction data as raw text input from the latest DrugBank dataset. We evaluated 18 different LLMs, including proprietary models (GPT-4, Claude, Gemini) and open-source variants (from 1.5B to 72B parameters), first assessing their zero-shot capabilities in DDI prediction. We then fine-tuned selected models (GPT-4, Phi-3.5 2.7B, Qwen-2.5 3B, Gemma-2 9B, and Deepseek R1 distilled Qwen 1.5B) to optimize their performance. Our comprehensive evaluation framework included validation across 13 external DDI datasets, comparing against traditional approaches such as l2-regularized logistic regression. Fine-tuned LLMs demonstrated superior performance, with Phi-3.5 2.7B achieving a sensitivity of 0.978 in DDI prediction, with an accuracy of 0.919 on balanced datasets (50% positive, 50% negative cases). This result represents an improvement over both zero-shot predictions and state-of-the-art machine-learning methods used for DDI prediction. Our analysis reveals that LLMs can effectively capture complex molecular interaction patterns and cases where drug pairs target common genes, making them valuable tools for practical applications in pharmaceutical research and clinical settings.
Design and Evaluation of a CDSS for Drug Allergy Management Using LLMs and Pharmaceutical Data Integration
Sep 24, 2024



Medication errors significantly threaten patient safety, leading to adverse drug events and substantial economic burdens on healthcare systems. Clinical Decision Support Systems (CDSSs) aimed at mitigating these errors often face limitations, including reliance on static databases and rule-based algorithms, which can result in high false alert rates and alert fatigue among clinicians. This paper introduces HELIOT, an innovative CDSS for drug allergy management, integrating Large Language Models (LLMs) with a comprehensive pharmaceutical data repository. HELIOT leverages advanced natural language processing capabilities to interpret complex medical texts and synthesize unstructured data, overcoming the limitations of traditional CDSSs. An empirical evaluation using a synthetic patient dataset and expert-verified ground truth demonstrates HELIOT's high accuracy, precision, recall, and F1 score, uniformly reaching 100\% across multiple experimental runs. The results underscore HELIOT's potential to enhance decision support in clinical settings, offering a scalable, efficient, and reliable solution for managing drug allergies.
A data-centric approach to class-specific bias in image data augmentation
Mar 07, 2024
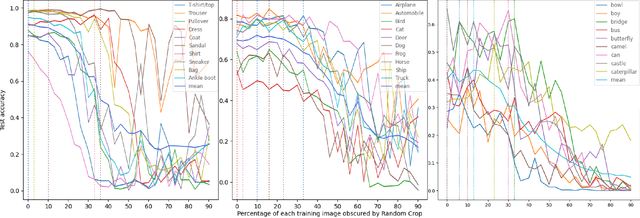
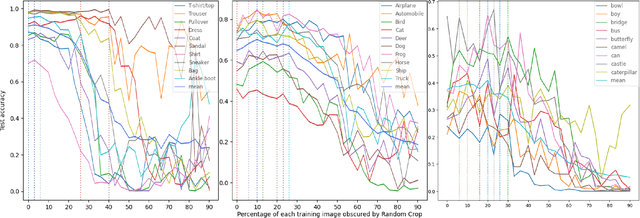
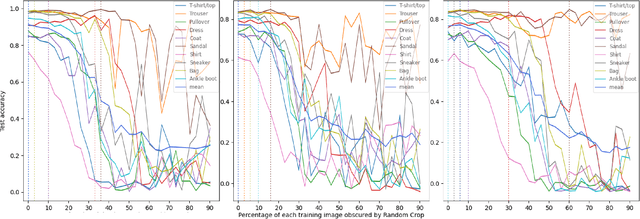
Data augmentation (DA) enhances model generalization in computer vision but may introduce biases, impacting class accuracy unevenly. Our study extends this inquiry, examining DA's class-specific bias across various datasets, including those distinct from ImageNet, through random cropping. We evaluated this phenomenon with ResNet50, EfficientNetV2S, and SWIN ViT, discovering that while residual models showed similar bias effects, Vision Transformers exhibited greater robustness or altered dynamics. This suggests a nuanced approach to model selection, emphasizing bias mitigation. We also refined a "data augmentation robustness scouting" method to manage DA-induced biases more efficiently, reducing computational demands significantly (training 112 models instead of 1860; a reduction of factor 16.2) while still capturing essential bias trends.