 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Map: Toward a New Approach Supporting the Knowledge Management in Distributed Data Mining
Oct 23, 2019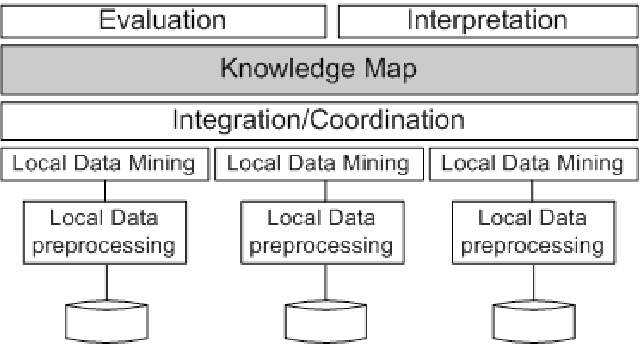
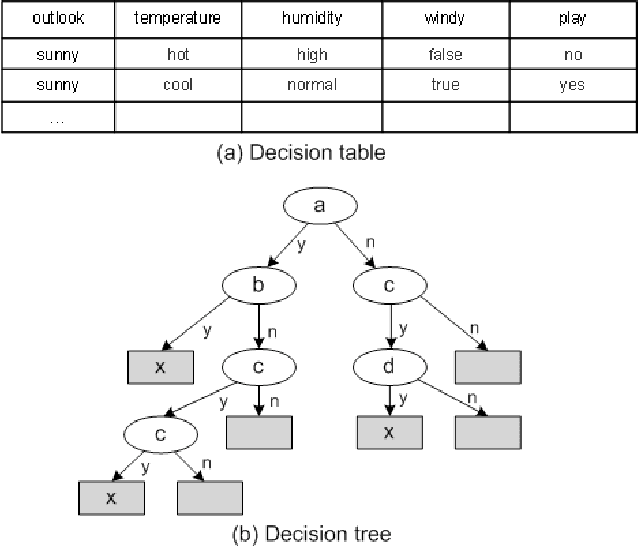
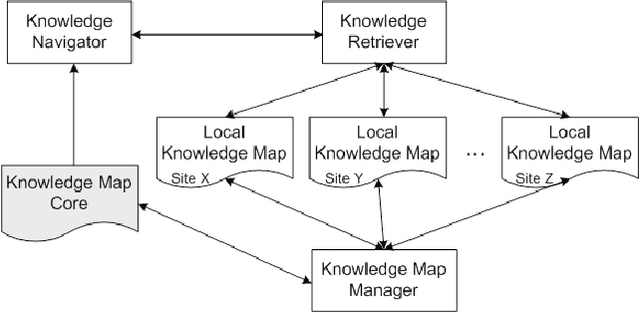
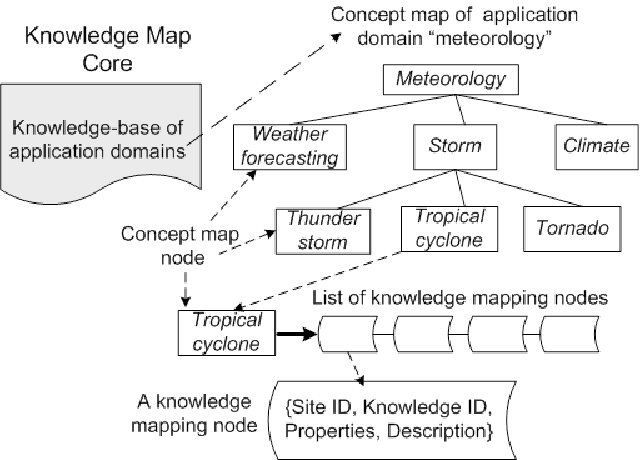
Distributed data mining (DDM) deals with the problem of finding patterns or models, called knowledge, in an environment with distributed data and computations. Today, a massive amounts of data which are often geographically distributed and owned by different organisation are being mined. As consequence, a large mount of knowledge are being produced. This causes problems of not only knowledge management but also visualization in data mining. Besides, the main aim of DDM is to exploit fully the benefit of distributed data analysis while minimising the communication. Existing DDM techniques perform partial analysis of local data at individual sites and then generate a global model by aggregating these local results. These two steps are not independent since naive approaches to local analysis may produce an incorrect and ambiguous global data model. The integrating and cooperating of these two steps need an effective knowledge management, concretely an efficient map of knowledge in order to take the advantage of mined knowledge to guide mining the data. In this paper, we present "knowledge map", a representation of knowledge about mined knowledge. This new approach aims to manage efficiently mined knowledge in large scale distributed platform such as Grid. This knowledge map is used to facilitate not only the visualization, evaluation of mining results but also the coordinating of local mining process and existing knowledge to increase the accuracy of final model.
Performance study of distributed Apriori-like frequent itemsets mining
Feb 21, 2019
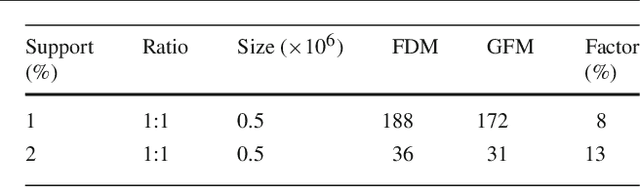


In this article, we focus on distributed Apriori-based frequent itemsets mining. We present a new distributed approach which takes into account inherent characteristics of this algorithm. We study the distribution aspect of this algorithm and give a comparison of the proposed approach with a classical Apriori-like distributed algorithm, using both analytical and experimental studies. We find that under a wide range of conditions and datasets, the performance of a distributed Apriori-like algorithm is not related to global strategies of pruning since the performance of the local Apriori generation is usually characterized by relatively high success rates of candidate sets frequency at low levels which switch to very low rates at some stage, and often drops to zero. This means that the intermediate communication steps and remote support counts computation and collection in classical distributed schemes are computationally inefficient locally, and then constrains the global performance. Our performance evaluation is done on a large cluster of workstations using the Condor system and its workflow manager DAGMan. The results show that the presented approach greatly enhances the performance and achieves good scalability compared to a typical distributed Apriori founded algorithm.