 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCursed yet Satisfied Agents
Apr 02, 2021In real life auctions, a widely observed phenomenon is the winner's curse -- the winner's high bid implies that the winner often over-estimates the value of the good for sale, resulting in an incurred negative utility. The seminal work of Eyster and Rabin [Econometrica'05] introduced a behavioral model aimed to explain this observed anomaly. We term agents who display this bias "cursed agents". We adopt their model in the interdependent value setting, and aim to devise mechanisms that prevent the cursed agents from obtaining negative utility. We design mechanisms that are cursed ex-post IC, that is, incentivize agents to bid their true signal even though they are cursed, while ensuring that the outcome is individually rational -- the price the agents pay is no more than the agents' true value. Since the agents might over-estimate the good's value, such mechanisms might require the seller to make positive transfers to the agents to prevent agents from over-paying. For revenue maximization, we give the optimal deterministic and anonymous mechanism. For welfare maximization, we require ex-post budget balance (EPBB), as positive transfers might lead to negative revenue. We propose a masking operation that takes any deterministic mechanism, and imposes that the seller would not make positive transfers, enforcing EPBB. We show that in typical settings, EPBB implies that the mechanism cannot make any positive transfers, implying that applying the masking operation on the fully efficient mechanism results in a socially optimal EPBB mechanism. This further implies that if the valuation function is the maximum of agents' signals, the optimal EPBB mechanism obtains zero welfare. In contrast, we show that for sum-concave valuations, which include weighted-sum valuations and l_p-norms, the welfare optimal EPBB mechanism obtains half of the optimal welfare as the number of agents grows large.
Reinforcement Learning of Simple Indirect Mechanisms
Oct 02, 2020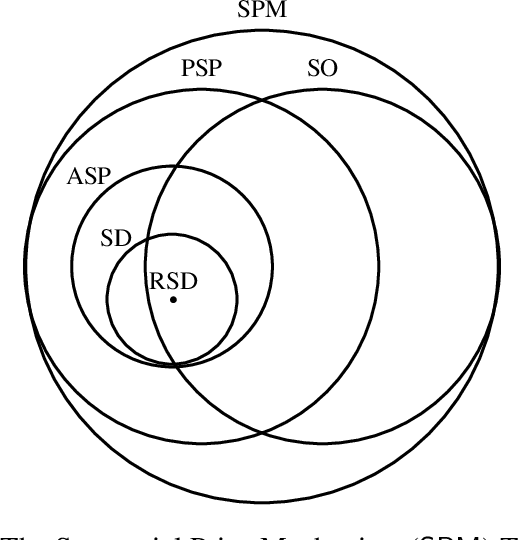

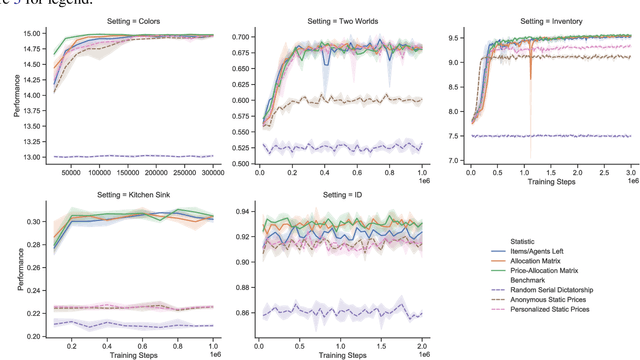
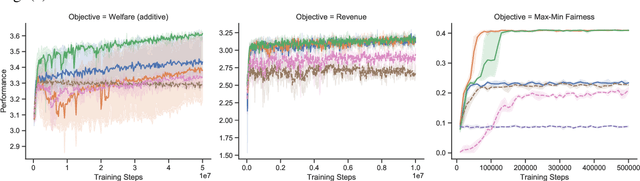
We introduce the use of reinforcement learning for indirect mechanisms, working with the existing class of {\em sequential price mechanisms}, which generalizes both serial dictatorship and posted price mechanisms and essentially characterizes all strongly obviously strategyproof mechanisms. Learning an optimal mechanism within this class forms a partially-observable Markov decision process. We provide rigorous conditions for when this class of mechanisms is more powerful than simpler static mechanisms, for sufficiency or insufficiency of observation statistics for learning, and for the necessity of complex (deep) policies. We show that our approach can learn optimal or near-optimal mechanisms in several experimental settings.