 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptArgus: A Multi-Agent System to Detect Hallucinations in LLM-based Optimization Modeling
May 12, 2026Large language models (LLMs) are increasingly used to translate natural-language optimization problems into mathematical formulations and solver code, but matching the reference objective value is not a reliable test of correctness: an artifact may agree numerically while still changing the underlying optimization semantics. We formulate this issue as \emph{optimization-modeling hallucination detection}, namely structural consistency auditing over the problem description, symbolic model, and solver implementation. We develop, to our knowledge, the first fine-grained hallucination taxonomy specifically for optimization modeling, spanning objective, variable, constraint, and implementation failures. We use this taxonomy to design OptArgus, a multi-agent detector with conductor routing, specialist auditors, and evidence consolidation. To evaluate this setting, we introduce a three-part benchmark suite with $484$ clean artifacts, $1266$ controlled injected artifacts, and $6292$ natural LLM-generated artifacts. Against a matched single-agent baseline, OptArgus produces fewer false alarms on clean artifacts, more accurate top-ranked localization on controlled single-error cases, and stronger detection on natural model outputs. Together, these contributions turn optimization-modeling hallucination detection into a concrete empirical problem and suggest that modular, taxonomy-grounded auditing is a practical route to more reliable optimization modeling.
Attentional Graph Neural Networks for Robust Massive Network Localization
Nov 28, 2023



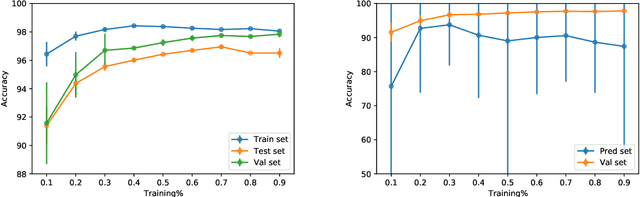
Graph neural networks (GNNs) have gained significant popularity for classification tasks in machine learning, yet their applications to regression problems remain limited. Concurrently, attention mechanisms have emerged as powerful tools in sequential learning tasks. In this paper, we employ GNNs and attention mechanisms to address a classical but challenging nonlinear regression problem: network localization. We propose a novel GNN-based network localization method that achieves exceptional stability and accuracy in the presence of severe non-line-of-sight (NLOS) propagations, while eliminating the need for laborious offline calibration or NLOS identification. Extensive experimental results validate the effectiveness and high accuracy of our GNN-based localization model, particularly in challenging NLOS scenarios. However, the proposed GNN-based model exhibits limited flexibility, and its accuracy is highly sensitive to a specific hyperparameter that determines the graph structure. To address the limitations and extend the applicability of the GNN-based model to real scenarios, we introduce two attentional graph neural networks (AGNNs) that offer enhanced flexibility and the ability to automatically learn the optimal hyperparameter for each node. Experimental results confirm that the AGNN models are able to enhance localization accuracy, providing a promising solution for real-world applications. We also provide some analyses of the improved performance achieved by the AGNN models from the perspectives of dynamic attention and signal denoising characteristics.
Machine Learning on generalized Complete Intersection Calabi-Yau Manifolds
Sep 21, 2022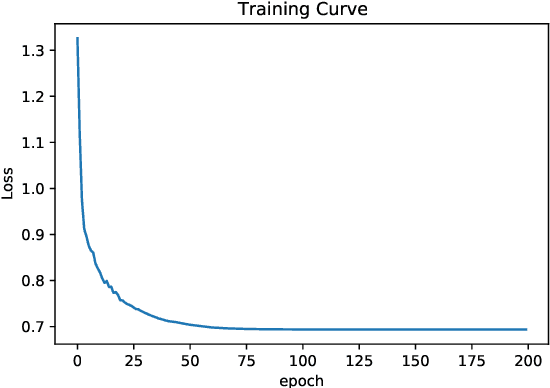
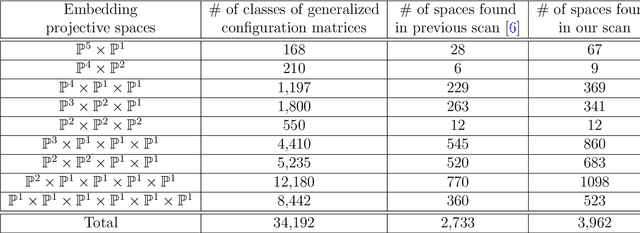
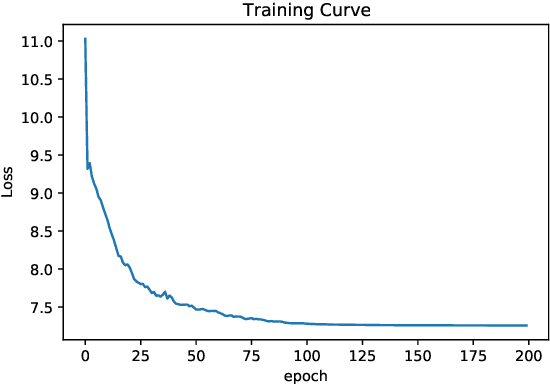
Generalized Complete Intersection Calabi-Yau Manifold (gCICY) is a new construction of Calabi-Yau manifolds established recently. However, the generation of new gCICYs using standard algebraic method is very laborious. Due to this complexity, the number of gCICYs and their classification still remain unknown. In this paper, we try to make some progress in this direction using neural network. The results showed that our trained models can have a high precision on the existing type $(1,1)$ and type $(2,1)$ gCICYs in the literature. Moreover, They can achieve a $97\%$ precision in predicting new gCICY which is generated differently from those used for training and testing. This shows that machine learning could be an effective method to classify and generate new gCICY.
Cursed yet Satisfied Agents
Apr 02, 2021In real life auctions, a widely observed phenomenon is the winner's curse -- the winner's high bid implies that the winner often over-estimates the value of the good for sale, resulting in an incurred negative utility. The seminal work of Eyster and Rabin [Econometrica'05] introduced a behavioral model aimed to explain this observed anomaly. We term agents who display this bias "cursed agents". We adopt their model in the interdependent value setting, and aim to devise mechanisms that prevent the cursed agents from obtaining negative utility. We design mechanisms that are cursed ex-post IC, that is, incentivize agents to bid their true signal even though they are cursed, while ensuring that the outcome is individually rational -- the price the agents pay is no more than the agents' true value. Since the agents might over-estimate the good's value, such mechanisms might require the seller to make positive transfers to the agents to prevent agents from over-paying. For revenue maximization, we give the optimal deterministic and anonymous mechanism. For welfare maximization, we require ex-post budget balance (EPBB), as positive transfers might lead to negative revenue. We propose a masking operation that takes any deterministic mechanism, and imposes that the seller would not make positive transfers, enforcing EPBB. We show that in typical settings, EPBB implies that the mechanism cannot make any positive transfers, implying that applying the masking operation on the fully efficient mechanism results in a socially optimal EPBB mechanism. This further implies that if the valuation function is the maximum of agents' signals, the optimal EPBB mechanism obtains zero welfare. In contrast, we show that for sum-concave valuations, which include weighted-sum valuations and l_p-norms, the welfare optimal EPBB mechanism obtains half of the optimal welfare as the number of agents grows large.
Replication Markets: Results, Lessons, Challenges and Opportunities in AI Replication
May 10, 2020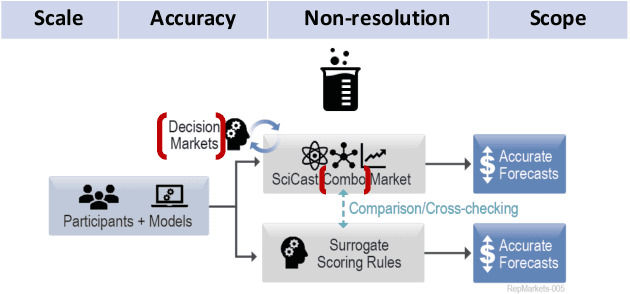

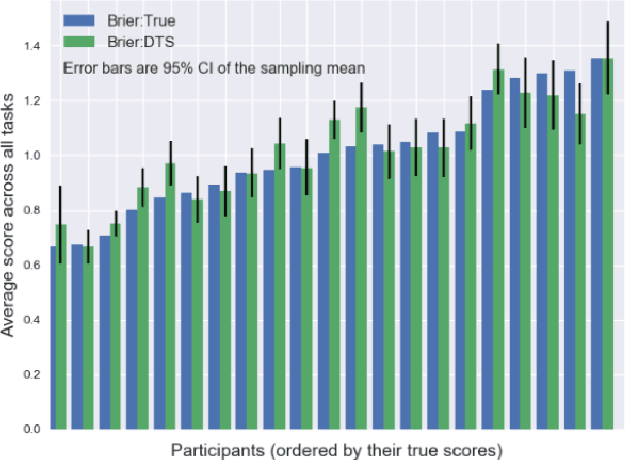
The last decade saw the emergence of systematic large-scale replication projects in the social and behavioral sciences, (Camerer et al., 2016, 2018; Ebersole et al., 2016; Klein et al., 2014, 2018; Collaboration, 2015). These projects were driven by theoretical and conceptual concerns about a high fraction of "false positives" in the scientific publications (Ioannidis, 2005) (and a high prevalence of "questionable research practices" (Simmons, Nelson, and Simonsohn, 2011). Concerns about the credibility of research findings are not unique to the behavioral and social sciences; within Computer Science, Artificial Intelligence (AI) and Machine Learning (ML) are areas of particular concern (Lucic et al., 2018; Freire, Bonnet, and Shasha, 2012; Gundersen and Kjensmo, 2018; Henderson et al., 2018). Given the pioneering role of the behavioral and social sciences in the promotion of novel methodologies to improve the credibility of research, it is a promising approach to analyze the lessons learned from this field and adjust strategies for Computer Science, AI and ML In this paper, we review approaches used in the behavioral and social sciences and in the DARPA SCORE project. We particularly focus on the role of human forecasting of replication outcomes, and how forecasting can leverage the information gained from relatively labor and resource-intensive replications. We will discuss opportunities and challenges of using these approaches to monitor and improve the credibility of research areas in Computer Science, AI, and ML.
Forecast Aggregation via Peer Prediction
Oct 09, 2019



Crowdsourcing is a popular paradigm for soliciting forecasts on future events. As people may have different forecasts, how to aggregate solicited forecasts into a single accurate prediction remains to be an important challenge, especially when no historical accuracy information is available for identifying experts. In this paper, we borrow ideas from the peer prediction literature and assess the prediction accuracy of participants using solely the collected forecasts. This approach leverages the correlations among peer reports to cross-validate each participant's forecasts and allows us to assign a "peer assessment score (PAS)" for each agent as a proxy for the agent's prediction accuracy. We identify several empirically effective methods to generate PAS and propose an aggregation framework that uses PAS to identify experts and to boost existing aggregators' prediction accuracy. We evaluate our methods over 14 real-world datasets and show that i) PAS generated from peer prediction methods can approximately reflect the prediction accuracy of agents, and ii) our aggregation framework demonstrates consistent and significant improvement in the prediction accuracy over existing aggregators for both binary and multi-choice questions under three popular accuracy measures: Brier score (mean square error), log score (cross-entropy loss) and AUC-ROC.
Randomized Wagering Mechanisms
Sep 17, 2018

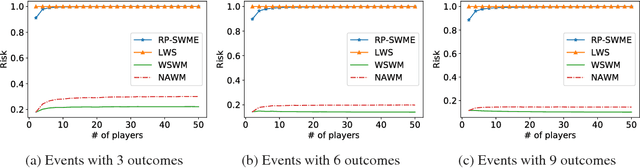
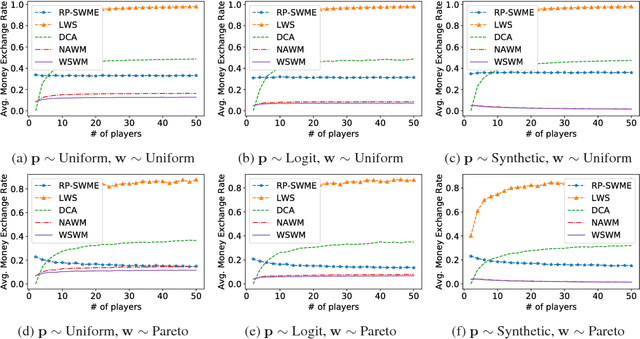
Wagering mechanisms are one-shot betting mechanisms that elicit agents' predictions of an event. For deterministic wagering mechanisms, an existing impossibility result has shown incompatibility of some desirable theoretical properties. In particular, Pareto optimality (no profitable side bet before allocation) can not be achieved together with weak incentive compatibility, weak budget balance and individual rationality. In this paper, we expand the design space of wagering mechanisms to allow randomization and ask whether there are randomized wagering mechanisms that can achieve all previously considered desirable properties, including Pareto optimality. We answer this question positively with two classes of randomized wagering mechanisms: i) one simple randomized lottery-type implementation of existing deterministic wagering mechanisms, and ii) another family of simple and randomized wagering mechanisms which we call surrogate wagering mechanisms, which are robust to noisy ground truth. This family of mechanisms builds on the idea of learning with noisy labels (Natarajan et al. 2013) as well as a recent extension of this idea to the information elicitation without verification setting (Liu and Chen 2018). We show that a broad family of randomized wagering mechanisms satisfy all desirable theoretical properties.