 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Pair of GloVes
Jul 24, 2025This report documents, describes, and evaluates new 2024 English GloVe (Global Vectors for Word Representation) models. While the original GloVe models built in 2014 have been widely used and found useful, languages and the world continue to evolve and we thought that current usage could benefit from updated models. Moreover, the 2014 models were not carefully documented as to the exact data versions and preprocessing that were used, and we rectify this by documenting these new models. We trained two sets of word embeddings using Wikipedia, Gigaword, and a subset of Dolma. Evaluation through vocabulary comparison, direct testing, and NER tasks shows that the 2024 vectors incorporate new culturally and linguistically relevant words, perform comparably on structural tasks like analogy and similarity, and demonstrate improved performance on recent, temporally dependent NER datasets such as non-Western newswire data.
Do "English" Named Entity Recognizers Work Well on Global Englishes?
Apr 20, 2024



The vast majority of the popular English named entity recognition (NER) datasets contain American or British English data, despite the existence of many global varieties of English. As such, it is unclear whether they generalize for analyzing use of English globally. To test this, we build a newswire dataset, the Worldwide English NER Dataset, to analyze NER model performance on low-resource English variants from around the world. We test widely used NER toolkits and transformer models, including models using the pre-trained contextual models RoBERTa and ELECTRA, on three datasets: a commonly used British English newswire dataset, CoNLL 2003, a more American focused dataset OntoNotes, and our global dataset. All models trained on the CoNLL or OntoNotes datasets experienced significant performance drops-over 10 F1 in some cases-when tested on the Worldwide English dataset. Upon examination of region-specific errors, we observe the greatest performance drops for Oceania and Africa, while Asia and the Middle East had comparatively strong performance. Lastly, we find that a combined model trained on the Worldwide dataset and either CoNLL or OntoNotes lost only 1-2 F1 on both test sets.
Systematicity in GPT-3's Interpretation of Novel English Noun Compounds
Oct 18, 2022

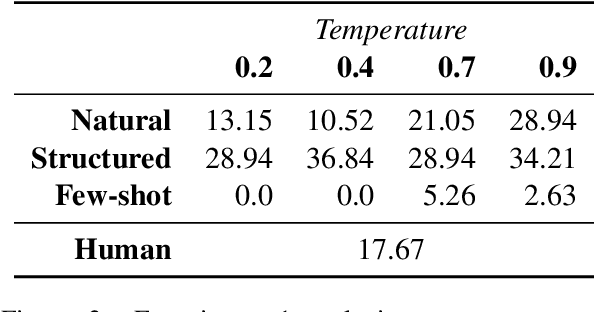

Levin et al. (2019) show experimentally that the interpretations of novel English noun compounds (e.g., stew skillet), while not fully compositional, are highly predictable based on whether the modifier and head refer to artifacts or natural kinds. Is the large language model GPT-3 governed by the same interpretive principles? To address this question, we first compare Levin et al.'s experimental data with GPT-3 generations, finding a high degree of similarity. However, this evidence is consistent with GPT3 reasoning only about specific lexical items rather than the more abstract conceptual categories of Levin et al.'s theory. To probe more deeply, we construct prompts that require the relevant kind of conceptual reasoning. Here, we fail to find convincing evidence that GPT-3 is reasoning about more than just individual lexical items. These results highlight the importance of controlling for low-level distributional regularities when assessing whether a large language model latently encodes a deeper theory.