 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Detection and Annotation of Sperm Whale Codas
Jul 24, 2024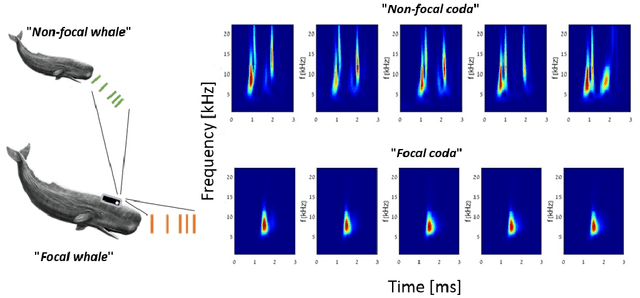

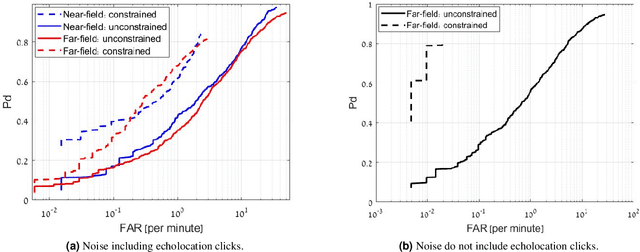
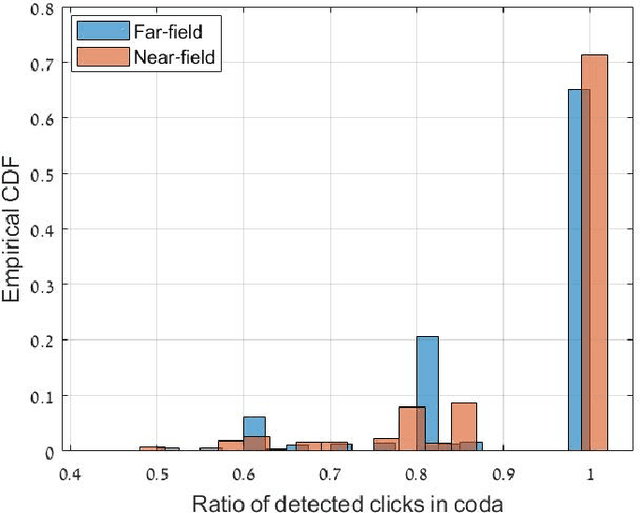
A key technology in sperm whale (Physeter macrocephalus) monitoring is the identification of sperm whale communication signals, known as codas. In this paper we present the first automatic coda detector and annotator. The main innovation in our detector is graph-based clustering, which utilizes the expected similarity between the clicks that make up the coda. Results show detection and accurate annotation at low signal-to-noise ratios, separation between codas and echolocation clicks, and discrimination between codas from simultaneously emitting whales. Using this automatic annotator, insights into the characterization of sperm whale communication are presented. The results include new types of coda signals, analyzes of the distribution of coda types among different whales and for different years, and evidence for synchronization between communicating whales in terms of coda type and coda transmission time. These results indicate a high degree of complexity in the communication system of this cetacean species. To ensure traceability, we share the implementation code of our coda detector.
A Theory of Unsupervised Translation Motivated by Understanding Animal Communication
Nov 20, 2022Recent years have seen breakthroughs in neural language models that capture nuances of language, culture, and knowledge. Neural networks are capable of translating between languages -- in some cases even between two languages where there is little or no access to parallel translations, in what is known as Unsupervised Machine Translation (UMT). Given this progress, it is intriguing to ask whether machine learning tools can ultimately enable understanding animal communication, particularly that of highly intelligent animals. Our work is motivated by an ambitious interdisciplinary initiative, Project CETI, which is collecting a large corpus of sperm whale communications for machine analysis. We propose a theoretical framework for analyzing UMT when no parallel data are available and when it cannot be assumed that the source and target corpora address related subject domains or posses similar linguistic structure. The framework requires access to a prior probability distribution that should assign non-zero probability to possible translations. We instantiate our framework with two models of language. Our analysis suggests that accuracy of translation depends on the complexity of the source language and the amount of ``common ground'' between the source language and target prior. We also prove upper bounds on the amount of data required from the source language in the unsupervised setting as a function of the amount of data required in a hypothetical supervised setting. Surprisingly, our bounds suggest that the amount of source data required for unsupervised translation is comparable to the supervised setting. For one of the language models which we analyze we also prove a nearly matching lower bound. Our analysis is purely information-theoretic and as such can inform how much source data needs to be collected, but does not yield a computationally efficient procedure.
Cetacean Translation Initiative: a roadmap to deciphering the communication of sperm whales
Apr 17, 2021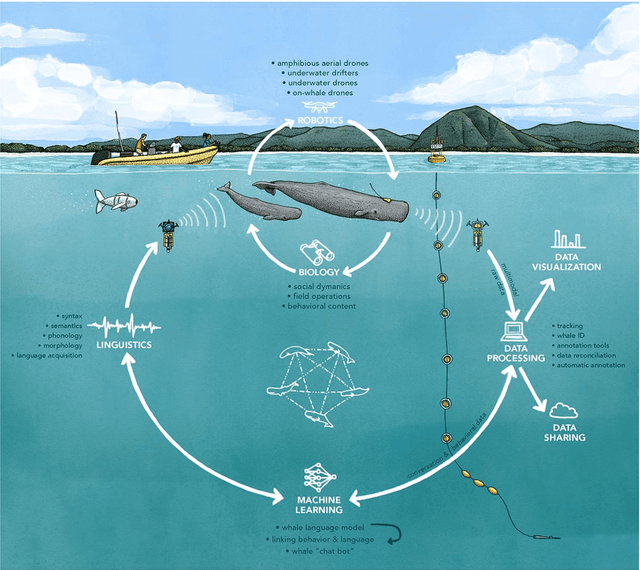
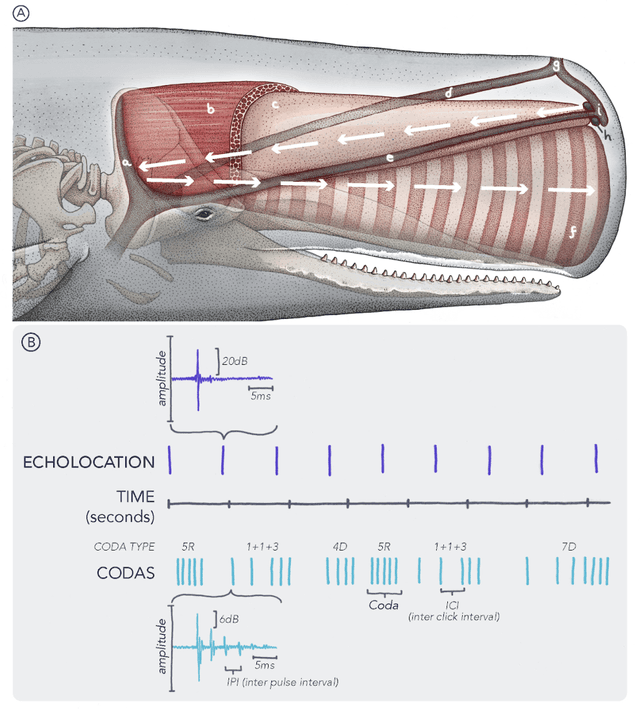

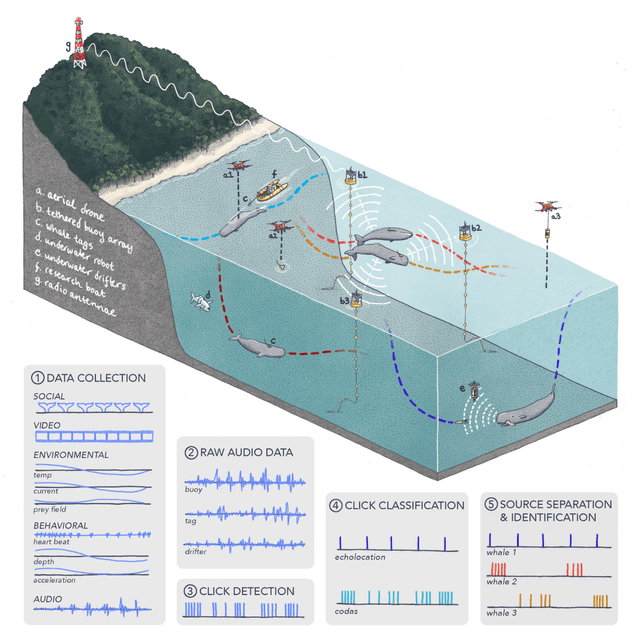
The past decade has witnessed a groundbreaking rise of machine learning for human language analysis, with current methods capable of automatically accurately recovering various aspects of syntax and semantics - including sentence structure and grounded word meaning - from large data collections. Recent research showed the promise of such tools for analyzing acoustic communication in nonhuman species. We posit that machine learning will be the cornerstone of future collection, processing, and analysis of multimodal streams of data in animal communication studies, including bioacoustic, behavioral, biological, and environmental data. Cetaceans are unique non-human model species as they possess sophisticated acoustic communications, but utilize a very different encoding system that evolved in an aquatic rather than terrestrial medium. Sperm whales, in particular, with their highly-developed neuroanatomical features, cognitive abilities, social structures, and discrete click-based encoding make for an excellent starting point for advanced machine learning tools that can be applied to other animals in the future. This paper details a roadmap toward this goal based on currently existing technology and multidisciplinary scientific community effort. We outline the key elements required for the collection and processing of massive bioacoustic data of sperm whales, detecting their basic communication units and language-like higher-level structures, and validating these models through interactive playback experiments. The technological capabilities developed by such an undertaking are likely to yield cross-applications and advancements in broader communities investigating non-human communication and animal behavioral research.