 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Non-Invasive Deep Learning Framework for Progressive Prediction of Seizures
Oct 26, 2024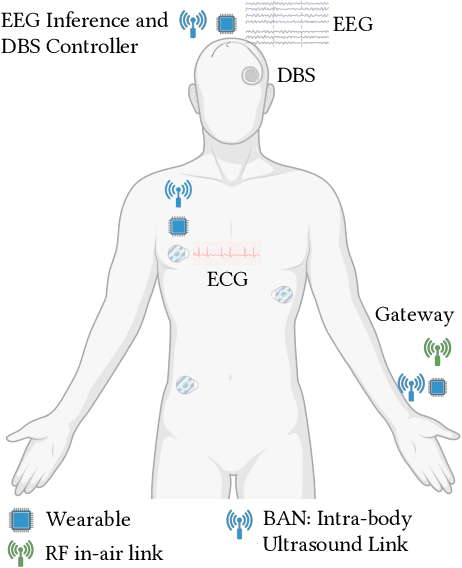

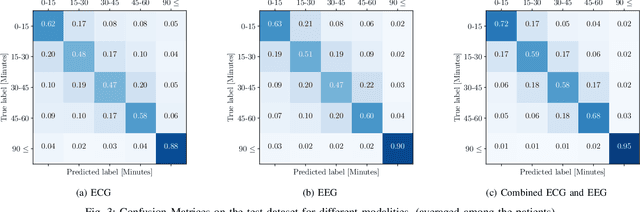
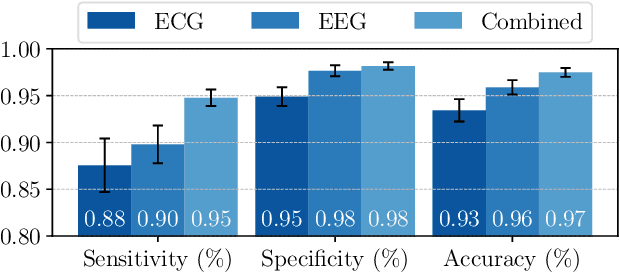
This paper introduces an innovative framework designed for progressive (granular in time to onset) prediction of seizures through the utilization of a Deep Learning (DL) methodology based on non-invasive multi-modal sensor networks. Epilepsy, a debilitating neurological condition, affects an estimated 65 million individuals globally, with a substantial proportion facing drug-resistant epilepsy despite pharmacological interventions. To address this challenge, we advocate for predictive systems that provide timely alerts to individuals at risk, enabling them to take precautionary actions. Our framework employs advanced DL techniques and uses personalized data from a network of non-invasive electroencephalogram (EEG) and electrocardiogram (ECG) sensors, thereby enhancing prediction accuracy. The algorithms are optimized for real-time processing on edge devices, mitigating privacy concerns and minimizing data transmission overhead inherent in cloud-based solutions, ultimately preserving battery energy. Additionally, our system predicts the countdown time to seizures (with 15-minute intervals up to an hour prior to the onset), offering critical lead time for preventive actions. Our multi-modal model achieves 95% sensitivity, 98% specificity, and 97% accuracy, averaged among 29 patients.
SeizNet: An AI-enabled Implantable Sensor Network System for Seizure Prediction
Jan 12, 2024



In this paper, we introduce SeizNet, a closed-loop system for predicting epileptic seizures through the use of Deep Learning (DL) method and implantable sensor networks. While pharmacological treatment is effective for some epilepsy patients (with ~65M people affected worldwide), one out of three suffer from drug-resistant epilepsy. To alleviate the impact of seizure, predictive systems have been developed that can notify such patients of an impending seizure, allowing them to take precautionary measures. SeizNet leverages DL techniques and combines data from multiple recordings, specifically intracranial electroencephalogram (iEEG) and electrocardiogram (ECG) sensors, that can significantly improve the specificity of seizure prediction while preserving very high levels of sensitivity. SeizNet DL algorithms are designed for efficient real-time execution at the edge, minimizing data privacy concerns, data transmission overhead, and power inefficiencies associated with cloud-based solutions. Our results indicate that SeizNet outperforms traditional single-modality and non-personalized prediction systems in all metrics, achieving up to 99% accuracy in predicting seizure, offering a promising new avenue in refractory epilepsy treatment.
A Review of Repository Level Prompting for LLMs
Dec 15, 2023As coding challenges become more complex, recent advancements in Large Language Models (LLMs) have led to notable successes, such as achieving a 94.6\% solve rate on the HumanEval benchmark. Concurrently, there is an increasing commercial push for repository-level inline code completion tools, such as GitHub Copilot and Tab Nine, aimed at enhancing developer productivity. This paper delves into the transition from individual coding problems to repository-scale solutions, presenting a thorough review of the current literature on effective LLM prompting for code generation at the repository level. We examine approaches that will work with black-box LLMs such that they will be useful and applicable to commercial use cases, and their applicability in interpreting code at a repository scale. We juxtapose the Repository-Level Prompt Generation technique with RepoCoder, an iterative retrieval and generation method, to highlight the trade-offs inherent in each approach and to establish best practices for their application in cutting-edge coding benchmarks. The interplay between iterative refinement of prompts and the development of advanced retrieval systems forms the core of our discussion, offering a pathway to significantly improve LLM performance in code generation tasks. Insights from this study not only guide the application of these methods but also chart a course for future research to integrate such techniques into broader software engineering contexts.
Testing Language Model Agents Safely in the Wild
Dec 03, 2023A prerequisite for safe autonomy-in-the-wild is safe testing-in-the-wild. Yet real-world autonomous tests face several unique safety challenges, both due to the possibility of causing harm during a test, as well as the risk of encountering new unsafe agent behavior through interactions with real-world and potentially malicious actors. We propose a framework for conducting safe autonomous agent tests on the open internet: agent actions are audited by a context-sensitive monitor that enforces a stringent safety boundary to stop an unsafe test, with suspect behavior ranked and logged to be examined by humans. We design a basic safety monitor (AgentMonitor) that is flexible enough to monitor existing LLM agents, and, using an adversarial simulated agent, we measure its ability to identify and stop unsafe situations. Then we apply the AgentMonitor on a battery of real-world tests of AutoGPT, and we identify several limitations and challenges that will face the creation of safe in-the-wild tests as autonomous agents grow more capable.