Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Multi-Selection among Subjective Features
Paper and Code
May 14, 2013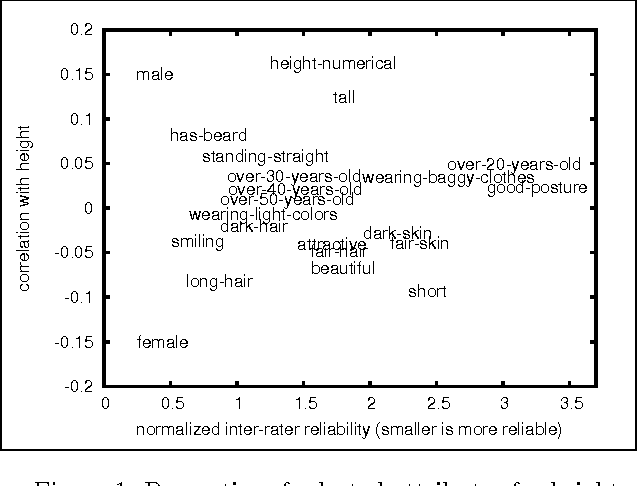
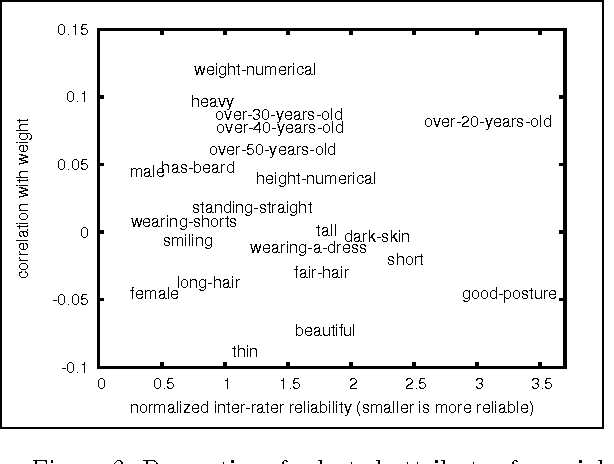
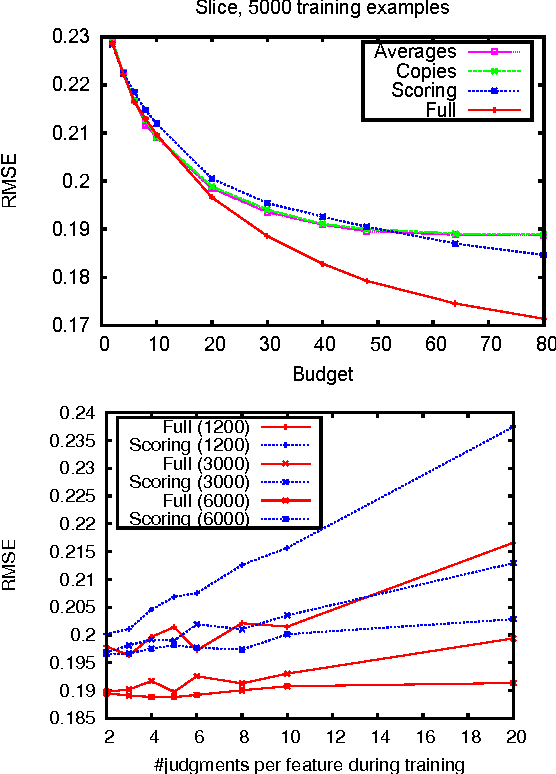
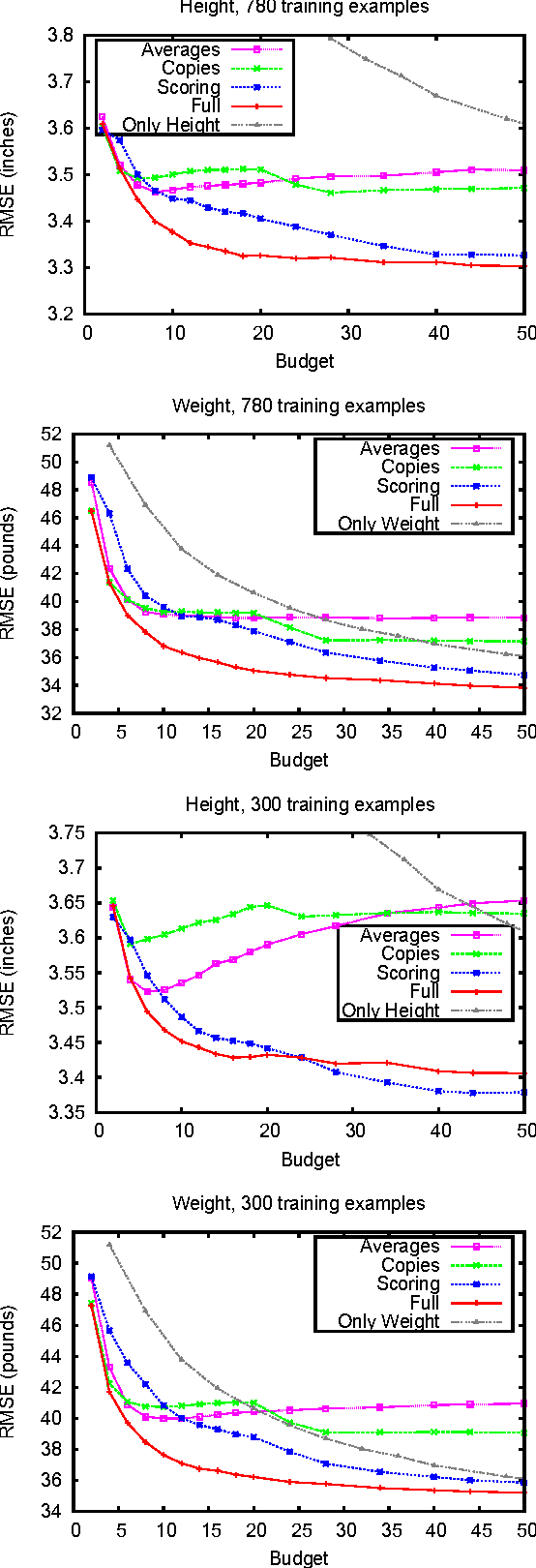
When dealing with subjective, noisy, or otherwise nebulous features, the "wisdom of crowds" suggests that one may benefit from multiple judgments of the same feature on the same object. We give theoretically-motivated `feature multi-selection' algorithms that choose, among a large set of candidate features, not only which features to judge but how many times to judge each one. We demonstrate the effectiveness of this approach for linear regression on a crowdsourced learning task of predicting people's height and weight from photos, using features such as 'gender' and 'estimated weight' as well as culturally fraught ones such as 'attractive'.
* S. Sabato and A. Kalai, "Feature Multi-Selection among Subjective
Features", Proceedings of the 30th International Conference on Machine
Learning (ICML), 2013
View paper on