 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoicesing 2: A High-Fidelity Singing Voice Synthesizer Based on Generative Adversarial Network
Paper and Code
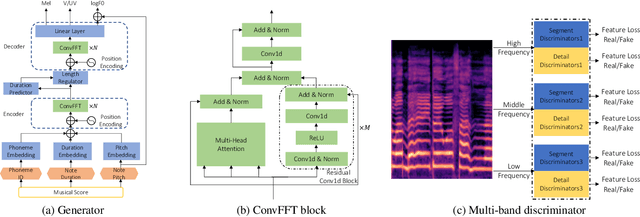


XiaoiceSing is a singing voice synthesis (SVS) system that aims at generating 48kHz singing voices. However, the mel-spectrogram generated by it is over-smoothing in middle- and high-frequency areas due to no special design for modeling the details of these parts. In this paper, we propose XiaoiceSing2, which can generate the details of middle- and high-frequency parts to better construct the full-band mel-spectrogram. Specifically, in order to alleviate this problem, XiaoiceSing2 adopts a generative adversarial network (GAN), which consists of a FastSpeech-based generator and a multi-band discriminator. We improve the feed-forward Transformer (FFT) block by adding multiple residual convolutional blocks in parallel with the self-attention block to balance the local and global features. The multi-band discriminator contains three sub-discriminators responsible for low-, middle-, and high-frequency parts of the mel-spectrogram, respectively. Each sub-discriminator is composed of several segment discriminators (SD) and detail discriminators (DD) to distinguish the audio from different aspects. The experiment on our internal 48kHz singing voice dataset shows XiaoiceSing2 significantly improves the quality of the singing voice over XiaoiceSing.