 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTR-GAN: Topology Ranking GAN with Triplet Loss for Retinal Artery/Vein Classification
Jul 29, 2020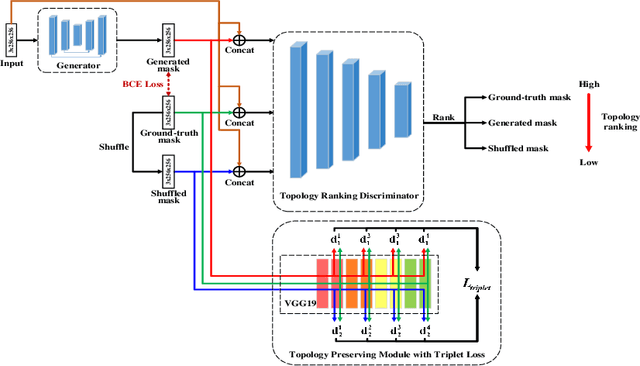
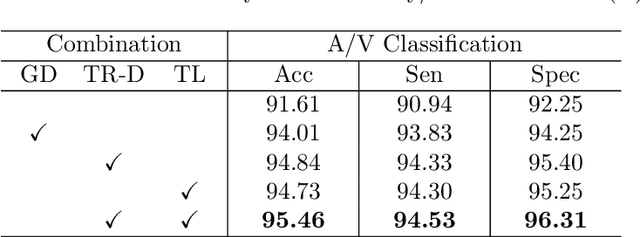
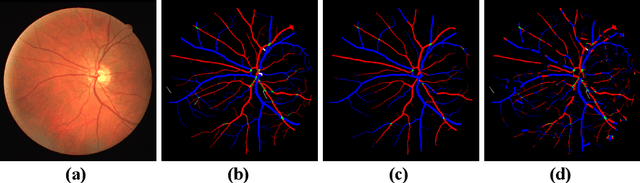
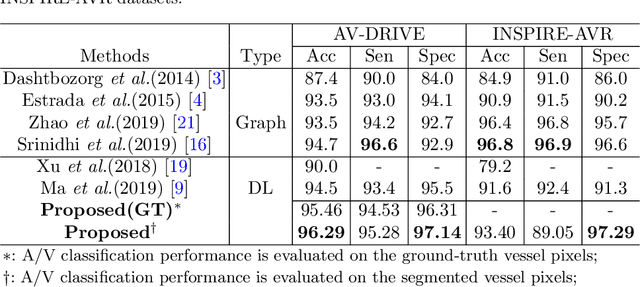
Retinal artery/vein (A/V) classification lays the foundation for the quantitative analysis of retinal vessels, which is associated with potential risks of various cardiovascular and cerebral diseases. The topological connection relationship, which has been proved effective in improving the A/V classification performance for the conventional graph based method, has not been exploited by the deep learning based method. In this paper, we propose a Topology Ranking Generative Adversarial Network (TR-GAN) to improve the topology connectivity of the segmented arteries and veins, and further to boost the A/V classification performance. A topology ranking discriminator based on ordinal regression is proposed to rank the topological connectivity level of the ground-truth, the generated A/V mask and the intentionally shuffled mask. The ranking loss is further back-propagated to the generator to generate better connected A/V masks. In addition, a topology preserving module with triplet loss is also proposed to extract the high-level topological features and further to narrow the feature distance between the predicted A/V mask and the ground-truth. The proposed framework effectively increases the topological connectivity of the predicted A/V masks and achieves state-of-the-art A/V classification performance on the publicly available AV-DRIVE dataset.
Difficulty-aware Glaucoma Classification with Multi-Rater Consensus Modeling
Jul 29, 2020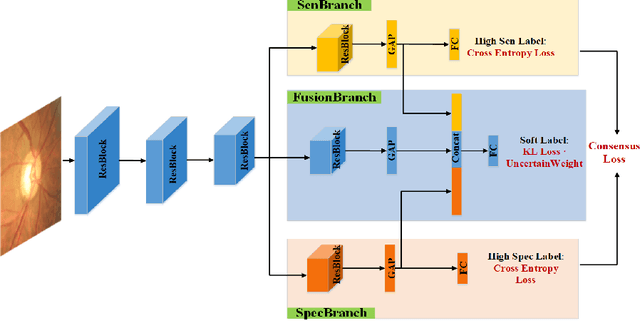
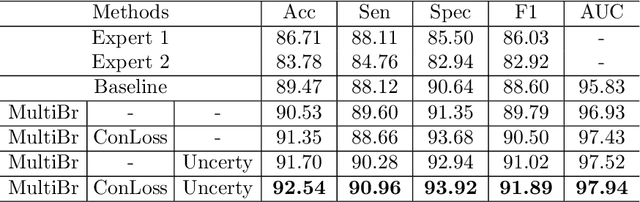
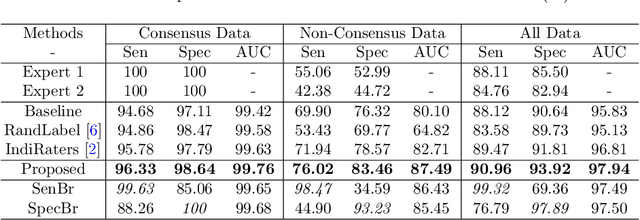
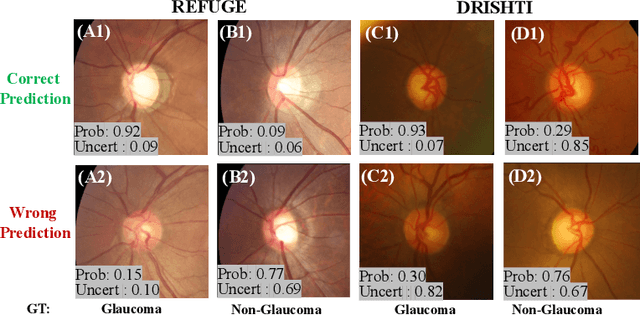
Medical images are generally labeled by multiple experts before the final ground-truth labels are determined. Consensus or disagreement among experts regarding individual images reflects the gradeability and difficulty levels of the image. However, when being used for model training, only the final ground-truth label is utilized, while the critical information contained in the raw multi-rater gradings regarding the image being an easy/hard case is discarded. In this paper, we aim to take advantage of the raw multi-rater gradings to improve the deep learning model performance for the glaucoma classification task. Specifically, a multi-branch model structure is proposed to predict the most sensitive, most specifical and a balanced fused result for the input images. In order to encourage the sensitivity branch and specificity branch to generate consistent results for consensus labels and opposite results for disagreement labels, a consensus loss is proposed to constrain the output of the two branches. Meanwhile, the consistency/inconsistency between the prediction results of the two branches implies the image being an easy/hard case, which is further utilized to encourage the balanced fusion branch to concentrate more on the hard cases. Compared with models trained only with the final ground-truth labels, the proposed method using multi-rater consensus information has achieved superior performance, and it is also able to estimate the difficulty levels of individual input images when making the prediction.