 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA ResNet is All You Need? Modeling A Strong Baseline for Detecting Referable Diabetic Retinopathy in Fundus Images
Oct 06, 2022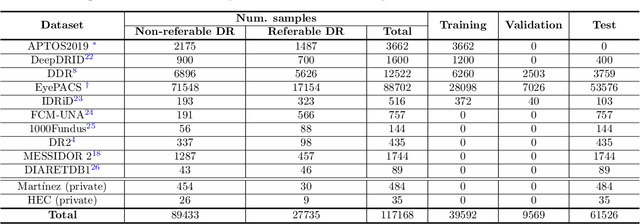

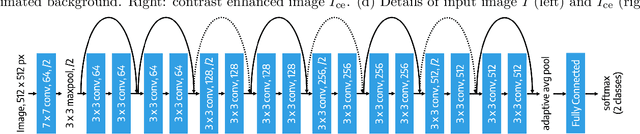
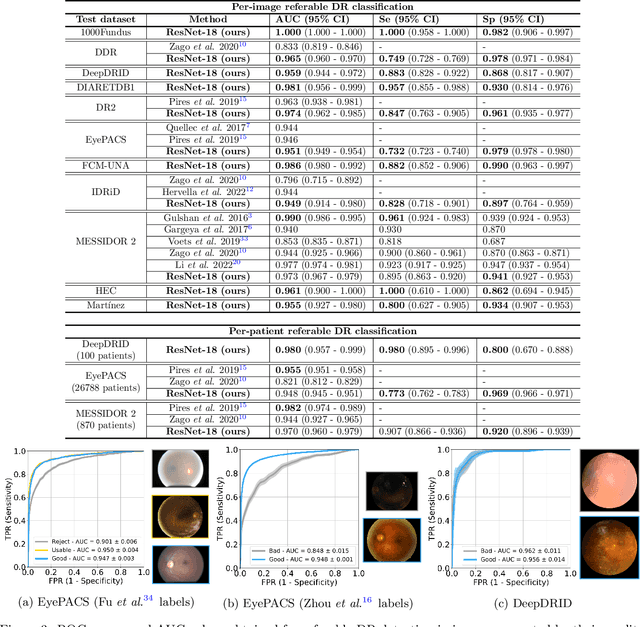
Deep learning is currently the state-of-the-art for automated detection of referable diabetic retinopathy (DR) from color fundus photographs (CFP). While the general interest is put on improving results through methodological innovations, it is not clear how good these approaches perform compared to standard deep classification models trained with the appropriate settings. In this paper we propose to model a strong baseline for this task based on a simple and standard ResNet-18 architecture. To this end, we built on top of prior art by training the model with a standard preprocessing strategy but using images from several public sources and an empirically calibrated data augmentation setting. To evaluate its performance, we covered multiple clinically relevant perspectives, including image and patient level DR screening, discriminating responses by input quality and DR grade, assessing model uncertainties and analyzing its results in a qualitative manner. With no other methodological innovation than a carefully designed training, our ResNet model achieved an AUC = 0.955 (0.953 - 0.956) on a combined test set of 61007 test images from different public datasets, which is in line or even better than what other more complex deep learning models reported in the literature. Similar AUC values were obtained in 480 images from two separate in-house databases specially prepared for this study, which emphasize its generalization ability. This confirms that standard networks can still be strong baselines for this task if properly trained.
Assessing Coarse-to-Fine Deep Learning Models for Optic Disc and Cup Segmentation in Fundus Images
Sep 28, 2022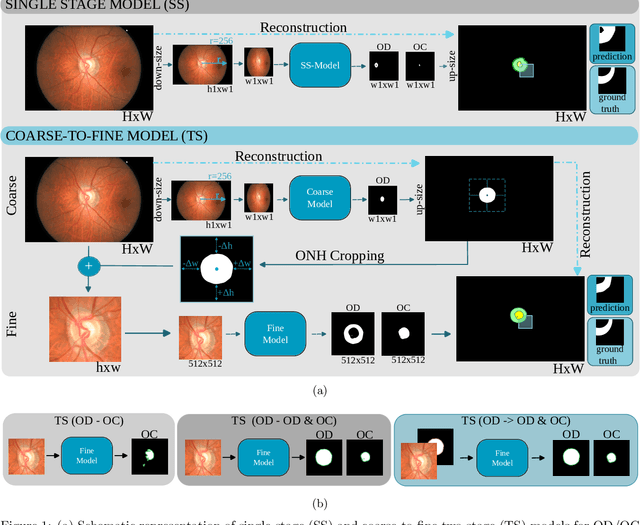
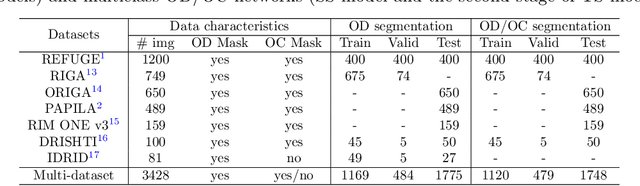
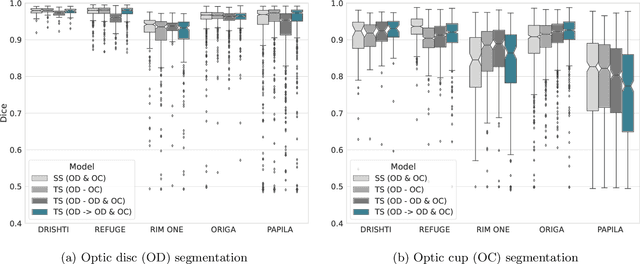
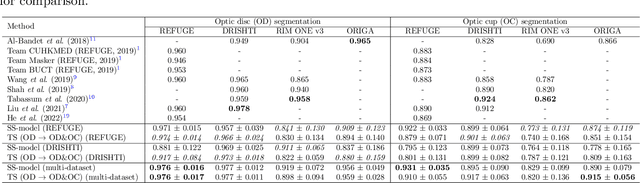
Automated optic disc (OD) and optic cup (OC) segmentation in fundus images is relevant to efficiently measure the vertical cup-to-disc ratio (vCDR), a biomarker commonly used in ophthalmology to determine the degree of glaucomatous optic neuropathy. In general this is solved using coarse-to-fine deep learning algorithms in which a first stage approximates the OD and a second one uses a crop of this area to predict OD/OC masks. While this approach is widely applied in the literature, there are no studies analyzing its real contribution to the results. In this paper we present a comprehensive analysis of different coarse-to-fine designs for OD/OC segmentation using 5 public databases, both from a standard segmentation perspective and for estimating the vCDR for glaucoma assessment. Our analysis shows that these algorithms not necessarily outperfom standard multi-class single-stage models, especially when these are learned from sufficiently large and diverse training sets. Furthermore, we noticed that the coarse stage achieves better OD segmentation results than the fine one, and that providing OD supervision to the second stage is essential to ensure accurate OC masks. Moreover, both the single-stage and two-stage models trained on a multi-dataset setting showed results in pair or even better than other state-of-the-art alternatives, while ranking first in REFUGE for OD/OC segmentation. Finally, we evaluated the models for vCDR prediction in comparison with six ophthalmologists on a subset of AIROGS images, to understand them in the context of inter-observer variability. We noticed that vCDR estimates recovered both from single-stage and coarse-to-fine models can obtain good glaucoma detection results even when they are not highly correlated with manual measurements from experts.