 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating sleep-stage classification: how age and early-late sleep affects classification performance
Oct 20, 2023



Sleep stage classification is a common method used by experts to monitor the quantity and quality of sleep in humans, but it is a time-consuming and labour-intensive task with high inter- and intra-observer variability. Using Wavelets for feature extraction and Random Forest for classification, an automatic sleep-stage classification method was sought and assessed. The age of the subjects, as well as the moment of sleep (early-night and late-night), were confronted to the performance of the classifier. From this study, we observed that these variables do affect the automatic model performance, improving the classification of some sleep stages and worsening others.
Learning normal asymmetry representations for homologous brain structures
Jun 27, 2023Although normal homologous brain structures are approximately symmetrical by definition, they also have shape differences due to e.g. natural ageing. On the other hand, neurodegenerative conditions induce their own changes in this asymmetry, making them more pronounced or altering their location. Identifying when these alterations are due to a pathological deterioration is still challenging. Current clinical tools rely either on subjective evaluations, basic volume measurements or disease-specific deep learning models. This paper introduces a novel method to learn normal asymmetry patterns in homologous brain structures based on anomaly detection and representation learning. Our framework uses a Siamese architecture to map 3D segmentations of left and right hemispherical sides of a brain structure to a normal asymmetry embedding space, learned using a support vector data description objective. Being trained using healthy samples only, it can quantify deviations-from-normal-asymmetry patterns in unseen samples by measuring the distance of their embeddings to the center of the learned normal space. We demonstrate in public and in-house sets that our method can accurately characterize normal asymmetries and detect pathological alterations due to Alzheimer's disease and hippocampal sclerosis, even though no diseased cases were accessed for training. Our source code is available at https://github.com/duiliod/DeepNORHA.
A ResNet is All You Need? Modeling A Strong Baseline for Detecting Referable Diabetic Retinopathy in Fundus Images
Oct 06, 2022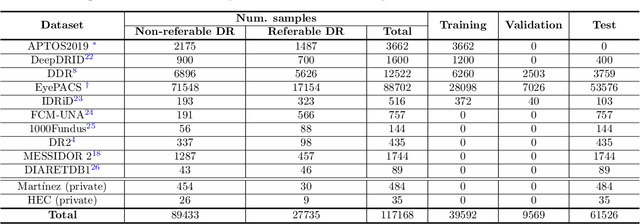

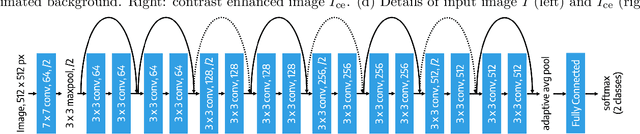
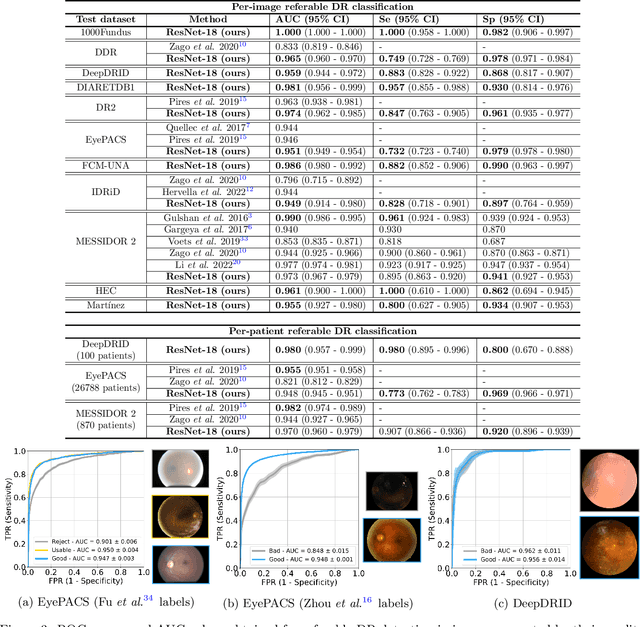
Deep learning is currently the state-of-the-art for automated detection of referable diabetic retinopathy (DR) from color fundus photographs (CFP). While the general interest is put on improving results through methodological innovations, it is not clear how good these approaches perform compared to standard deep classification models trained with the appropriate settings. In this paper we propose to model a strong baseline for this task based on a simple and standard ResNet-18 architecture. To this end, we built on top of prior art by training the model with a standard preprocessing strategy but using images from several public sources and an empirically calibrated data augmentation setting. To evaluate its performance, we covered multiple clinically relevant perspectives, including image and patient level DR screening, discriminating responses by input quality and DR grade, assessing model uncertainties and analyzing its results in a qualitative manner. With no other methodological innovation than a carefully designed training, our ResNet model achieved an AUC = 0.955 (0.953 - 0.956) on a combined test set of 61007 test images from different public datasets, which is in line or even better than what other more complex deep learning models reported in the literature. Similar AUC values were obtained in 480 images from two separate in-house databases specially prepared for this study, which emphasize its generalization ability. This confirms that standard networks can still be strong baselines for this task if properly trained.
A deep learning model for brain vessel segmentation in 3DRA with arteriovenous malformations
Oct 05, 2022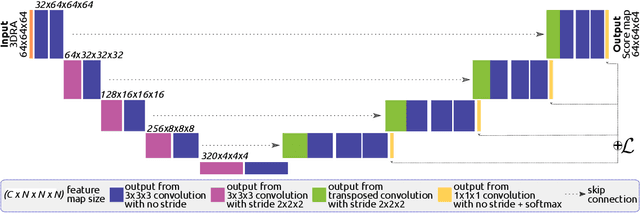
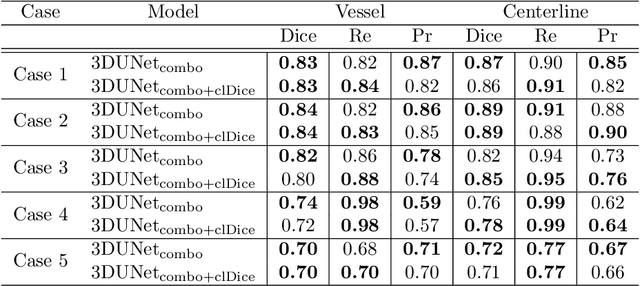
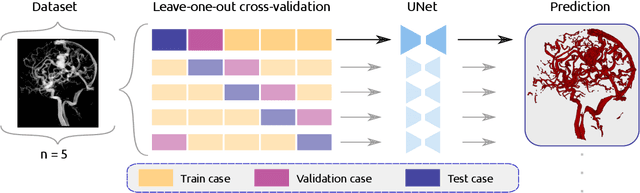

Segmentation of brain arterio-venous malformations (bAVMs) in 3D rotational angiographies (3DRA) is still an open problem in the literature, with high relevance for clinical practice. While deep learning models have been applied for segmenting the brain vasculature in these images, they have never been used in cases with bAVMs. This is likely caused by the difficulty to obtain sufficiently annotated data to train these approaches. In this paper we introduce a first deep learning model for blood vessel segmentation in 3DRA images of patients with bAVMs. To this end, we densely annotated 5 3DRA volumes of bAVM cases and used these to train two alternative 3DUNet-based architectures with different segmentation objectives. Our results show that the networks reach a comprehensive coverage of relevant structures for bAVM analysis, much better than what is obtained using standard methods. This is promising for achieving a better topological and morphological characterisation of the bAVM structures of interest. Furthermore, the models have the ability to segment venous structures even when missing in the ground truth labelling, which is relevant for planning interventional treatments. Ultimately, these results could be used as more reliable first initial guesses, alleviating the cumbersome task of creating manual labels.
Assessing Coarse-to-Fine Deep Learning Models for Optic Disc and Cup Segmentation in Fundus Images
Sep 28, 2022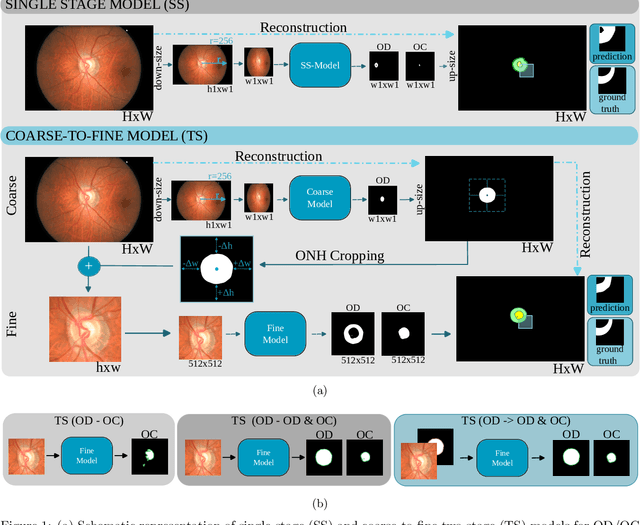
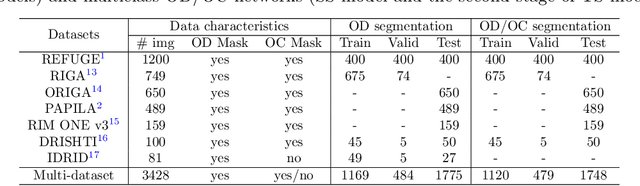
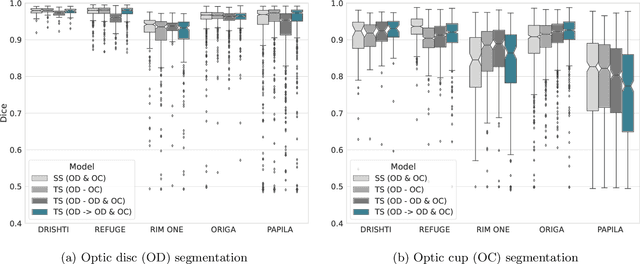
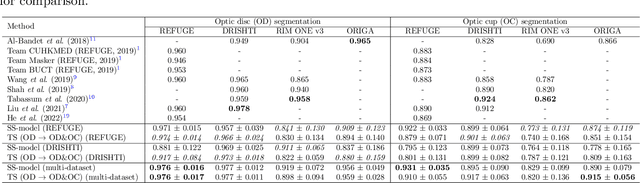
Automated optic disc (OD) and optic cup (OC) segmentation in fundus images is relevant to efficiently measure the vertical cup-to-disc ratio (vCDR), a biomarker commonly used in ophthalmology to determine the degree of glaucomatous optic neuropathy. In general this is solved using coarse-to-fine deep learning algorithms in which a first stage approximates the OD and a second one uses a crop of this area to predict OD/OC masks. While this approach is widely applied in the literature, there are no studies analyzing its real contribution to the results. In this paper we present a comprehensive analysis of different coarse-to-fine designs for OD/OC segmentation using 5 public databases, both from a standard segmentation perspective and for estimating the vCDR for glaucoma assessment. Our analysis shows that these algorithms not necessarily outperfom standard multi-class single-stage models, especially when these are learned from sufficiently large and diverse training sets. Furthermore, we noticed that the coarse stage achieves better OD segmentation results than the fine one, and that providing OD supervision to the second stage is essential to ensure accurate OC masks. Moreover, both the single-stage and two-stage models trained on a multi-dataset setting showed results in pair or even better than other state-of-the-art alternatives, while ranking first in REFUGE for OD/OC segmentation. Finally, we evaluated the models for vCDR prediction in comparison with six ophthalmologists on a subset of AIROGS images, to understand them in the context of inter-observer variability. We noticed that vCDR estimates recovered both from single-stage and coarse-to-fine models can obtain good glaucoma detection results even when they are not highly correlated with manual measurements from experts.