 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchZooms: Deep multi-view descriptors for matching line drawings
Nov 29, 2019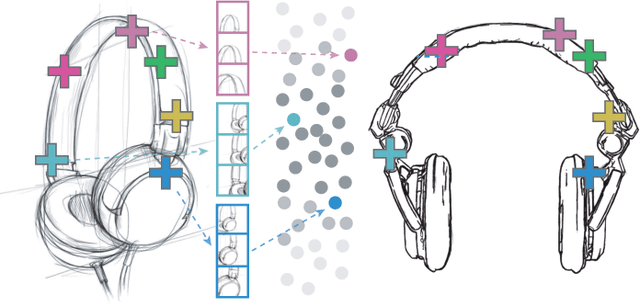
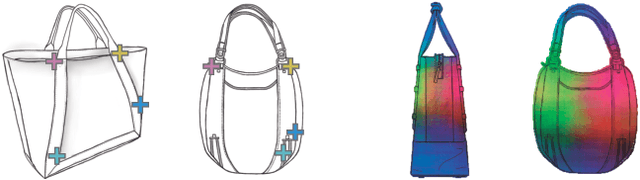
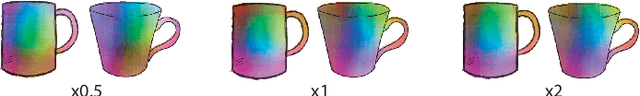
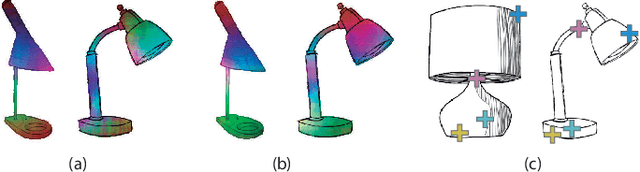
Finding point-wise correspondences between images is a long-standing problem in computer vision. Corresponding sketch images is particularly challenging due to the varying nature of human style, projection distortions and viewport changes. In this paper we present a feature descriptor targeting line drawings learned from a 3D shape data set. Our descriptors are designed to locally match image pairs where the object of interest belongs to the same semantic category, yet still differ drastically in shape and projection angle. We build our descriptors by means of a Convolutional Neural Network (CNN) trained in a triplet fashion. The goal is to embed semantically similar anchor points close to one another, and to pull the embeddings of different points far apart. To learn the descriptors space, the network is fed with a succession of zoomed views from the input sketches. We have specifically crafted a data set of synthetic sketches using a non-photorealistic rendering algorithm over a large collection of part-based registered 3D models. Once trained, our network can generate descriptors for every pixel in an input image. Furthermore, our network is able to generalize well to unseen sketches hand-drawn by humans, outperforming state-of-the-art descriptors on the evaluated matching tasks. Our descriptors can be used to obtain sparse and dense correspondences between image pairs. We evaluate our method against a baseline of correspondences data collected from expert designers, in addition to comparisons with descriptors that have been proven effective in sketches. Finally, we demonstrate applications showing the usefulness of our multi-view descriptors.