 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Should LLMs Consume High-Quality Data? Optimal Data Scheduling via Quality-Aware Functional Scaling Laws
May 25, 2026High-quality data is scarce in large language model (LLM) training, yet how to schedule its use jointly with training dynamics lacks theoretical guidance. We extend functional scaling laws by incorporating a data-quality dimension, and solve the joint data-quality and batch-size scheduling problem in asymptotic closed form. The solution reveals two regimes and a dual role of high-quality data. In the noise-limited regime, high-quality data should be used as a signal amplifier: lowering the batch size converts cleaner data into more signal without amplifying noise. In the signal-limited regime, it should be used as a noise suppressor: late placement reduces terminal noise without sacrificing signal accumulation. Existing curriculum-style pipelines primarily exploit the second role by placing cleaner data late, but miss the first role because conventional decay schedules reduce update intensity exactly when high-quality data becomes available. Guided by this, we propose Drop-Stable-Rampup for LLM midtraining: upon the quality transition, drop the batch size, hold it stable to accumulate signal, then ramp up to suppress terminal noise. On a 15B Mixture-of-Experts model midtrained on 108B tokens, Drop-Stable-Rampup improves average accuracy over Warmup-Stable-Decay (WSD) by +1.70 and over Cosine-decay by +2.98, with particularly large gains on mathematical reasoning benchmarks such as GSM8K (+4.23) and MATH (+2.80).
Debias the Black-box: A Fair Ranking Framework via Knowledge Distillation
Aug 24, 2022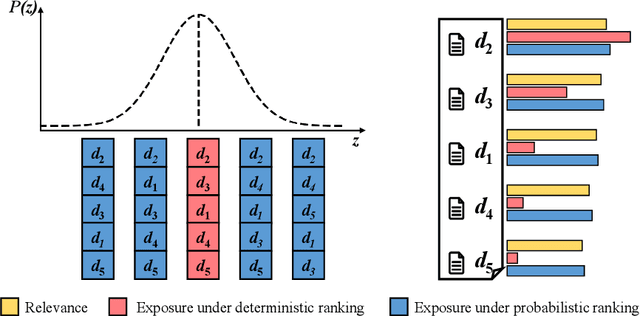
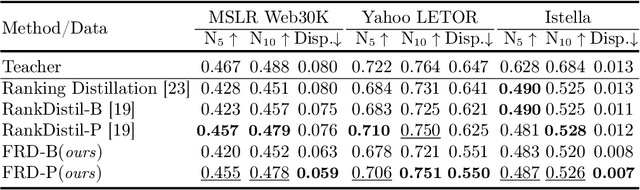
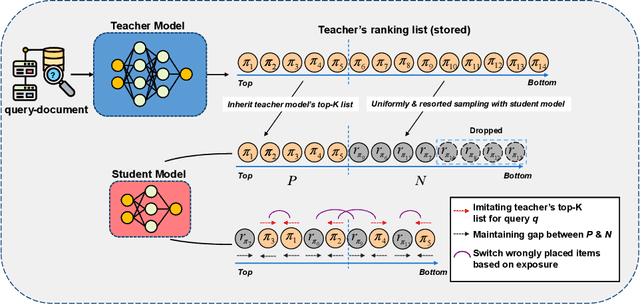
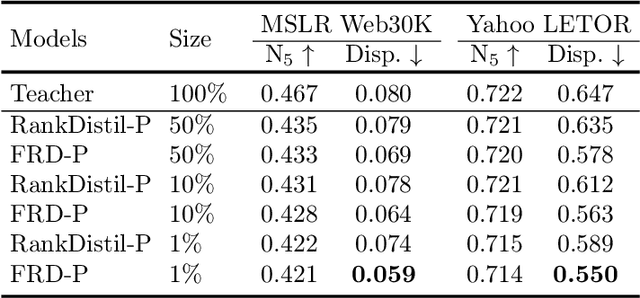
Deep neural networks can capture the intricate interaction history information between queries and documents, because of their many complicated nonlinear units, allowing them to provide correct search recommendations. However, service providers frequently face more complex obstacles in real-world circumstances, such as deployment cost constraints and fairness requirements. Knowledge distillation, which transfers the knowledge of a well-trained complex model (teacher) to a simple model (student), has been proposed to alleviate the former concern, but the best current distillation methods focus only on how to make the student model imitate the predictions of the teacher model. To better facilitate the application of deep models, we propose a fair information retrieval framework based on knowledge distillation. This framework can improve the exposure-based fairness of models while considerably decreasing model size. Our extensive experiments on three huge datasets show that our proposed framework can reduce the model size to a minimum of 1% of its original size while maintaining its black-box state. It also improves fairness performance by 15%~46% while keeping a high level of recommendation effectiveness.
Leveraging Causal Inference for Explainable Automatic Program Repair
Jun 06, 2022
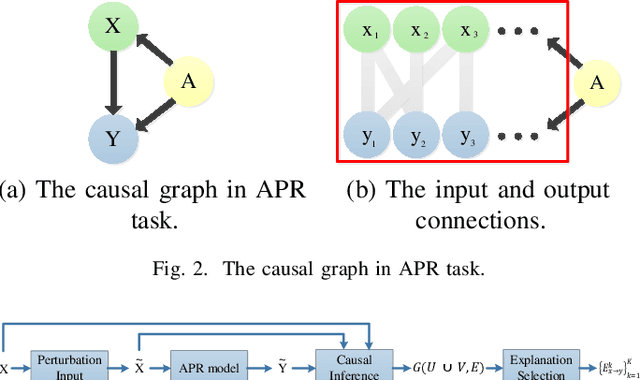
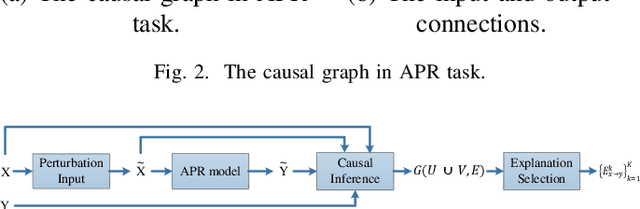
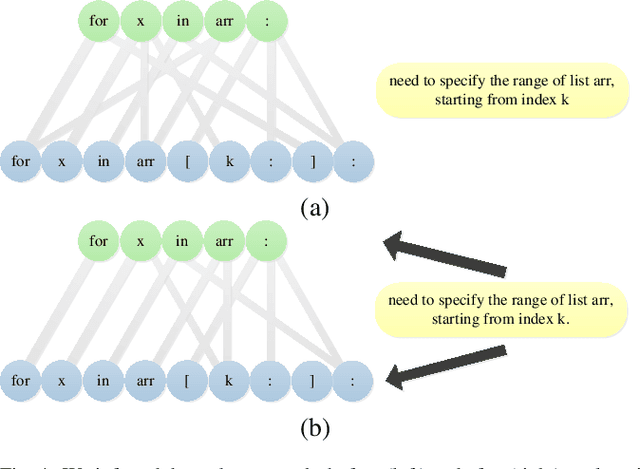
Deep learning models have made significant progress in automatic program repair. However, the black-box nature of these methods has restricted their practical applications. To address this challenge, this paper presents an interpretable approach for program repair based on sequence-to-sequence models with causal inference and our method is called CPR, short for causal program repair. Our CPR can generate explanations in the process of decision making, which consists of groups of causally related input-output tokens. Firstly, our method infers these relations by querying the model with inputs disturbed by data augmentation. Secondly, it generates a graph over tokens from the responses and solves a partitioning problem to select the most relevant components. The experiments on four programming languages (Java, C, Python, and JavaScript) show that CPR can generate causal graphs for reasonable interpretations and boost the performance of bug fixing in automatic program repair.
A Fair Federated Learning Framework With Reinforcement Learning
May 26, 2022
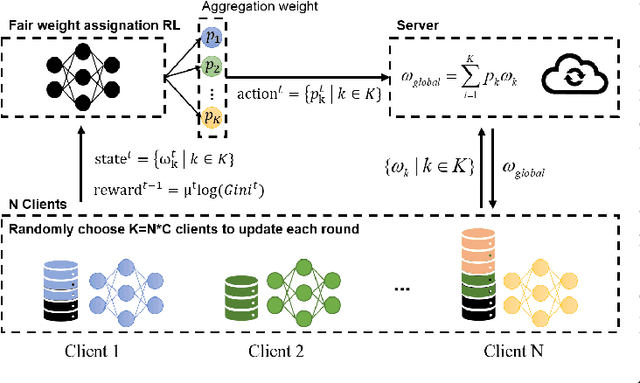
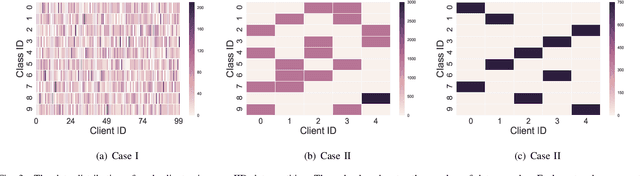
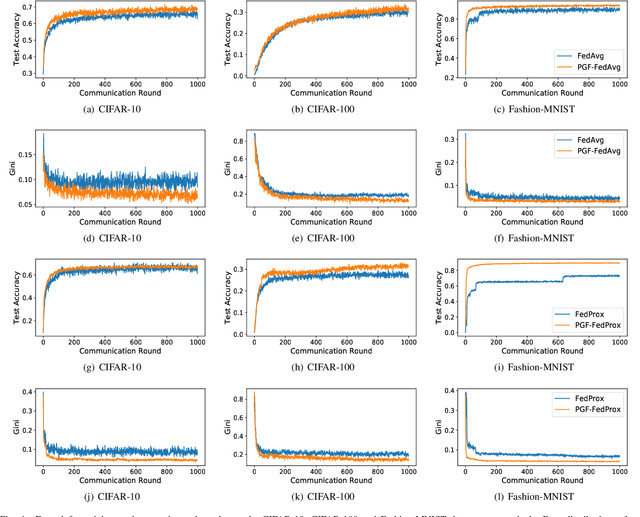
Federated learning (FL) is a paradigm where many clients collaboratively train a model under the coordination of a central server, while keeping the training data locally stored. However, heterogeneous data distributions over different clients remain a challenge to mainstream FL algorithms, which may cause slow convergence, overall performance degradation and unfairness of performance across clients. To address these problems, in this study we propose a reinforcement learning framework, called PG-FFL, which automatically learns a policy to assign aggregation weights to clients. Additionally, we propose to utilize Gini coefficient as the measure of fairness for FL. More importantly, we apply the Gini coefficient and validation accuracy of clients in each communication round to construct a reward function for the reinforcement learning. Our PG-FFL is also compatible to many existing FL algorithms. We conduct extensive experiments over diverse datasets to verify the effectiveness of our framework. The experimental results show that our framework can outperform baseline methods in terms of overall performance, fairness and convergence speed.
Cali3F: Calibrated Fast Fair Federated Recommendation System
May 26, 2022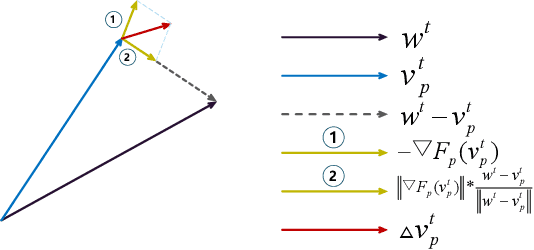
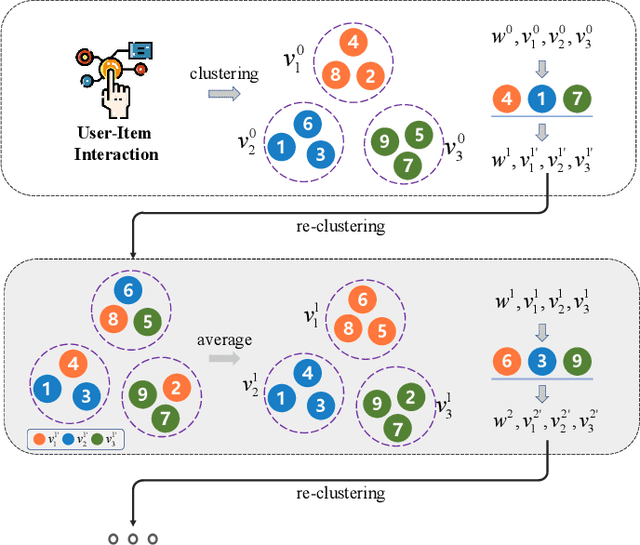
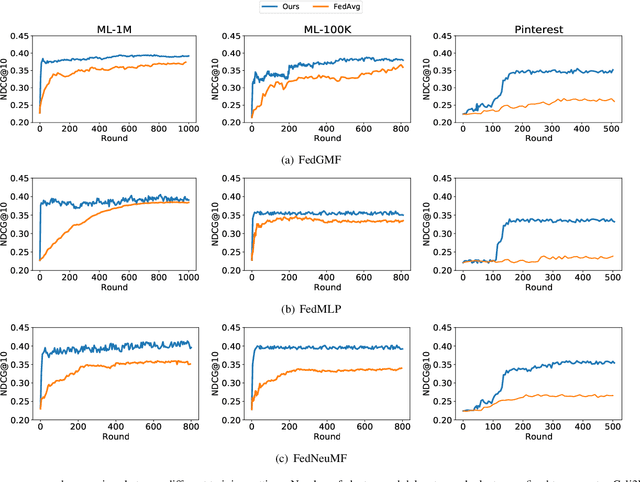
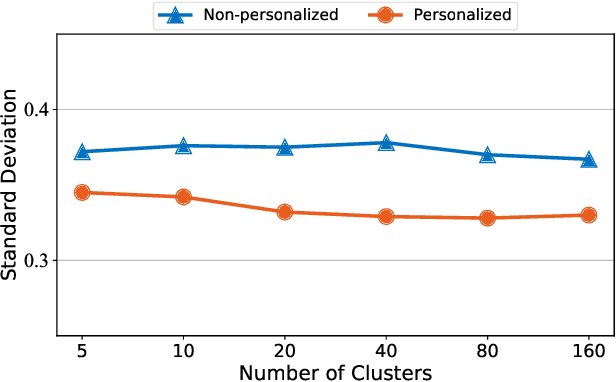
The increasingly stringent regulations on privacy protection have sparked interest in federated learning. As a distributed machine learning framework, it bridges isolated data islands by training a global model over devices while keeping data localized. Specific to recommendation systems, many federated recommendation algorithms have been proposed to realize the privacy-preserving collaborative recommendation. However, several constraints remain largely unexplored. One big concern is how to ensure fairness between participants of federated learning, that is, to maintain the uniformity of recommendation performance across devices. On the other hand, due to data heterogeneity and limited networks, additional challenges occur in the convergence speed. To address these problems, in this paper, we first propose a personalized federated recommendation system training algorithm to improve the recommendation performance fairness. Then we adopt a clustering-based aggregation method to accelerate the training process. Combining the two components, we proposed Cali3F, a calibrated fast and fair federated recommendation framework. Cali3F not only addresses the convergence problem by a within-cluster parameter sharing approach but also significantly boosts fairness by calibrating local models with the global model. We demonstrate the performance of Cali3F across standard benchmark datasets and explore the efficacy in comparison to traditional aggregation approaches.