 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebias the Black-box: A Fair Ranking Framework via Knowledge Distillation
Paper and Code
Aug 24, 2022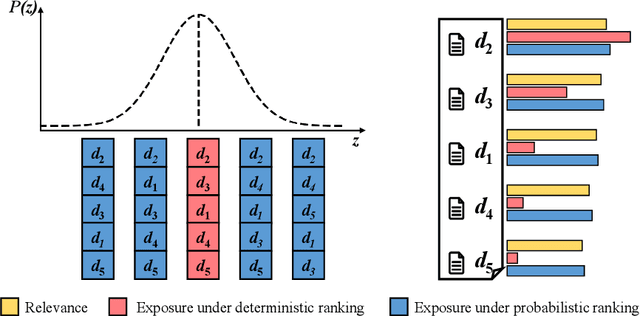
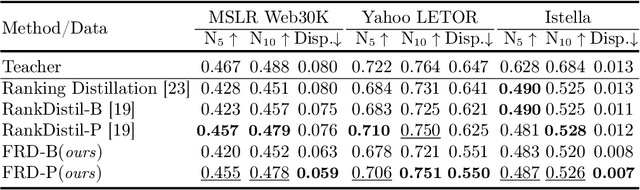
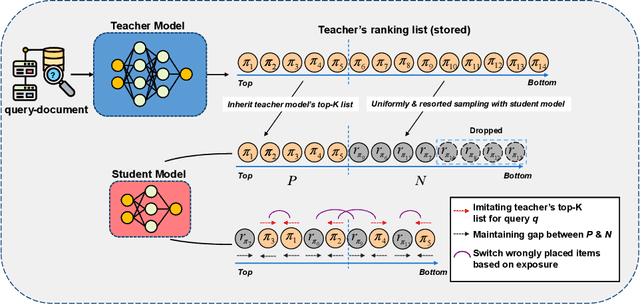
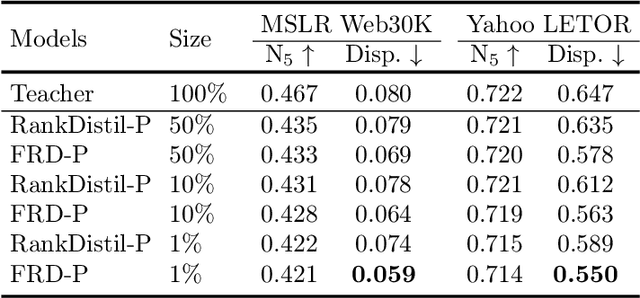
Deep neural networks can capture the intricate interaction history information between queries and documents, because of their many complicated nonlinear units, allowing them to provide correct search recommendations. However, service providers frequently face more complex obstacles in real-world circumstances, such as deployment cost constraints and fairness requirements. Knowledge distillation, which transfers the knowledge of a well-trained complex model (teacher) to a simple model (student), has been proposed to alleviate the former concern, but the best current distillation methods focus only on how to make the student model imitate the predictions of the teacher model. To better facilitate the application of deep models, we propose a fair information retrieval framework based on knowledge distillation. This framework can improve the exposure-based fairness of models while considerably decreasing model size. Our extensive experiments on three huge datasets show that our proposed framework can reduce the model size to a minimum of 1% of its original size while maintaining its black-box state. It also improves fairness performance by 15%~46% while keeping a high level of recommendation effectiveness.