 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgejXBW: Fast Substructure Search in Large-Scale JSONL Datasets for Foundation Model Applications
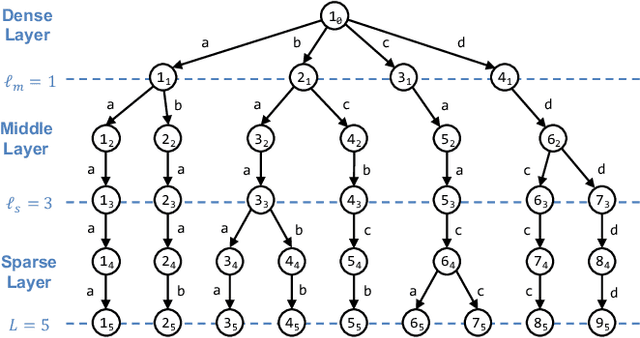
Aug 18, 2025Substructure search in JSON Lines (JSONL) datasets is essential for modern applications such as prompt engineering in foundation models, but existing methods suffer from prohibitive computational costs due to exhaustive tree traversal and subtree matching. We present jXBW, a fast method for substructure search on large-scale JSONL datasets. Our method makes three key technical contributions: (i) a merged tree representation built by merging trees of multiple JSON objects while preserving individual identities, (ii) a succinct data structure based on the eXtended Burrows-Wheeler Transform that enables efficient tree navigation and subpath search, and (iii) an efficient three-step substructure search algorithm that combines path decomposition, ancestor computation, and adaptive tree identifier collection to ensure correctness while avoiding exhaustive tree traversal. Experimental evaluation on real-world datasets demonstrates that jXBW consistently outperforms existing methods, achieving speedups of 16$\times$ for smaller datasets and up to 4,700$\times$ for larger datasets over tree-based approaches, and more than 6$\times$10$^6$ over XML-based processing while maintaining competitive memory usage.
Succinct Trit-array Trie for Scalable Trajectory Similarity Search
May 21, 2020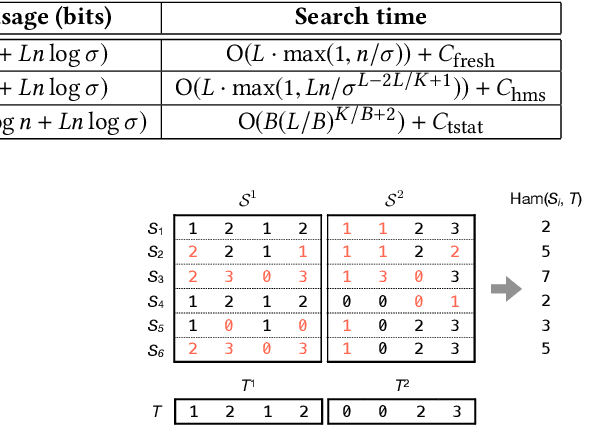

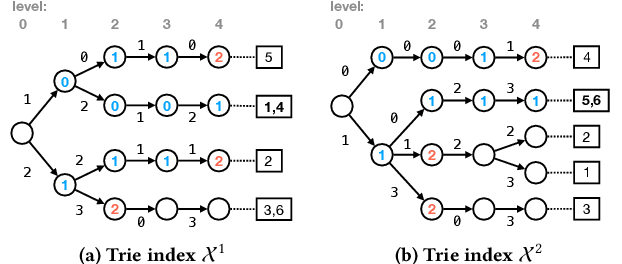
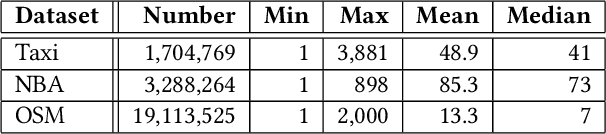
Massive datasets of spatial trajectories representing the mobility of a diversity of moving objects are ubiquitous in research and industry. Similarity search of a large collection of trajectories is indispensable for turning these datasets into knowledge. Current methods for similarity search of trajectories are inefficient in terms of search time and memory when applied to massive datasets. In this paper, we address this problem by presenting a scalable similarity search for Fr\'echet distance on trajectories, which we call trajectory-indexing succinct trit-array trie (tSTAT). tSTAT achieves time and memory efficiency by leveraging locality sensitive hashing (LSH) for Fr\'echet distance and a trie data structure. We also present two novel techniques of node reduction and a space-efficient representation for tries, which enable to dramatically enhance a memory efficiency of tries. We experimentally test tSTAT on its ability to retrieve similar trajectories for a query from large collections of trajectories and show that tSTAT performs superiorly with respect to search time and memory efficiency.
$b$-Bit Sketch Trie: Scalable Similarity Search on Integer Sketches
Oct 18, 2019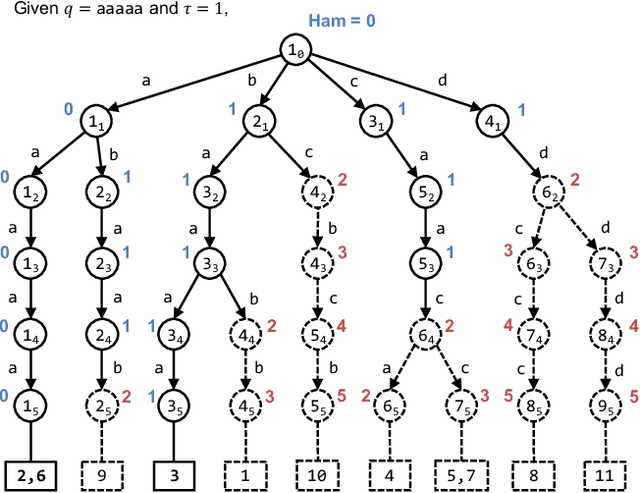

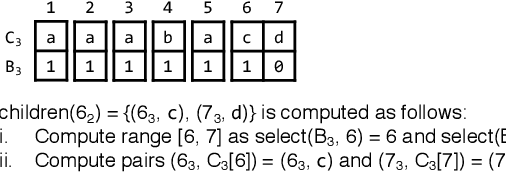
Recently, randomly mapping vectorial data to strings of discrete symbols (i.e., sketches) for fast and space-efficient similarity searches has become popular. Such random mapping is called similarity-preserving hashing and approximates a similarity metric by using the Hamming distance. Although many efficient similarity searches have been proposed, most of them are designed for binary sketches. Similarity searches on integer sketches are in their infancy. In this paper, we present a novel space-efficient trie named $b$-bit sketch trie on integer sketches for scalable similarity searches by leveraging the idea behind succinct data structures (i.e., space-efficient data structures while supporting various data operations in the compressed format) and a favorable property of integer sketches as fixed-length strings. Our experimental results obtained using real-world datasets show that a trie-based index is built from integer sketches and efficiently performs similarity searches on the index by pruning useless portions of the search space, which greatly improves the search time and space-efficiency of the similarity search. The experimental results show that our similarity search is at most one order of magnitude faster than state-of-the-art similarity searches. Besides, our method needs only 10 GiB of memory on a billion-scale database, while state-of-the-art similarity searches need 29 GiB of memory.
Statistically Discriminative Sub-trajectory Mining
May 06, 2019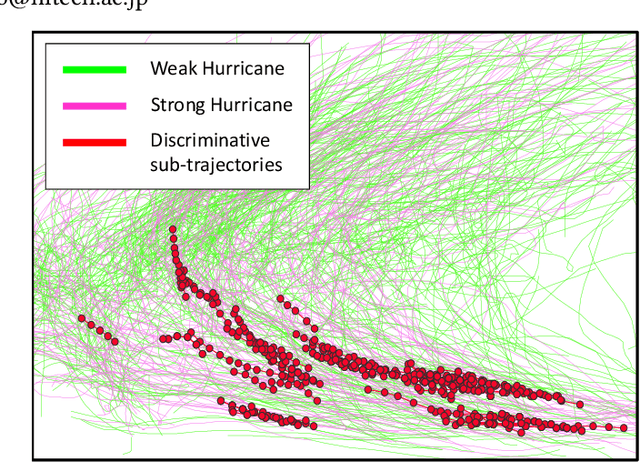
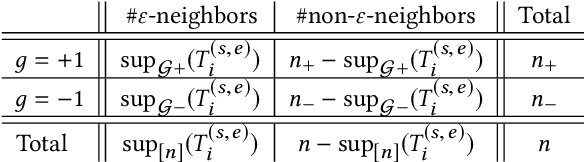
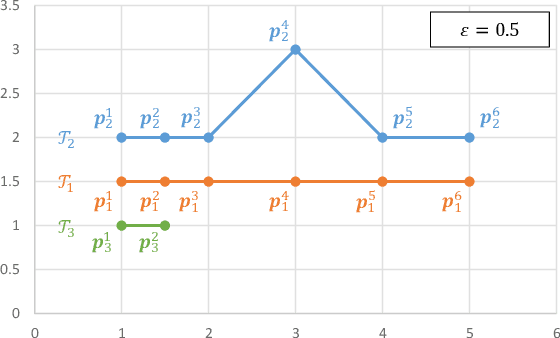
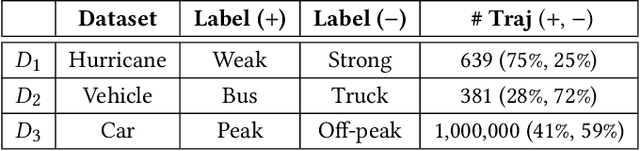
We study the problem of discriminative sub-trajectory mining. Given two groups of trajectories, the goal of this problem is to extract moving patterns in the form of sub-trajectories which are more similar to sub-trajectories of one group and less similar to those of the other. We propose a new method called Statistically Discriminative Sub-trajectory Mining (SDSM) for this problem. An advantage of the SDSM method is that the statistical significance of the extracted sub-trajectories are properly controlled in the sense that the probability of finding a false positive sub-trajectory is smaller than a specified significance threshold alpha (e.g., 0.05), which is indispensable when the method is used in scientific or social studies under noisy environment. Finding such statistically discriminative sub-trajectories from massive trajectory dataset is both computationally and statistically challenging. In the SDSM method, we resolve the difficulties by introducing a tree representation among sub-trajectories and running an efficient permutation-based statistical inference method on the tree. To the best of our knowledge, SDSM is the first method that can efficiently extract statistically discriminative sub-trajectories from massive trajectory dataset. We illustrate the effectiveness and scalability of the SDSM method by applying it to a real-world dataset with 1,000,000 trajectories which contains 16,723,602,505 sub-trajectories.
Scalable Alignment Kernels via Space-Efficient Feature Maps
Mar 28, 2018
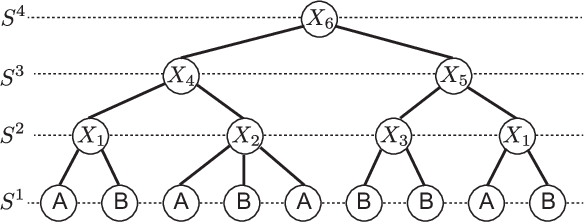

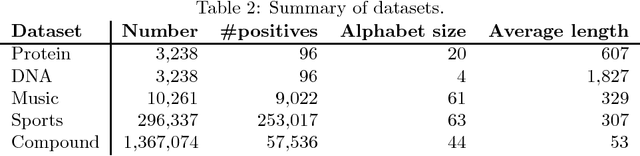
String kernels are attractive data analysis tools for analyzing string data. Among them, alignment kernels are known for their high prediction accuracies in string classifications when tested in combination with SVMs in various applications. However, alignment kernels have a crucial drawback in that they scale poorly due to their quadratic computation complexity in the number of input strings, which limits large-scale applications in practice. We present the first approximation named ESP+SFM for alignment kernels by leveraging a metric embedding named edit-sensitive parsing (ESP) and space-efficient feature maps (SFM) for random Fourier features (RFF) for large-scale string analyses. Input strings are projected into vectors of RFF by leveraging ESP and SFM. Then, SVMs are trained on the projected vectors, which enables to significantly improve the scalability of alignment kernels while preserving their prediction accuracies. We experimentally test ESP+ SFM on its ability to learn SVMs for large-scale string classifications with various massive string data, and we demonstrate the superior performance of ESP+SFM with respect to prediction accuracy, scalability and computation efficiency.