 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Prompt-based Models Clueless?
Paper and Code
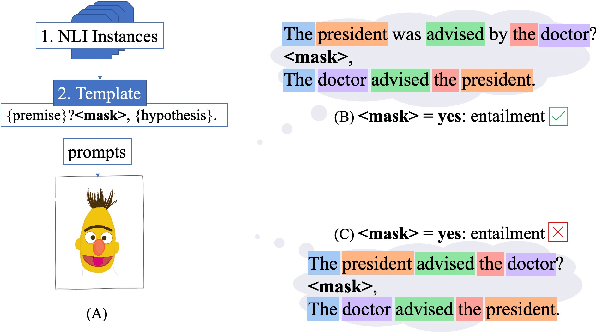
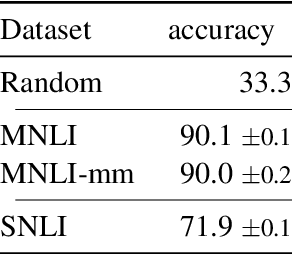
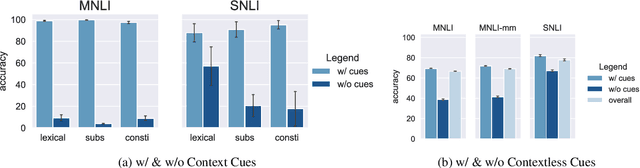
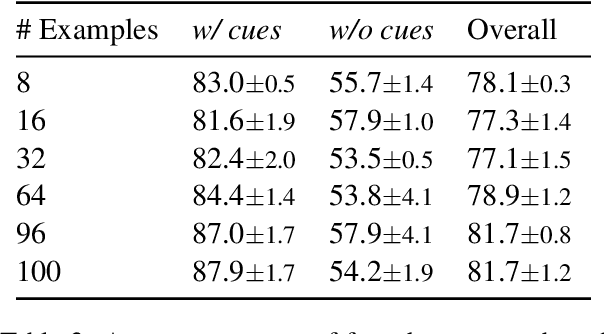
Finetuning large pre-trained language models with a task-specific head has advanced the state-of-the-art on many natural language understanding benchmarks. However, models with a task-specific head require a lot of training data, making them susceptible to learning and exploiting dataset-specific superficial cues that do not generalize to other datasets. Prompting has reduced the data requirement by reusing the language model head and formatting the task input to match the pre-training objective. Therefore, it is expected that few-shot prompt-based models do not exploit superficial cues. This paper presents an empirical examination of whether few-shot prompt-based models also exploit superficial cues. Analyzing few-shot prompt-based models on MNLI, SNLI, HANS, and COPA has revealed that prompt-based models also exploit superficial cues. While the models perform well on instances with superficial cues, they often underperform or only marginally outperform random accuracy on instances without superficial cues.