 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign, Write, Re-order: Explainable End-to-End Speech Translation via Operation Sequence Generation
Nov 11, 2022



The black-box nature of end-to-end speech translation (E2E ST) systems makes it difficult to understand how source language inputs are being mapped to the target language. To solve this problem, we would like to simultaneously generate automatic speech recognition (ASR) and ST predictions such that each source language word is explicitly mapped to a target language word. A major challenge arises from the fact that translation is a non-monotonic sequence transduction task due to word ordering differences between languages -- this clashes with the monotonic nature of ASR. Therefore, we propose to generate ST tokens out-of-order while remembering how to re-order them later. We achieve this by predicting a sequence of tuples consisting of a source word, the corresponding target words, and post-editing operations dictating the correct insertion points for the target word. We examine two variants of such operation sequences which enable generation of monotonic transcriptions and non-monotonic translations from the same speech input simultaneously. We apply our approach to offline and real-time streaming models, demonstrating that we can provide explainable translations without sacrificing quality or latency. In fact, the delayed re-ordering ability of our approach improves performance during streaming. As an added benefit, our method performs ASR and ST simultaneously, making it faster than using two separate systems to perform these tasks.
Speaker Selective Beamformer with Keyword Mask Estimation
Oct 25, 2018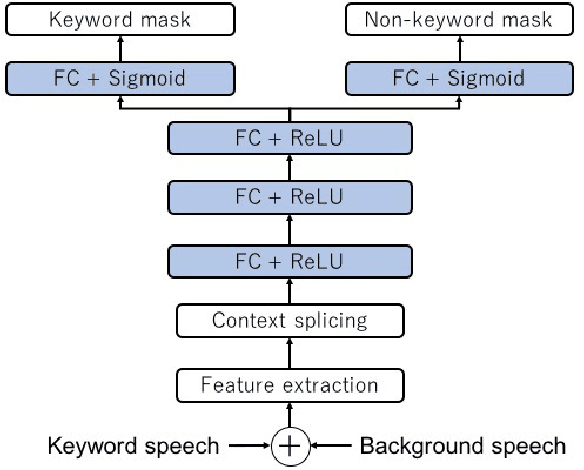

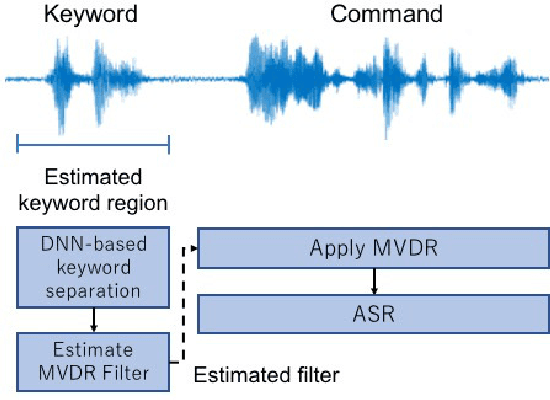
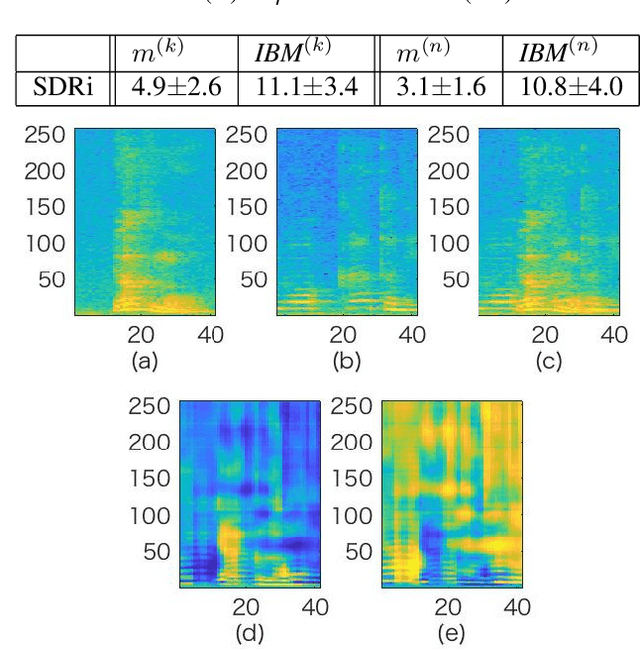
This paper addresses the problem of automatic speech recognition (ASR) of a target speaker in background speech. The novelty of our approach is that we focus on a wakeup keyword, which is usually used for activating ASR systems like smart speakers. The proposed method firstly utilizes a DNN-based mask estimator to separate the mixture signal into the keyword signal uttered by the target speaker and the remaining background speech. Then the separated signals are used for calculating a beamforming filter to enhance the subsequent utterances from the target speaker. Experimental evaluations show that the trained DNN-based mask can selectively separate the keyword and background speech from the mixture signal. The effectiveness of the proposed method is also verified with Japanese ASR experiments, and we confirm that the character error rates are significantly improved by the proposed method for both simulated and real recorded test sets.