 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould We Always Separate?: Switching Between Enhanced and Observed Signals for Overlapping Speech Recognition
Paper and Code
Jun 02, 2021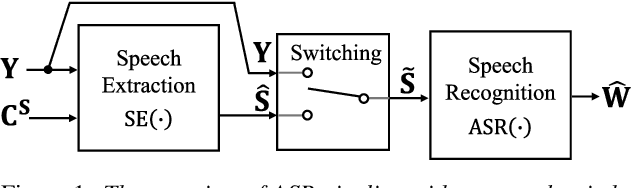
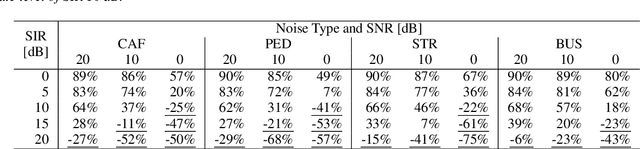
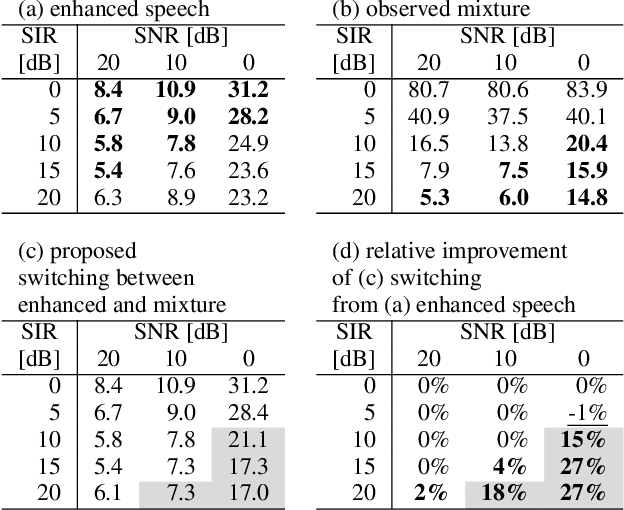
Although recent advances in deep learning technology improved automatic speech recognition (ASR), it remains difficult to recognize speech when it overlaps other people's voices. Speech separation or extraction is often used as a front-end to ASR to handle such overlapping speech. However, deep neural network-based speech enhancement can generate `processing artifacts' as a side effect of the enhancement, which degrades ASR performance. For example, it is well known that single-channel noise reduction for non-speech noise (non-overlapping speech) often does not improve ASR. Likewise, the processing artifacts may also be detrimental to ASR in some conditions when processing overlapping speech with a separation/extraction method, although it is usually believed that separation/extraction improves ASR. In order to answer the question `Do we always have to separate/extract speech from mixtures?', we analyze ASR performance on observed and enhanced speech at various noise and interference conditions, and show that speech enhancement degrades ASR under some conditions even for overlapping speech. Based on these findings, we propose a simple switching algorithm between observed and enhanced speech based on the estimated signal-to-interference ratio and signal-to-noise ratio. We demonstrated experimentally that such a simple switching mechanism can improve recognition performance when processing artifacts are detrimental to ASR.