 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction method of Soundscape Impressions using Environmental Sounds and Aerial Photographs
Sep 09, 2022
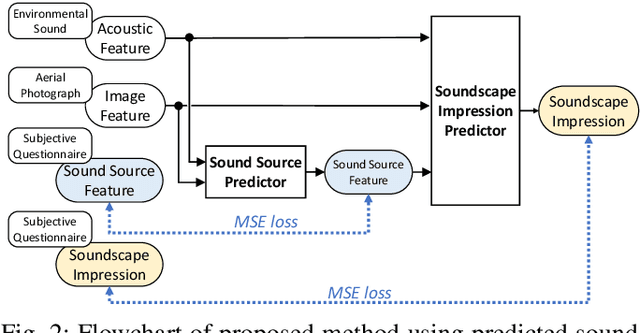

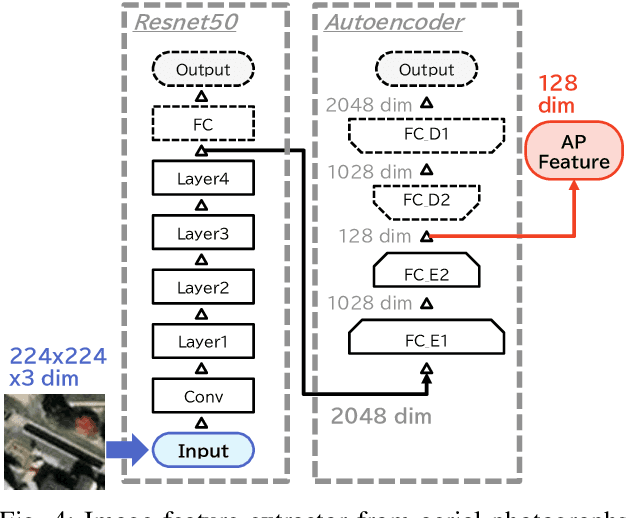
We investigate an method for quantifying city characteristics based on impressions of a sound environment. The quantification of the city characteristics will be beneficial to government policy planning, tourism projects, etc. In this study, we try to predict two soundscape impressions, meaning pleasantness and eventfulness, using sound data collected by the cloud-sensing method. The collected sounds comprise meta information of recording location using Global Positioning System. Furthermore, the soundscape impressions and sound-source features are separately assigned to the cloud-sensing sounds by assessments defined using Swedish Soundscape-Quality Protocol, assessing the quality of the acoustic environment. The prediction models are built using deep neural networks with multi-layer perceptron for the input of 10-second sound and the aerial photographs of its location. An acoustic feature comprises equivalent noise level and outputs of octave-band filters every second, and statistics of them in 10~s. An image feature is extracted from an aerial photograph using ResNet-50 and autoencoder architecture. We perform comparison experiments to demonstrate the benefit of each feature. As a result of the comparison, aerial photographs and sound-source features are efficient to predict impression information. Additionally, even if the sound-source features are predicted using acoustic and image features, the features also show fine results to predict the soundscape impression close to the result of oracle sound-source features.
Evaluation of concept drift adaptation for acoustic scene classifier based on Kernel Density Drift Detection and Combine Merge Gaussian Mixture Model
May 27, 2021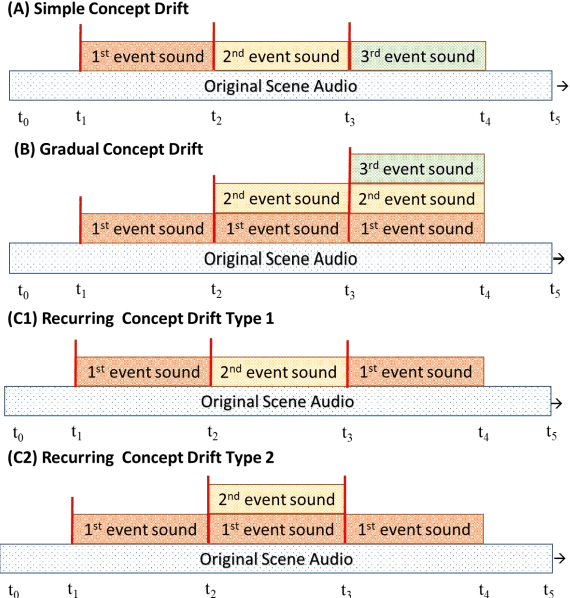
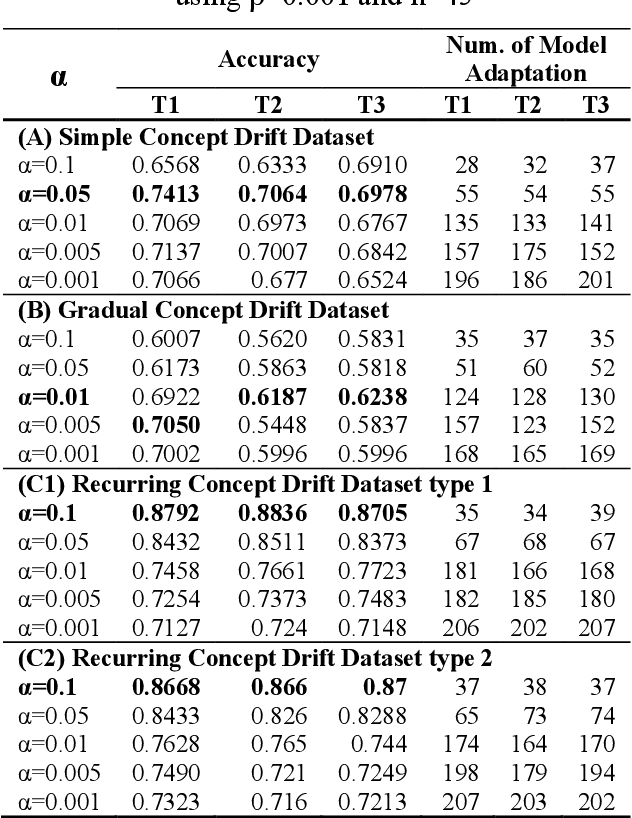
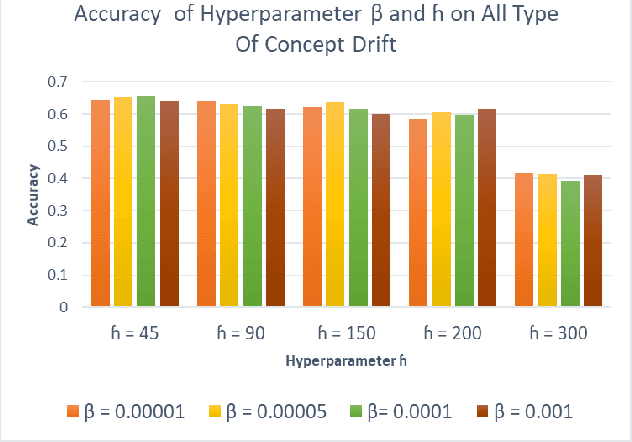
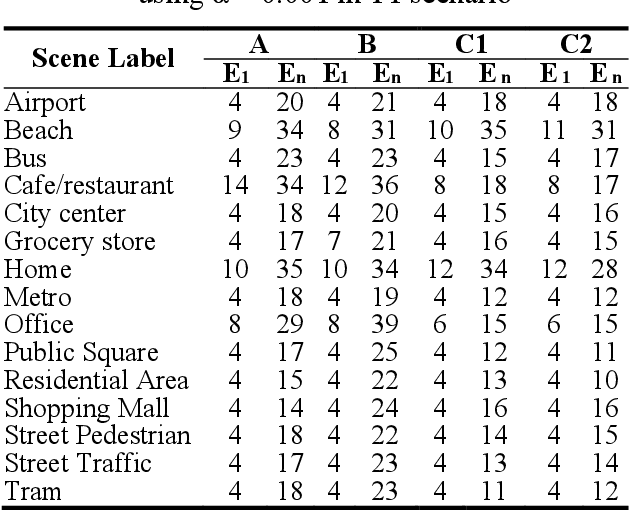
Based on the experimental results, all concepts drift types have their respective hyperparameter configurations. Simple and gradual concept drift have similar pattern which requires a smaller {\alpha} value than recurring concept drift because, in this type of drift, a new concept appear continuously, so it needs a high-frequency model adaptation. However, in recurring concepts, the new concept may repeat in the future, so the lower frequency adaptation is better. Furthermore, high-frequency model adaptation could lead to an overfitting problem. Implementing CMGMM component pruning mechanism help to control the number of the active component and improve model performance.
Model architectures to extrapolate emotional expressions in DNN-based text-to-speech
Feb 20, 2021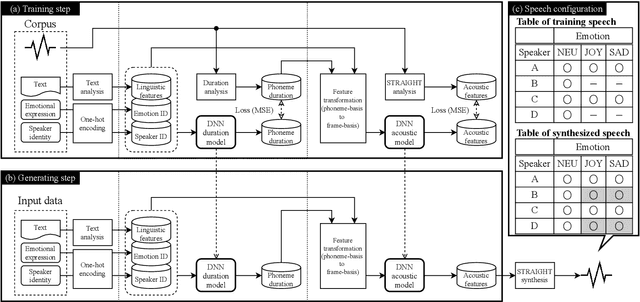
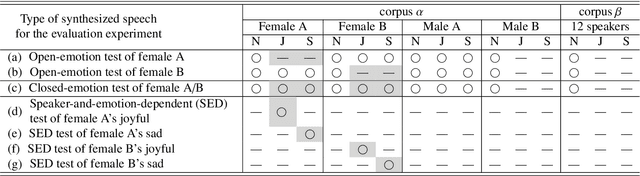
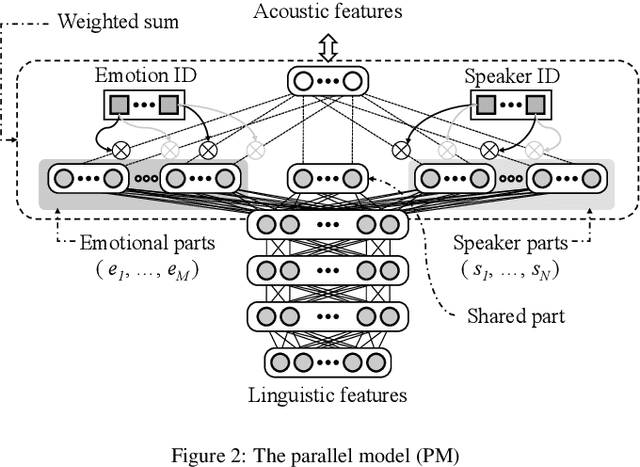

This paper proposes architectures that facilitate the extrapolation of emotional expressions in deep neural network (DNN)-based text-to-speech (TTS). In this study, the meaning of "extrapolate emotional expressions" is to borrow emotional expressions from others, and the collection of emotional speech uttered by target speakers is unnecessary. Although a DNN has potential power to construct DNN-based TTS with emotional expressions and some DNN-based TTS systems have demonstrated satisfactory performances in the expression of the diversity of human speech, it is necessary and troublesome to collect emotional speech uttered by target speakers. To solve this issue, we propose architectures to separately train the speaker feature and the emotional feature and to synthesize speech with any combined quality of speakers and emotions. The architectures are parallel model (PM), serial model (SM), auxiliary input model (AIM), and hybrid models (PM&AIM and SM&AIM). These models are trained through emotional speech uttered by few speakers and neutral speech uttered by many speakers. Objective evaluations demonstrate that the performances in the open-emotion test provide insufficient information. They make a comparison with those in the closed-emotion test, but each speaker has their own manner of expressing emotion. However, subjective evaluation results indicate that the proposed models could convey emotional information to some extent. Notably, the PM can correctly convey sad and joyful emotions at a rate of >60%.
Easy-setup eye movement recording system for human-computer interaction
Nov 28, 2016



Tracking the movement of human eyes is expected to yield natural and convenient applications based on human-computer interaction (HCI). To implement an effective eye-tracking system, eye movements must be recorded without placing any restriction on the user's behavior or user discomfort. This paper describes an eye movement recording system that offers free-head, simple configuration. It does not require the user to wear anything on her head, and she can move her head freely. Instead of using a computer, the system uses a visual digital signal processor (DSP) camera to detect the position of eye corner, the center of pupil and then calculate the eye movement. Evaluation tests show that the sampling rate of the system can be 300 Hz and the accuracy is about 1.8 degree/s.