 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel architectures to extrapolate emotional expressions in DNN-based text-to-speech
Feb 20, 2021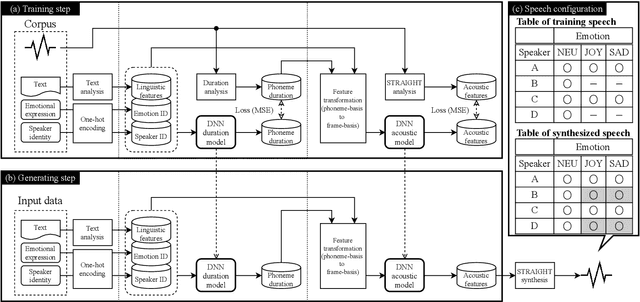
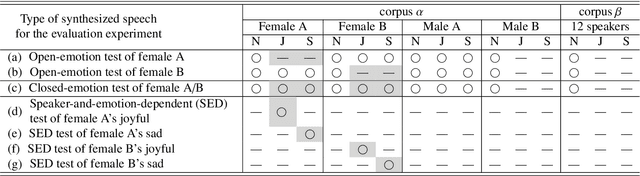
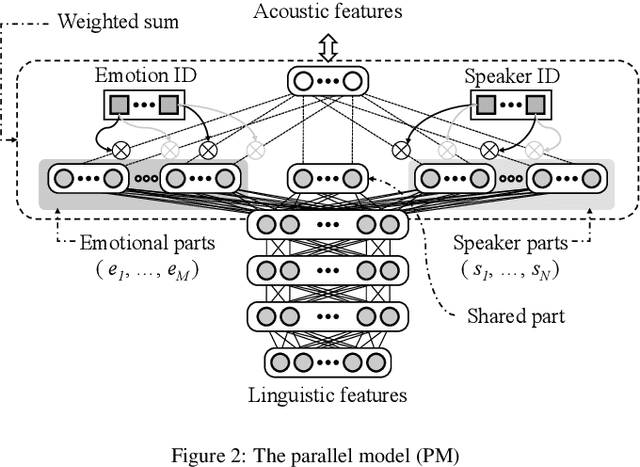

This paper proposes architectures that facilitate the extrapolation of emotional expressions in deep neural network (DNN)-based text-to-speech (TTS). In this study, the meaning of "extrapolate emotional expressions" is to borrow emotional expressions from others, and the collection of emotional speech uttered by target speakers is unnecessary. Although a DNN has potential power to construct DNN-based TTS with emotional expressions and some DNN-based TTS systems have demonstrated satisfactory performances in the expression of the diversity of human speech, it is necessary and troublesome to collect emotional speech uttered by target speakers. To solve this issue, we propose architectures to separately train the speaker feature and the emotional feature and to synthesize speech with any combined quality of speakers and emotions. The architectures are parallel model (PM), serial model (SM), auxiliary input model (AIM), and hybrid models (PM&AIM and SM&AIM). These models are trained through emotional speech uttered by few speakers and neutral speech uttered by many speakers. Objective evaluations demonstrate that the performances in the open-emotion test provide insufficient information. They make a comparison with those in the closed-emotion test, but each speaker has their own manner of expressing emotion. However, subjective evaluation results indicate that the proposed models could convey emotional information to some extent. Notably, the PM can correctly convey sad and joyful emotions at a rate of >60%.
ESPnet-TTS: Unified, Reproducible, and Integratable Open Source End-to-End Text-to-Speech Toolkit
Oct 24, 2019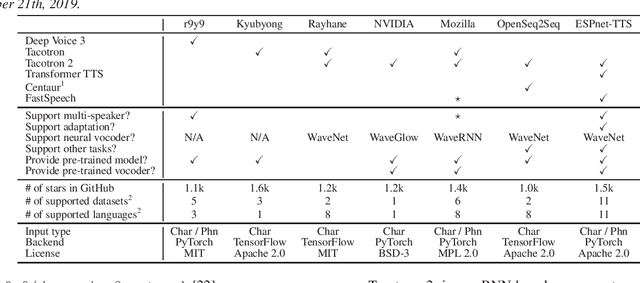
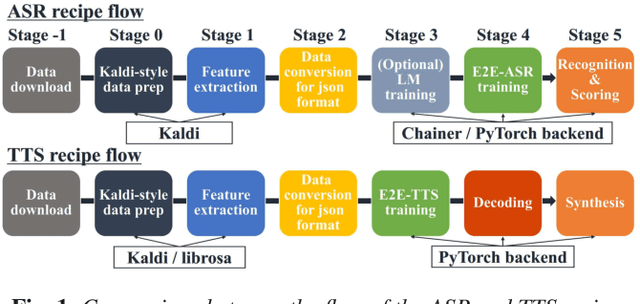
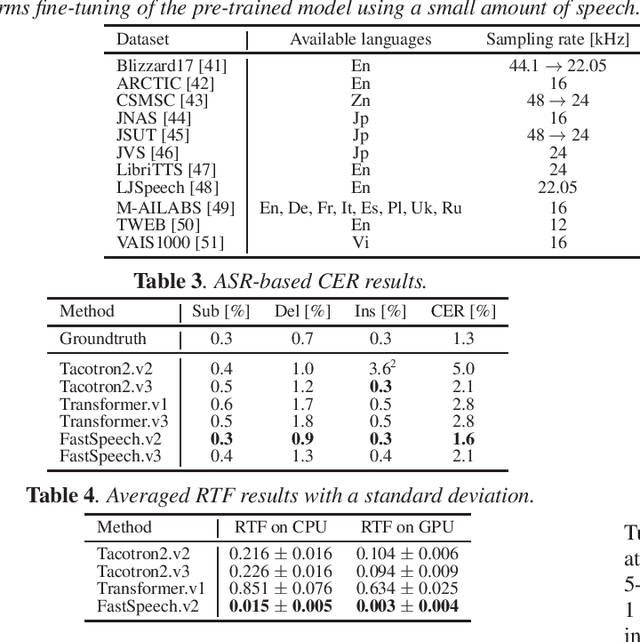
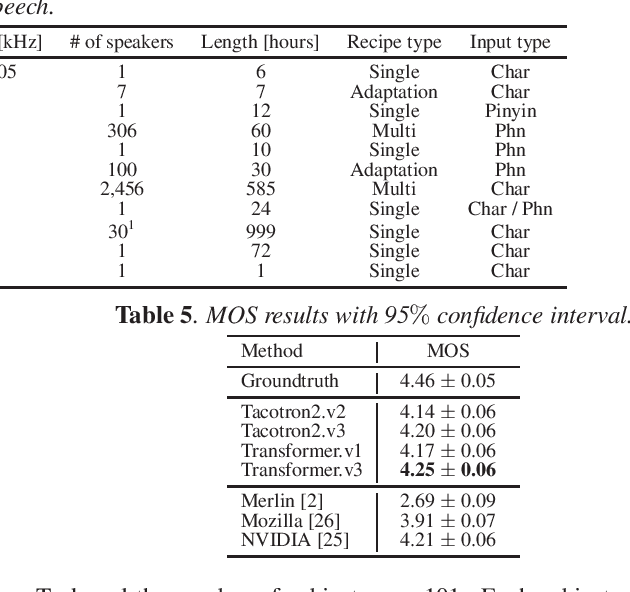
This paper introduces a new end-to-end text-to-speech (E2E-TTS) toolkit named ESPnet-TTS, which is an extension of the open-source speech processing toolkit ESPnet. The toolkit supports state-of-the-art E2E-TTS models, including Tacotron~2, Transformer TTS, and FastSpeech, and also provides recipes inspired by the Kaldi automatic speech recognition (ASR) toolkit. The recipes are based on the design unified with the ESPnet ASR recipe, providing high reproducibility. The toolkit also provides pre-trained models and samples of all of the recipes so that users can use it as a baseline. Furthermore, the unified design enables the integration of ASR functions with TTS, e.g., ASR-based objective evaluation and semi-supervised learning with both ASR and TTS models. This paper describes the design of the toolkit and experimental evaluation in comparison with other toolkits. The experimental results show that our best model outperforms other toolkits, resulting in a mean opinion score (MOS) of 4.25 on the LJSpeech dataset. The toolkit is available on GitHub.