 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-fast Traffic Nowcasting and Control via Differentiable Agent-based Simulation
Mar 26, 2026Traffic digital twins, which inform policymakers of effective interventions based on large-scale, high-fidelity computational models calibrated to real-world traffic, hold promise for addressing societal challenges in our rapidly urbanizing world. However, conventional fine-grained traffic simulations are non-differentiable and typically rely on inefficient gradient-free optimization, making calibration for real-world applications computationally infeasible. Here we present a differentiable agent-based traffic simulator that enables ultra-fast model calibration, traffic nowcasting, and control on large-scale networks. We develop several differentiable computing techniques for simulating individual vehicle movements, including stochastic decision-making and inter-agent interactions, while ensuring that entire simulation trajectories remain end-to-end differentiable for efficient gradient-based optimization. On the large-scale Chicago road network, with over 10,000 calibration parameters, our model simulates more than one million vehicles at 173 times real-time speed. This ultra-fast simulation, together with efficient gradient-based optimization, enables us to complete model calibration using the previous 30 minutes of traffic data in 455 s, provide a one-hour-ahead traffic nowcast in 21 s, and solve the resulting traffic control problem in 728 s. This yields a full calibration--nowcast--control loop in under 20 minutes, leaving about 40 minutes of lead time for implementing interventions. Our work thus provides a practical computational basis for realizing traffic digital twins.
Know Unreported Roadway Incidents in Real-time: A Deep Learning Framework for Early Traffic Anomaly Detection
Dec 14, 2024



Conventional automatic incident detection (AID) has relied heavily on all incident reports exclusively for training and evaluation. However, these reports suffer from a number of issues, such as delayed reports, inaccurate descriptions, false alarms, missing reports, and incidents that do not necessarily influence traffic. Relying on these reports to train or calibrate AID models hinders their ability to detect traffic anomalies effectively and timely, even leading to convergence issues in the model training process. Moreover, conventional AID models are not inherently designed to capture the early indicators of any generic incidents. It remains unclear how far ahead an AID model can report incidents. The AID applications in the literature are also spatially limited because the data used by most models is often limited to specific test road segments. To solve these problems, we propose a deep learning framework utilizing prior domain knowledge and model-designing strategies. This allows the model to detect a broader range of anomalies, not only incidents that significantly influence traffic flow but also early characteristics of incidents along with historically unreported anomalies. We specially design the model to target the early-stage detection/prediction of an incident. Additionally, unlike most conventional AID studies, we use widely available data, enhancing our method's scalability. The experimental results across numerous road segments on different maps demonstrate that our model leads to more effective and early anomaly detection. Our framework does not focus on stacking or tweaking various deep learning models; instead, it focuses on model design and training strategies to improve early detection performance.
Interpretable mixture of experts for time series prediction under recurrent and non-recurrent conditions
Sep 05, 2024



Non-recurrent conditions caused by incidents are different from recurrent conditions that follow periodic patterns. Existing traffic speed prediction studies are incident-agnostic and use one single model to learn all possible patterns from these drastically diverse conditions. This study proposes a novel Mixture of Experts (MoE) model to improve traffic speed prediction under two separate conditions, recurrent and non-recurrent (i.e., with and without incidents). The MoE leverages separate recurrent and non-recurrent expert models (Temporal Fusion Transformers) to capture the distinct patterns of each traffic condition. Additionally, we propose a training pipeline for non-recurrent models to remedy the limited data issues. To train our model, multi-source datasets, including traffic speed, incident reports, and weather data, are integrated and processed to be informative features. Evaluations on a real road network demonstrate that the MoE achieves lower errors compared to other benchmark algorithms. The model predictions are interpreted in terms of temporal dependencies and variable importance in each condition separately to shed light on the differences between recurrent and non-recurrent conditions.
Real-time system optimal traffic routing under uncertainties -- Can physics models boost reinforcement learning?
Jul 10, 2024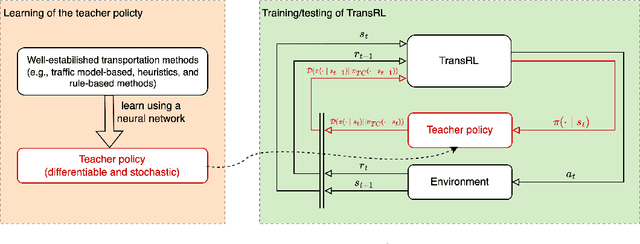
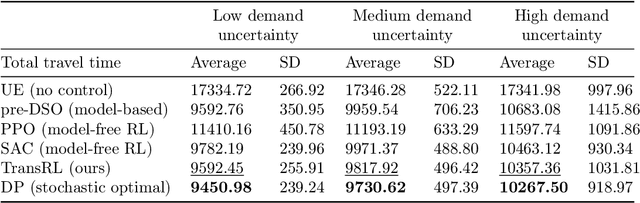
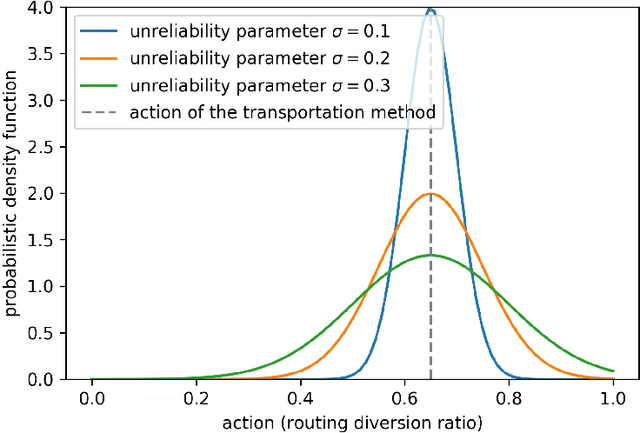
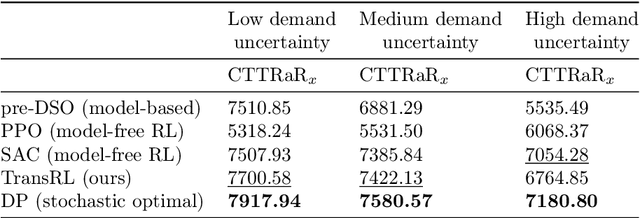
System optimal traffic routing can mitigate congestion by assigning routes for a portion of vehicles so that the total travel time of all vehicles in the transportation system can be reduced. However, achieving real-time optimal routing poses challenges due to uncertain demands and unknown system dynamics, particularly in expansive transportation networks. While physics model-based methods are sensitive to uncertainties and model mismatches, model-free reinforcement learning struggles with learning inefficiencies and interpretability issues. Our paper presents TransRL, a novel algorithm that integrates reinforcement learning with physics models for enhanced performance, reliability, and interpretability. TransRL begins by establishing a deterministic policy grounded in physics models, from which it learns from and is guided by a differentiable and stochastic teacher policy. During training, TransRL aims to maximize cumulative rewards while minimizing the Kullback Leibler (KL) divergence between the current policy and the teacher policy. This approach enables TransRL to simultaneously leverage interactions with the environment and insights from physics models. We conduct experiments on three transportation networks with up to hundreds of links. The results demonstrate TransRL's superiority over traffic model-based methods for being adaptive and learning from the actual network data. By leveraging the information from physics models, TransRL consistently outperforms state-of-the-art reinforcement learning algorithms such as proximal policy optimization (PPO) and soft actor critic (SAC). Moreover, TransRL's actions exhibit higher reliability and interpretability compared to baseline reinforcement learning approaches like PPO and SAC.
Traffic estimation in unobserved network locations using data-driven macroscopic models
Jan 30, 2024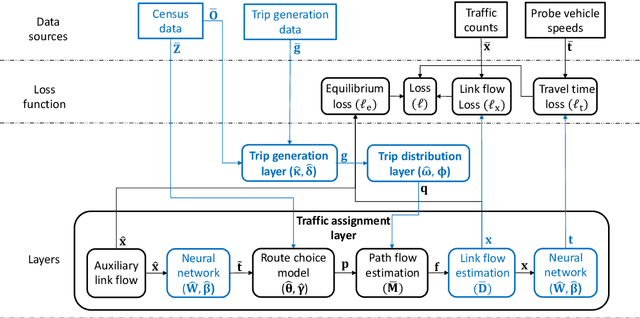

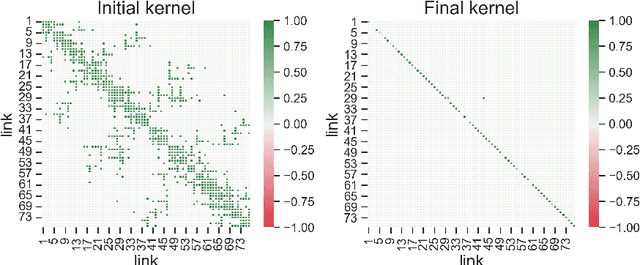
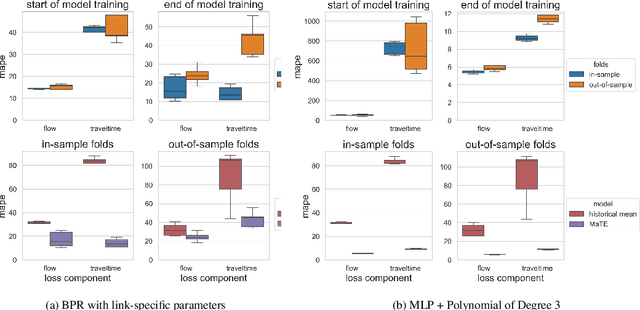
This paper leverages macroscopic models and multi-source spatiotemporal data collected from automatic traffic counters and probe vehicles to accurately estimate traffic flow and travel time in links where these measurements are unavailable. This problem is critical in transportation planning applications where the sensor coverage is low and the planned interventions have network-wide impacts. The proposed model, named the Macroscopic Traffic Estimator (MaTE), can perform network-wide estimations of traffic flow and travel time only using the set of observed measurements of these quantities. Because MaTE is grounded in macroscopic flow theory, all parameters and variables are interpretable. The estimated traffic flow satisfies fundamental flow conservation constraints and exhibits an increasing monotonic relationship with the estimated travel time. Using logit-based stochastic traffic assignment as the principle for routing flow behavior makes the model fully differentiable with respect to the model parameters. This property facilitates the application of computational graphs to learn parameters from vast amounts of spatiotemporal data. We also integrate neural networks and polynomial kernel functions to capture link flow interactions and enrich the mapping of traffic flows into travel times. MaTE also adds a destination choice model and a trip generation model that uses historical data on the number of trips generated by location. Experiments on synthetic data show that the model can accurately estimate travel time and traffic flow in out-of-sample links. Results obtained using real-world multi-source data from a large-scale transportation network suggest that MaTE outperforms data-driven benchmarks, especially in travel time estimation. The estimated parameters of MaTE are also informative about the hourly change in travel demand and supply characteristics of the transportation network.
Estimating and Mitigating the Congestion Effect of Curbside Pick-ups and Drop-offs: A Causal Inference Approach
Jun 05, 2022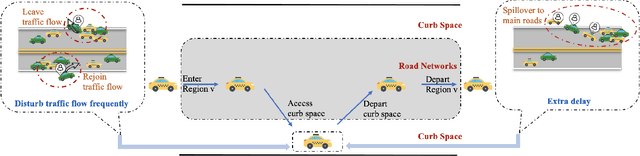

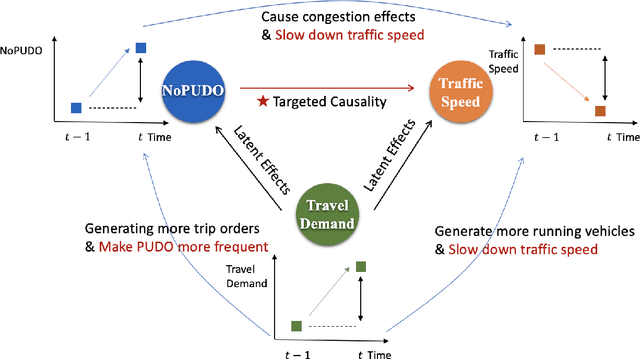
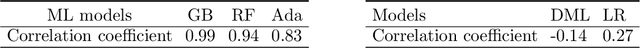
Curb space is one of the busiest areas in urban road networks. Especially in recent years, the rapid increase of ride-hailing trips and commercial deliveries has induced massive pick-ups/drop-offs (PUDOs), which occupy the limited curb space that was designed and built decades ago. These PUDOs could jam curb utilization and disturb the mainline traffic flow, evidently leading to significant societal externalities. However, there is a lack of an analytical framework that rigorously quantifies and mitigates the congestion effect of PUDOs in the system view, particularly with little data support and involvement of confounding effects. In view of this, this paper develops a rigorous causal inference approach to estimate the congestion effect of PUDOs on general networks. A causal graph is set to represent the spatio-temporal relationship between PUDOs and traffic speed, and a double and separated machine learning (DSML) method is proposed to quantify how PUDOs affect traffic congestion. Additionally, a re-routing formulation is developed and solved to encourage passenger walking and traffic flow re-routing to achieve system optimal. Numerical experiments are conducted using real-world data in the Manhattan area. On average, 100 additional units of PUDOs in a region could reduce the traffic speed by 3.70 and 4.54 mph on weekdays and weekends, respectively. Re-routing trips with PUDOs on curbs could respectively reduce the system-wide total travel time by 2.44\% and 2.12\% in Midtown and Central Park on weekdays. Sensitivity analysis is also conducted to demonstrate the effectiveness and robustness of the proposed framework.
Statistical inference of travelers' route choice preferences with system-level data
Apr 23, 2022
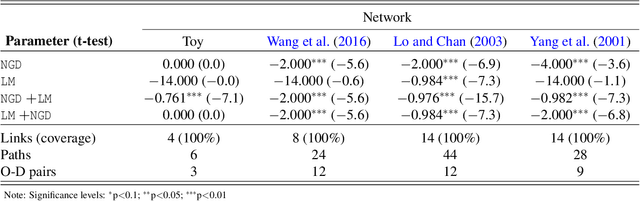
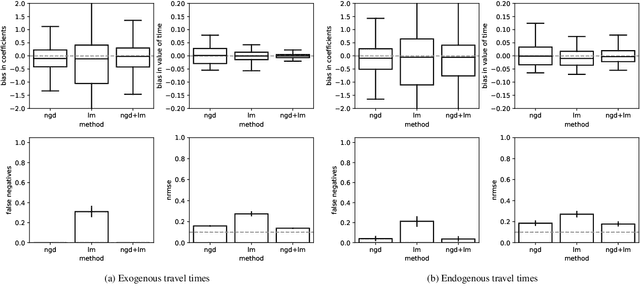
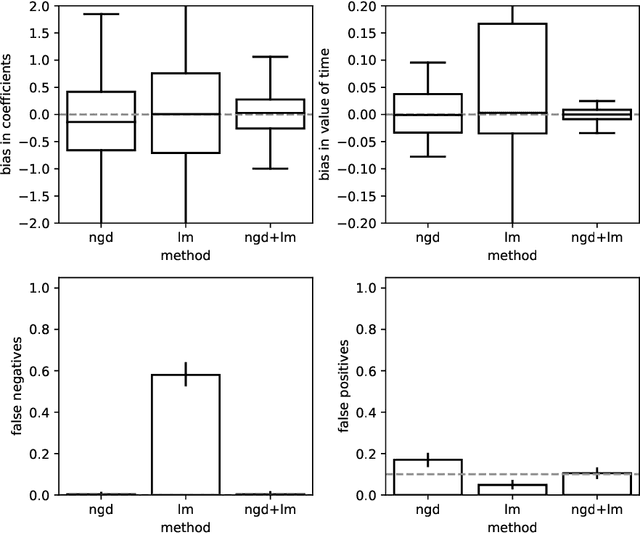
Traditional network models encapsulate travel behavior among all origin-destination pairs based on a simplified and generic utility function. Typically, the utility function consists of travel time solely and its coefficients are equated to estimates obtained from stated preference data. While this modeling strategy is reasonable, the inherent sampling bias in individual-level data may be further amplified over network flow aggregation, leading to inaccurate flow estimates. This data must be collected from surveys or travel diaries, which may be labor intensive, costly and limited to a small time period. To address these limitations, this study extends classical bi-level formulations to estimate travelers' utility functions with multiple attributes using system-level data. We formulate a methodology grounded on non-linear least squares to statistically infer travelers' utility function in the network context using traffic counts, traffic speeds, traffic incidents and sociodemographic information, among other attributes. The analysis of the mathematical properties of the optimization problem and of its pseudo-convexity motivate the use of normalized gradient descent. We also develop a hypothesis test framework to examine statistical properties of the utility function coefficients and to perform attributes selection. Experiments on synthetic data show that the coefficients are consistently recovered and that hypothesis tests are a reliable statistic to identify which attributes are determinants of travelers' route choices. Besides, a series of Monte-Carlo experiments suggest that statistical inference is robust to noise in the Origin-Destination matrix and in the traffic counts, and to various levels of sensor coverage. The methodology is also deployed at a large scale using real-world multi-source data in Fresno, CA collected before and during the COVID-19 outbreak.
From Twitter to Traffic Predictor: Next-Day Morning Traffic Prediction Using Social Media Data
Sep 29, 2020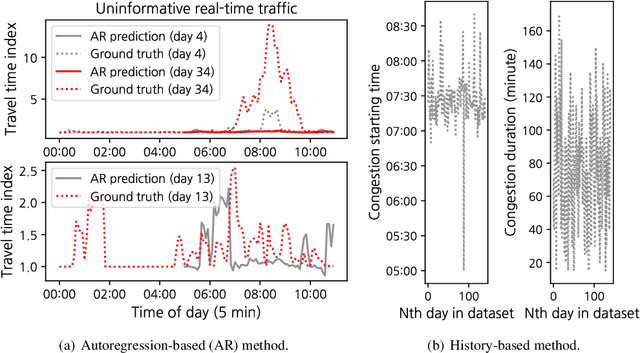



The effectiveness of traditional traffic prediction methods is often extremely limited when forecasting traffic dynamics in early morning. The reason is that traffic can break down drastically during the early morning commute, and the time and duration of this break-down vary substantially from day to day. Early morning traffic forecast is crucial to inform morning-commute traffic management, but they are generally challenging to predict in advance, particularly by midnight. In this paper, we propose to mine Twitter messages as a probing method to understand the impacts of people's work and rest patterns in the evening/midnight of the previous day to the next-day morning traffic. The model is tested on freeway networks in Pittsburgh as experiments. The resulting relationship is surprisingly simple and powerful. We find that, in general, the earlier people rest as indicated from Tweets, the more congested roads will be in the next morning. The occurrence of big events in the evening before, represented by higher or lower tweet sentiment than normal, often implies lower travel demand in the next morning than normal days. Besides, people's tweeting activities in the night before and early morning are statistically associated with congestion in morning peak hours. We make use of such relationships to build a predictive framework which forecasts morning commute congestion using people's tweeting profiles extracted by 5 am or as late as the midnight prior to the morning. The Pittsburgh study supports that our framework can precisely predict morning congestion, particularly for some road segments upstream of roadway bottlenecks with large day-to-day congestion variation. Our approach considerably outperforms those existing methods without Twitter message features, and it can learn meaningful representation of demand from tweeting profiles that offer managerial insights.
Learning to Recommend Signal Plans under Incidents with Real-Time Traffic Prediction
May 21, 2020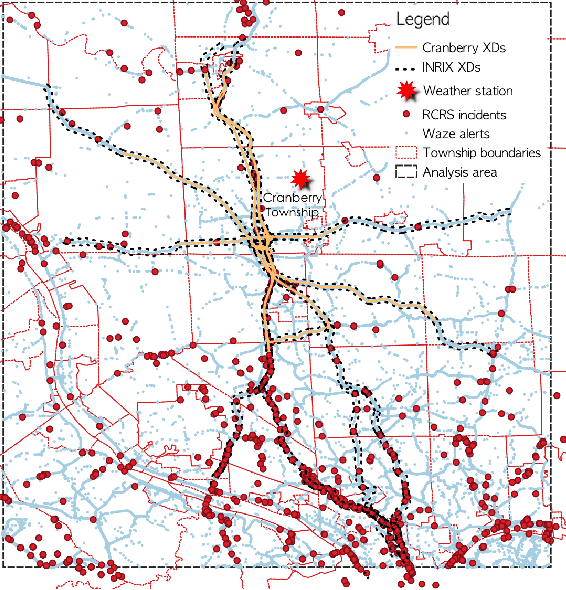
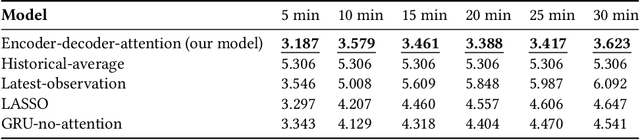
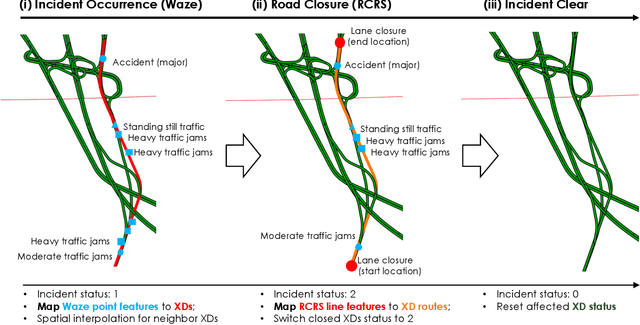
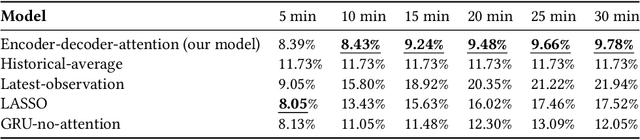
The main question to address in this paper is to recommend optimal signal timing plans in real time under incidents by incorporating domain knowledge developed with the traffic signal timing plans tuned for possible incidents, and learning from historical data of both traffic and implemented signals timing. The effectiveness of traffic incident management is often limited by the late response time and excessive workload of traffic operators. This paper proposes a novel decision-making framework that learns from both data and domain knowledge to real-time recommend contingency signal plans that accommodate non-recurrent traffic, with the outputs from real-time traffic prediction at least 30 minutes in advance. Specifically, considering the rare occurrences of engagement of contingency signal plans for incidents, we propose to decompose the end-to-end recommendation task into two hierarchical models: real-time traffic prediction and plan association. We learn the connections between the two models through metric learning, which reinforces partial-order preferences observed from historical signal engagement records. We demonstrate the effectiveness of our approach by testing this framework on the traffic network in Cranberry Township in 2019. Results show that our recommendation system has a precision score of 96.75% and recall of 87.5% on the testing plan, and make recommendation of an average of 22.5 minutes lead time ahead of Waze alerts. The results suggest that our framework is capable of giving traffic operators a significant time window to access the conditions and respond appropriately.
High-Resolution Traffic Sensing with Autonomous Vehicles
Oct 06, 2019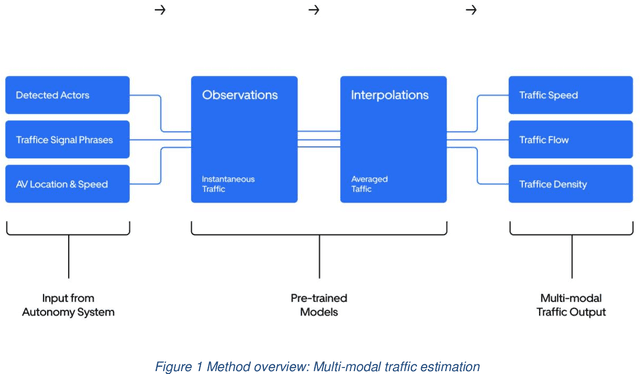
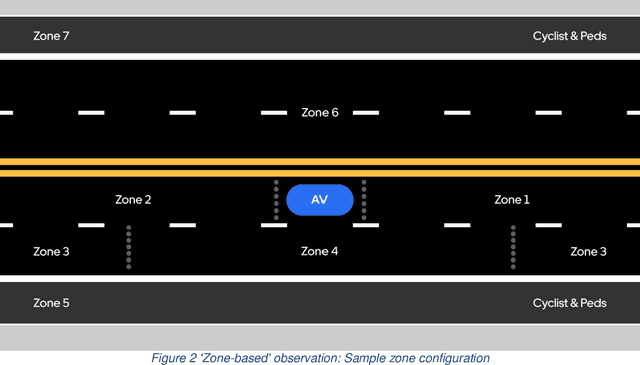
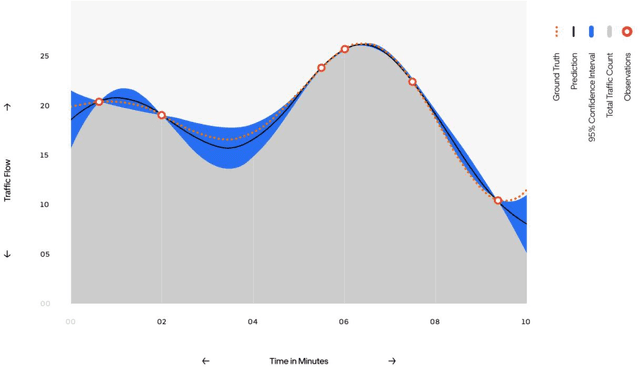
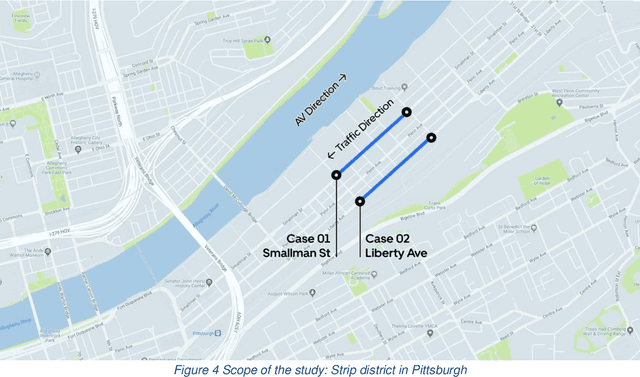
The last decades have witnessed the breakthrough of autonomous vehicles (AVs), and the perception capabilities of AVs have been dramatically improved. Various sensors installed on AVs, including, but are not limited to, LiDAR, radar, camera and stereovision, will be collecting massive data and perceiving the surrounding traffic states continuously. In fact, a fleet of AVs can serve as floating (or probe) sensors, which can be utilized to infer traffic information while cruising around the roadway networks. In contrast, conventional traffic sensing methods rely on fixed traffic sensors such as loop detectors, cameras and microwave vehicle detectors. Due to the high cost of conventional traffic sensors, traffic state data are usually obtained in a low-frequency and sparse manner. In view of this, this paper leverages rich data collected through AVs to propose the high-resolution traffic sensing framework. The proposed framework estimates the fundamental traffic state variables, namely, flow, density and speed in high spatio-temporal resolution, and it is developed under different levels of AV perception capabilities and low AV market penetration rate. The Next Generation Simulation (NGSIM) data is adopted to examine the accuracy and robustness of the proposed framework. Experimental results show that the proposed estimation framework achieves high accuracy even with low AV market penetration rate. Sensitivity analysis regarding AV penetration rate, sensor configuration, and perception accuracy will also be studied. This study will help policymakers and private sectors (e.g Uber, Waymo) to understand the values of AVs, especially the values of massive data collected by AVs, in traffic operation and management.