 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROSE: Revolutionizing Open-Set Dense Segmentation with Patch-Wise Perceptual Large Multimodal Model
Nov 29, 2024
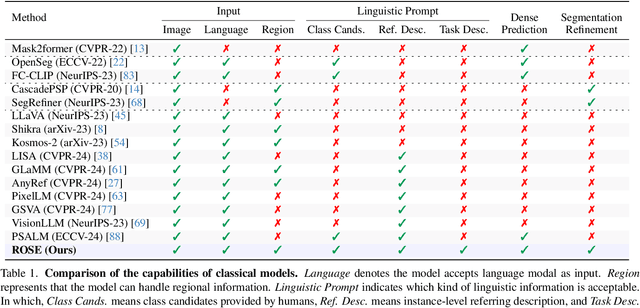
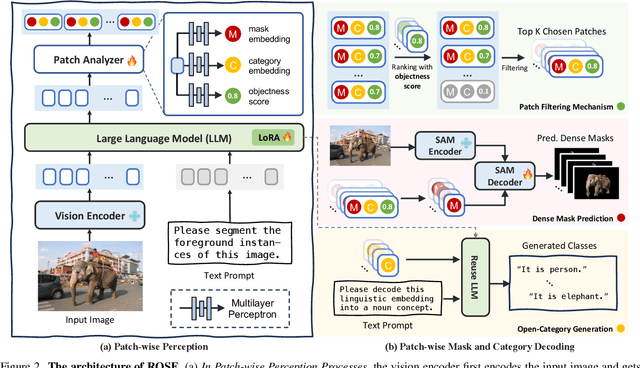
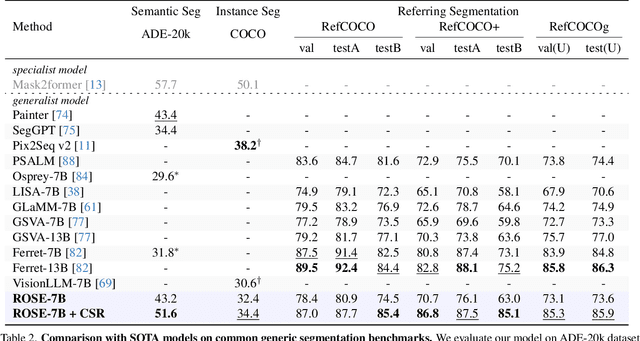
Advances in CLIP and large multimodal models (LMMs) have enabled open-vocabulary and free-text segmentation, yet existing models still require predefined category prompts, limiting free-form category self-generation. Most segmentation LMMs also remain confined to sparse predictions, restricting their applicability in open-set environments. In contrast, we propose ROSE, a Revolutionary Open-set dense SEgmentation LMM, which enables dense mask prediction and open-category generation through patch-wise perception. Our method treats each image patch as an independent region of interest candidate, enabling the model to predict both dense and sparse masks simultaneously. Additionally, a newly designed instruction-response paradigm takes full advantage of the generation and generalization capabilities of LMMs, achieving category prediction independent of closed-set constraints or predefined categories. To further enhance mask detail and category precision, we introduce a conversation-based refinement paradigm, integrating the prediction result from previous step with textual prompt for revision. Extensive experiments demonstrate that ROSE achieves competitive performance across various segmentation tasks in a unified framework. Code will be released.
Global Knowledge Calibration for Fast Open-Vocabulary Segmentation
Mar 16, 2023Recent advancements in pre-trained vision-language models, such as CLIP, have enabled the segmentation of arbitrary concepts solely from textual inputs, a process commonly referred to as open-vocabulary semantic segmentation (OVS). However, existing OVS techniques confront a fundamental challenge: the trained classifier tends to overfit on the base classes observed during training, resulting in suboptimal generalization performance to unseen classes. To mitigate this issue, recent studies have proposed the use of an additional frozen pre-trained CLIP for classification. Nonetheless, this approach incurs heavy computational overheads as the CLIP vision encoder must be repeatedly forward-passed for each mask, rendering it impractical for real-world applications. To address this challenge, our objective is to develop a fast OVS model that can perform comparably or better without the extra computational burden of the CLIP image encoder during inference. To this end, we propose a core idea of preserving the generalizable representation when fine-tuning on known classes. Specifically, we introduce a text diversification strategy that generates a set of synonyms for each training category, which prevents the learned representation from collapsing onto specific known category names. Additionally, we employ a text-guided knowledge distillation method to preserve the generalizable knowledge of CLIP. Extensive experiments demonstrate that our proposed model achieves robust generalization performance across various datasets. Furthermore, we perform a preliminary exploration of open-vocabulary video segmentation and present a benchmark that can facilitate future open-vocabulary research in the video domain.