 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Semi-Siamese Training for Long-tail and Shallow Face Learning
Paper and Code
May 10, 2021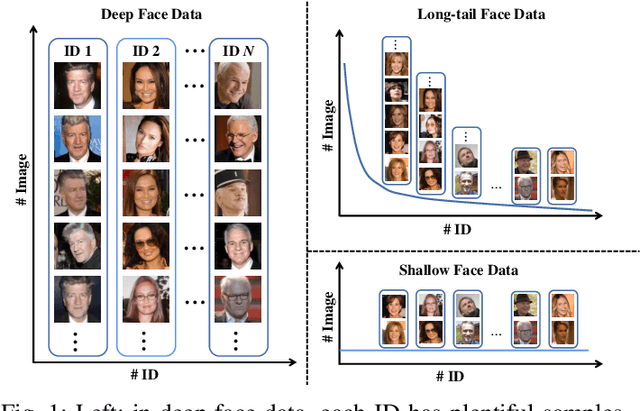
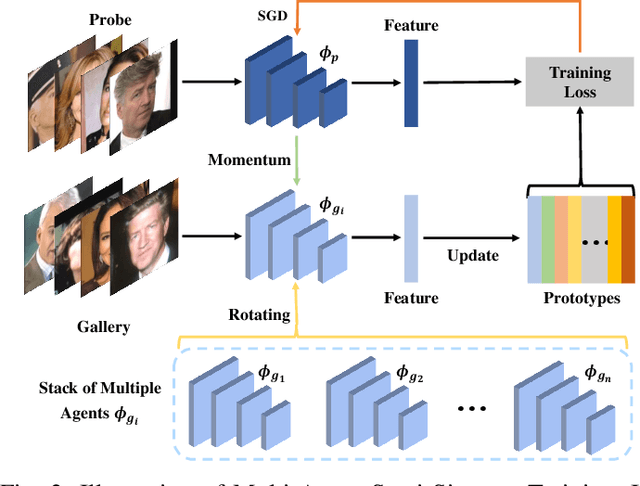
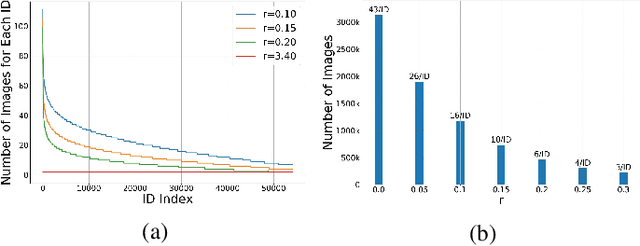
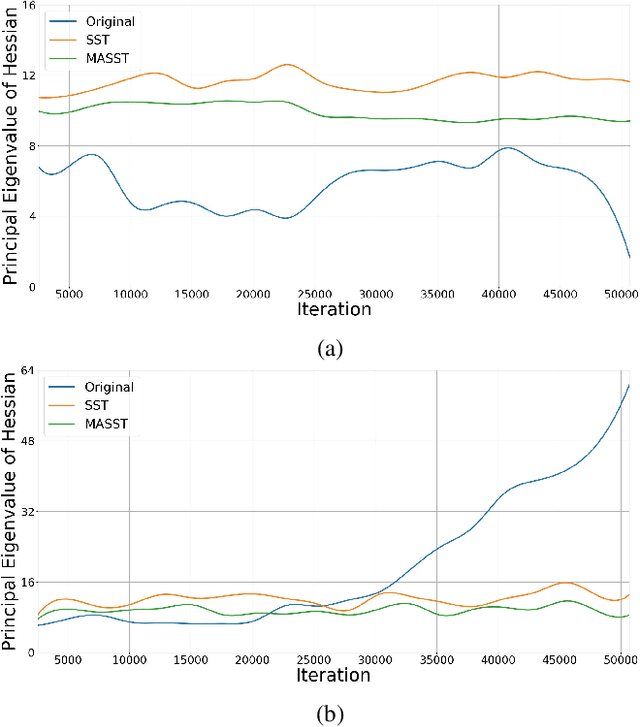
With the recent development of deep convolutional neural networks and large-scale datasets, deep face recognition has made remarkable progress and been widely used in various applications. However, unlike the existing public face datasets, in many real-world scenarios of face recognition, the depth of training dataset is shallow, which means only two face images are available for each ID. With the non-uniform increase of samples, such issue is converted to a more general case, a.k.a long-tail face learning, which suffers from data imbalance and intra-class diversity dearth simultaneously. These adverse conditions damage the training and result in the decline of model performance. Based on the Semi-Siamese Training (SST), we introduce an advanced solution, named Multi-Agent Semi-Siamese Training (MASST), to address these problems. MASST includes a probe network and multiple gallery agents, the former aims to encode the probe features, and the latter constitutes a stack of networks that encode the prototypes (gallery features). For each training iteration, the gallery network, which is sequentially rotated from the stack, and the probe network form a pair of semi-siamese networks. We give theoretical and empirical analysis that, given the long-tail (or shallow) data and training loss, MASST smooths the loss landscape and satisfies the Lipschitz continuity with the help of multiple agents and the updating gallery queue. The proposed method is out of extra-dependency, thus can be easily integrated with the existing loss functions and network architectures. It is worth noting that, although multiple gallery agents are employed for training, only the probe network is needed for inference, without increasing the inference cost. Extensive experiments and comparisons demonstrate the advantages of MASST for long-tail and shallow face learning.